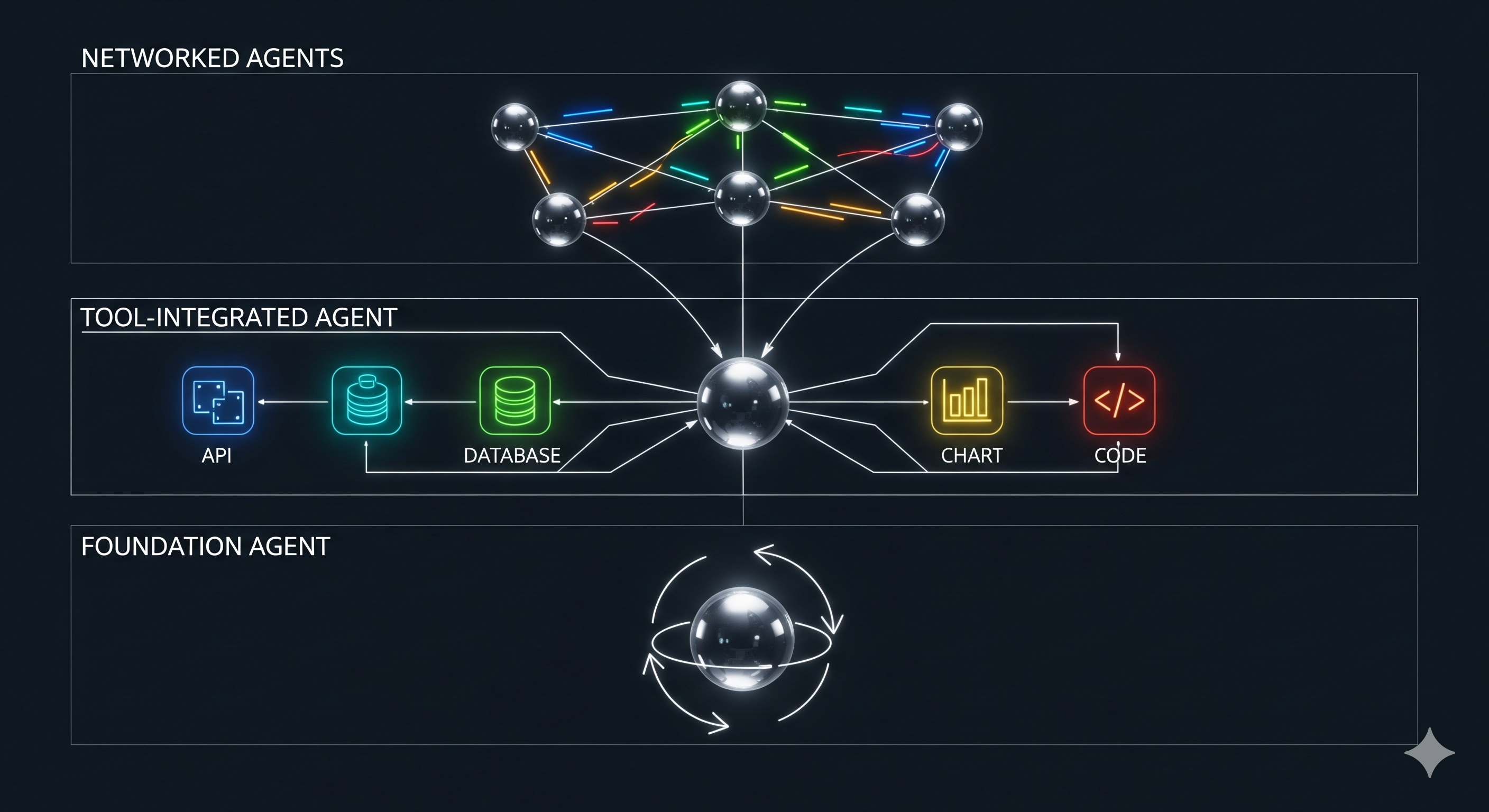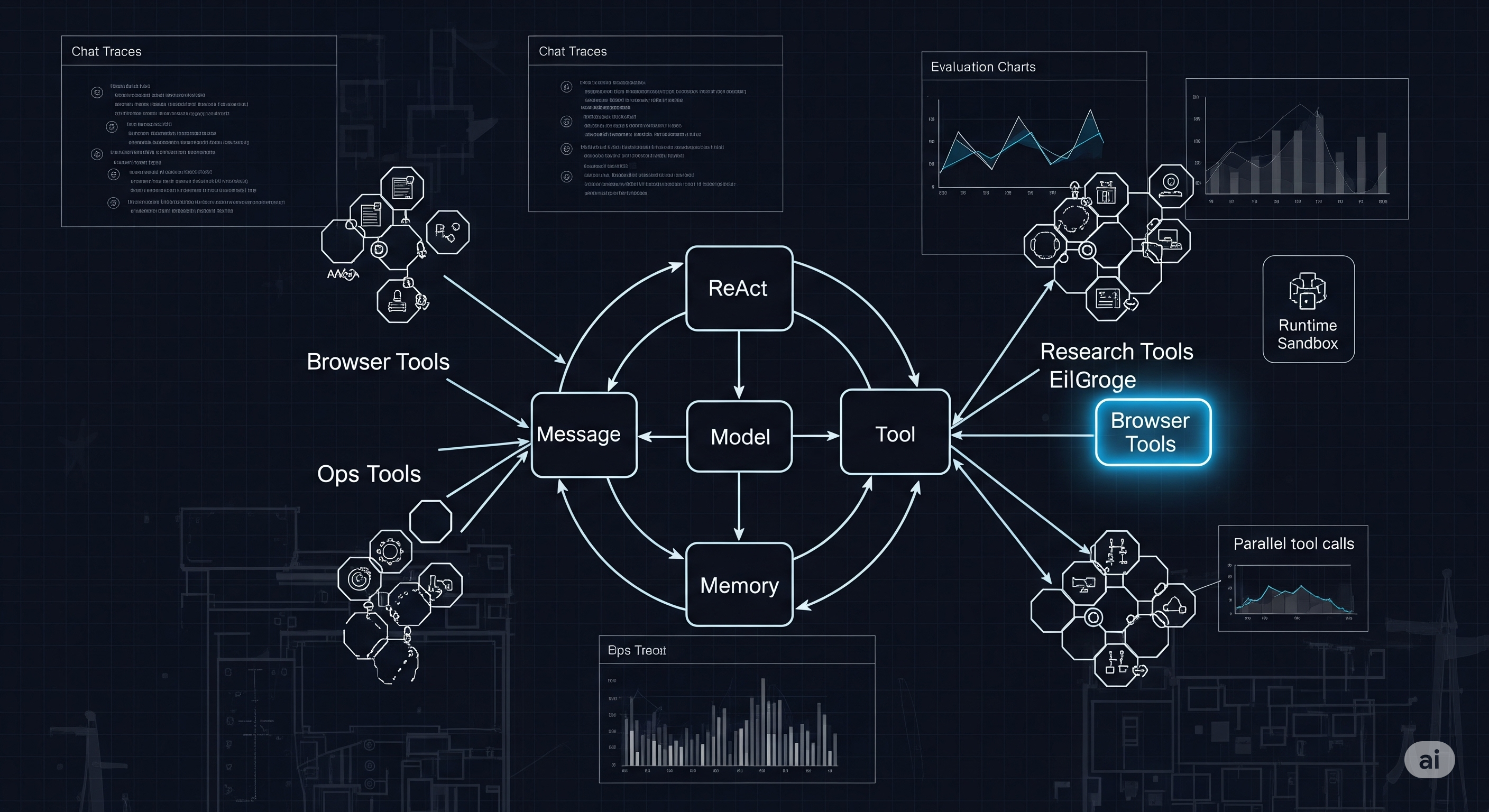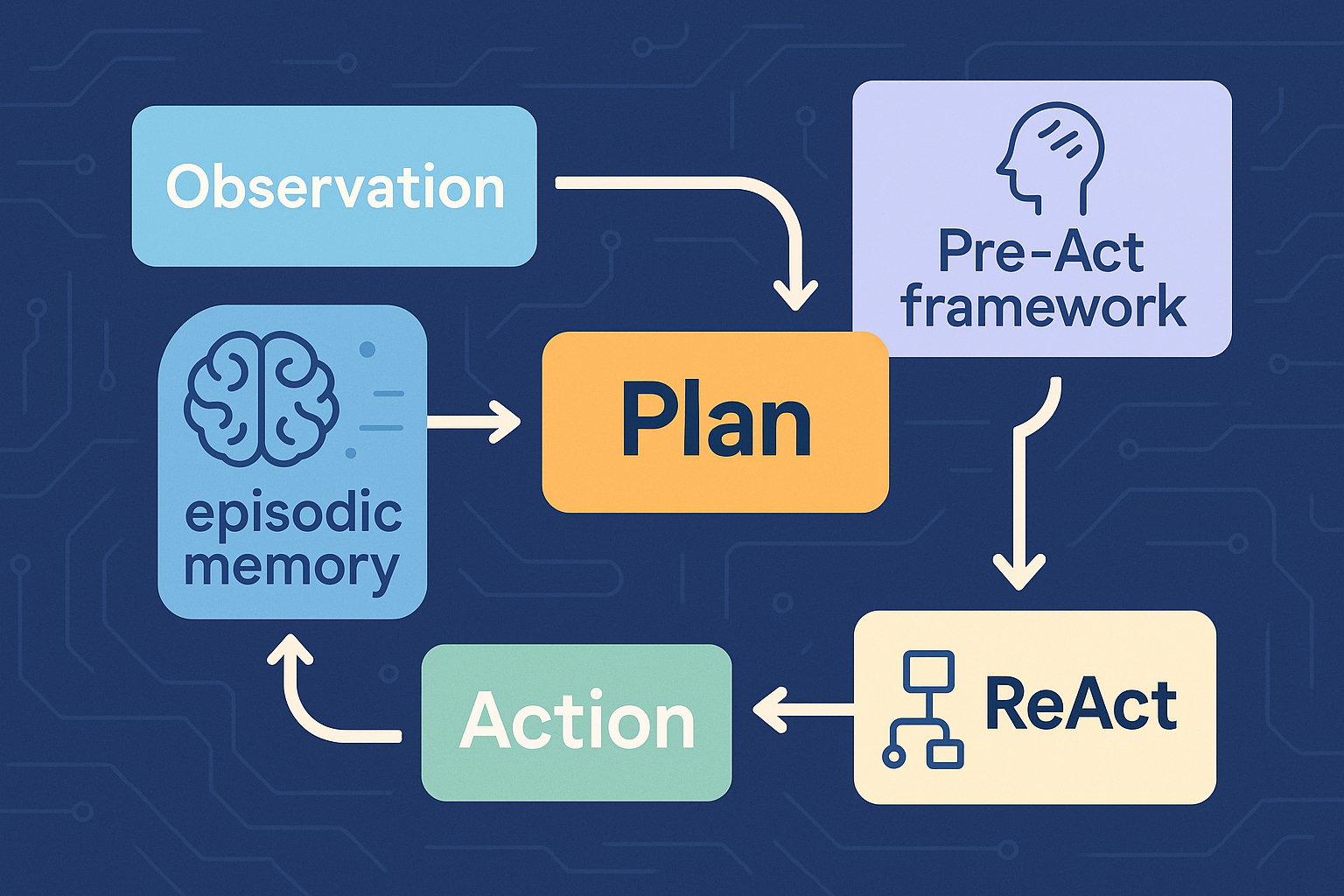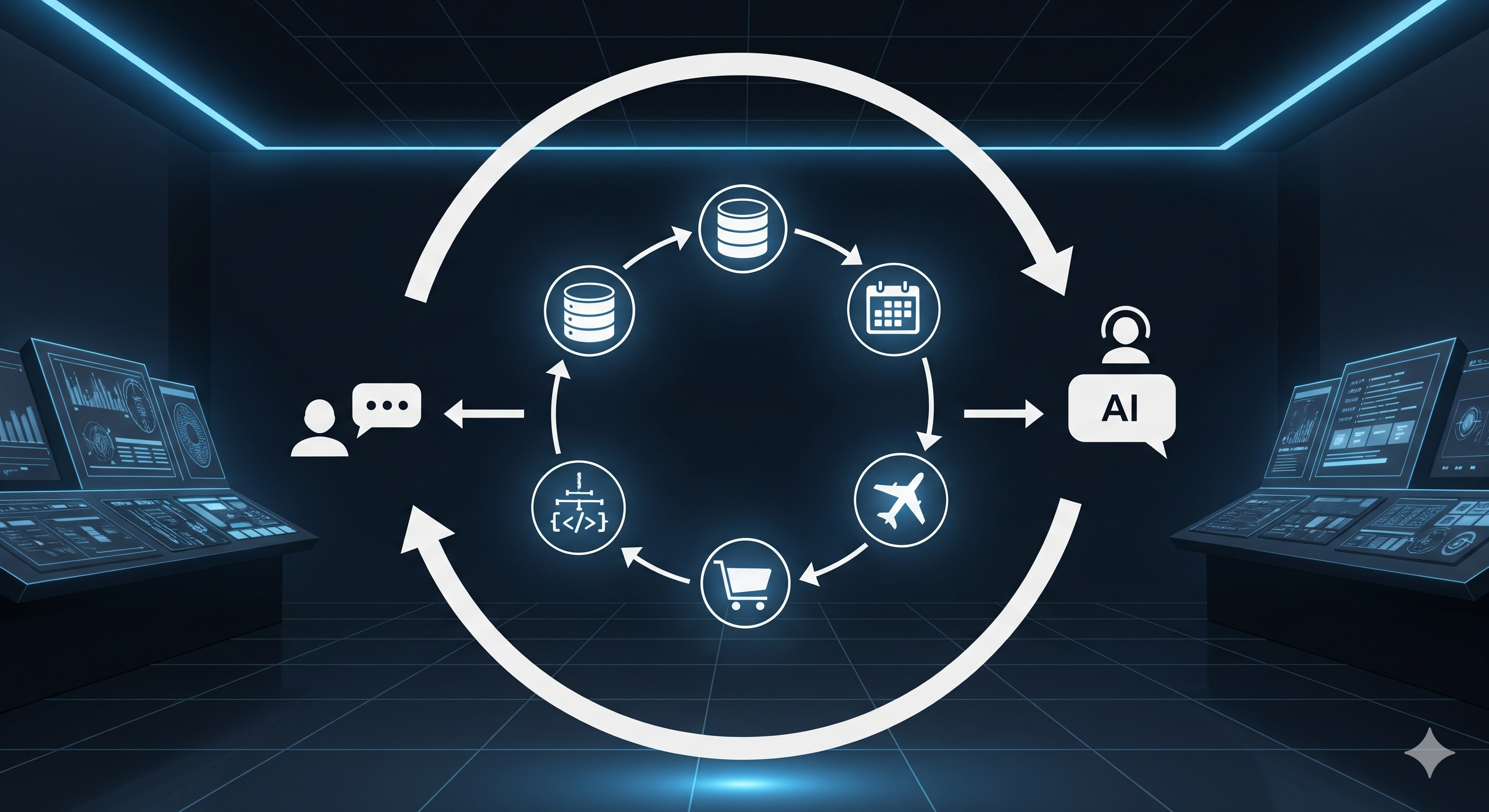
Talk, Tool, Triumph: Training Agents with Real Conversations
TL;DR Most “tool‑using” LLMs still practice in sterile gyms. MUA‑RL moves training into the messy real world by adding an LLM‑simulated user inside the RL rollout, wiring the agent to call actual tools and rewarding it only when the end task is truly done. The result: smaller open models close in on or beat bigger names on multi‑turn benchmarks, while learning crisper, policy‑compliant dialogue habits. Why this matters now Enterprises don’t want chatty copilots; they want agents that finish jobs: modify an order under policy, update a ticket with verified fields, push a fix to a repo, or reconcile an invoice—often across several conversational turns and multiple tools. Supervised fine‑tuning on synthetic traces helps, but it often overfits to static scripts and misses the live back‑and‑forth where users change their minds, add constraints, or misunderstand policy. ...