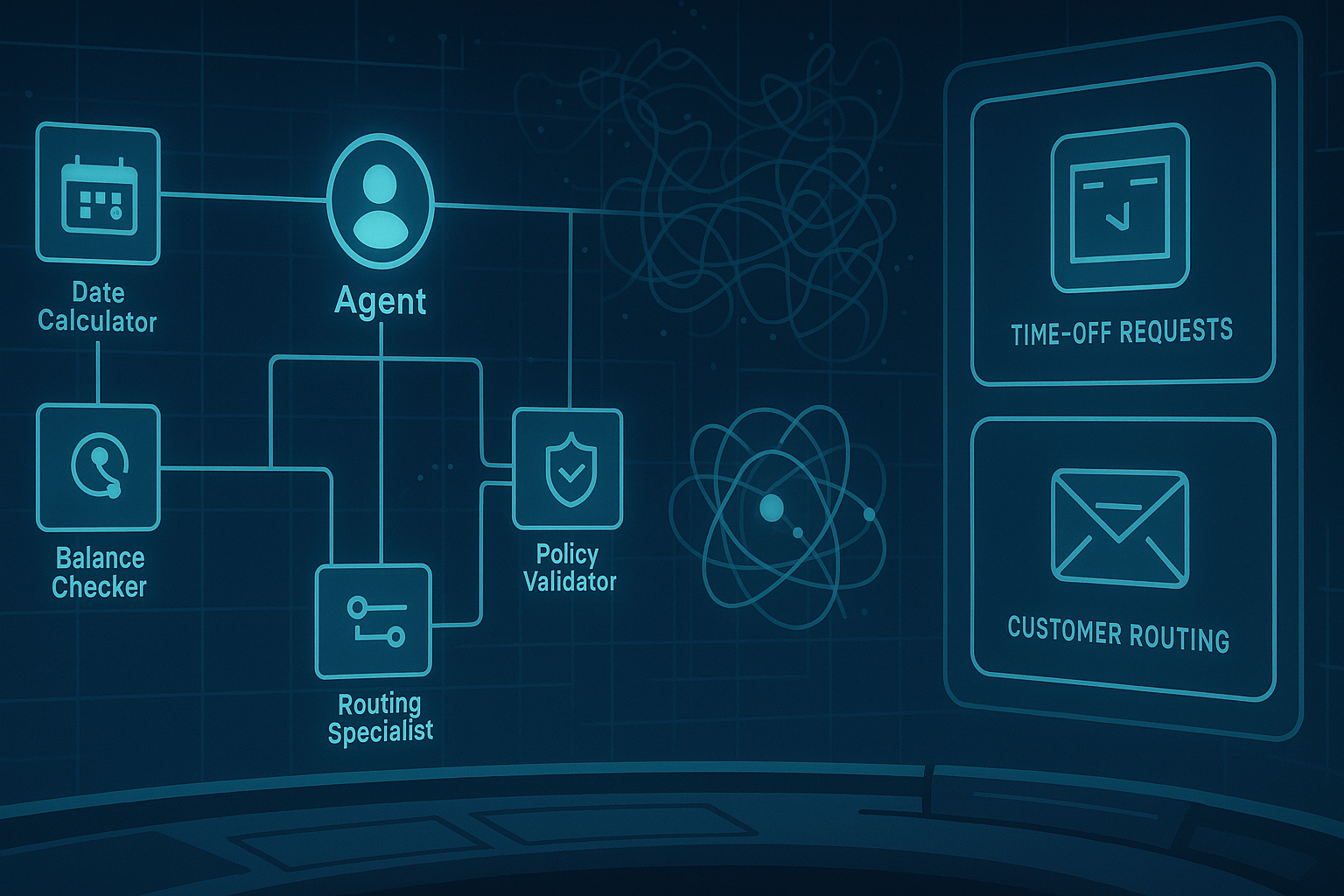
Stop the All-Hands Meeting: When AI Agents Learn Who Actually Needs to Talk
Opening — Why this matters now Multi-agent LLM systems are having their moment. From coding copilots to autonomous research teams, the industry has embraced the idea that many models thinking together outperform a single, monolithic brain. Yet most agent frameworks still suffer from a familiar corporate disease: everyone talks to everyone, all the time. ...