MobileDreamer: When GUI Agents Stop Guessing and Start Imagining
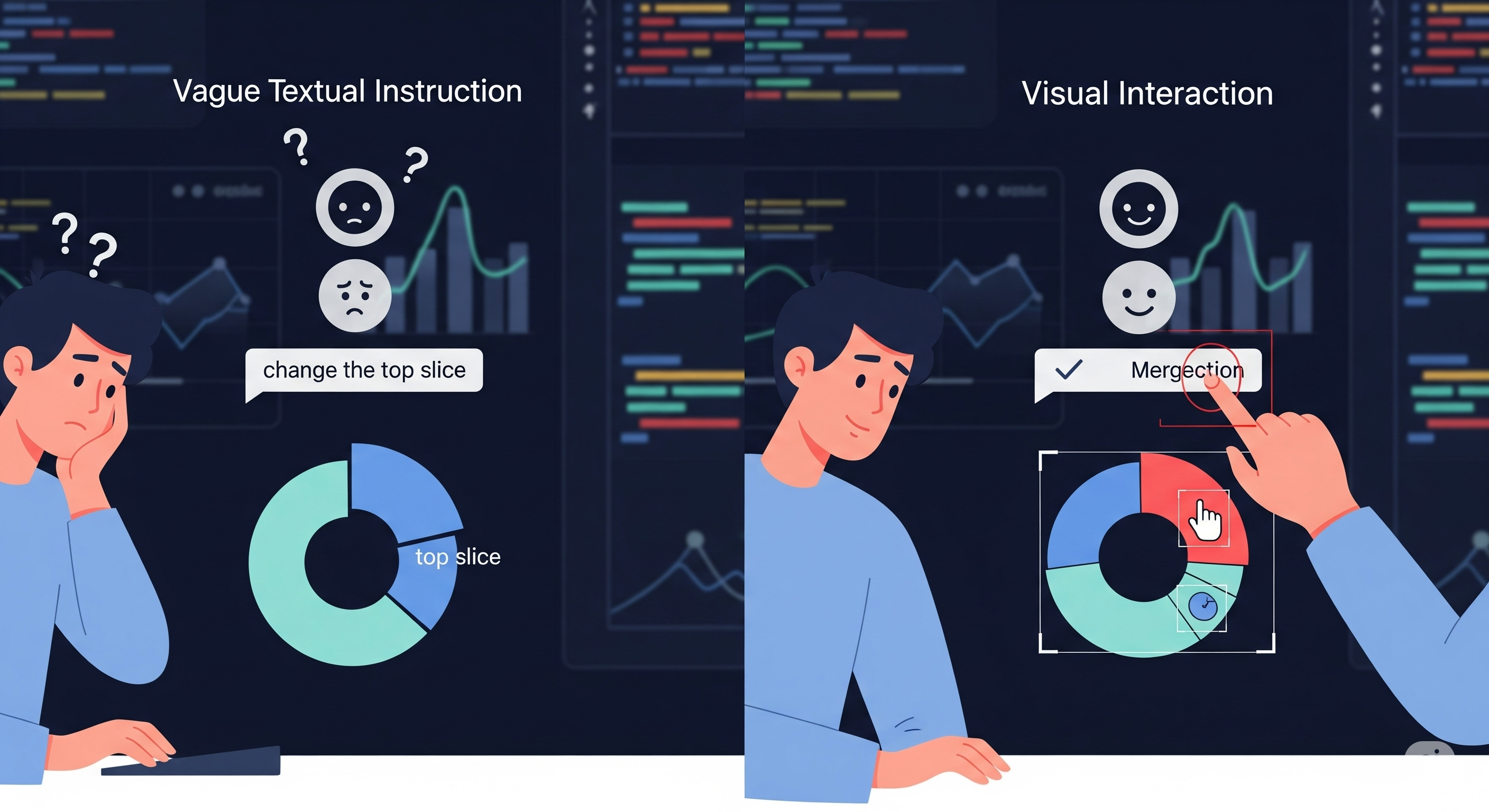
Opening — Why this matters now GUI agents are everywhere in demos and nowhere in production. They click, scroll, and type impressively—right up until the task requires foresight. The moment an interface branches, refreshes, or hides its intent behind two more screens, today’s agents revert to trial-and-error behavior. The core problem isn’t vision. It’s imagination. ...