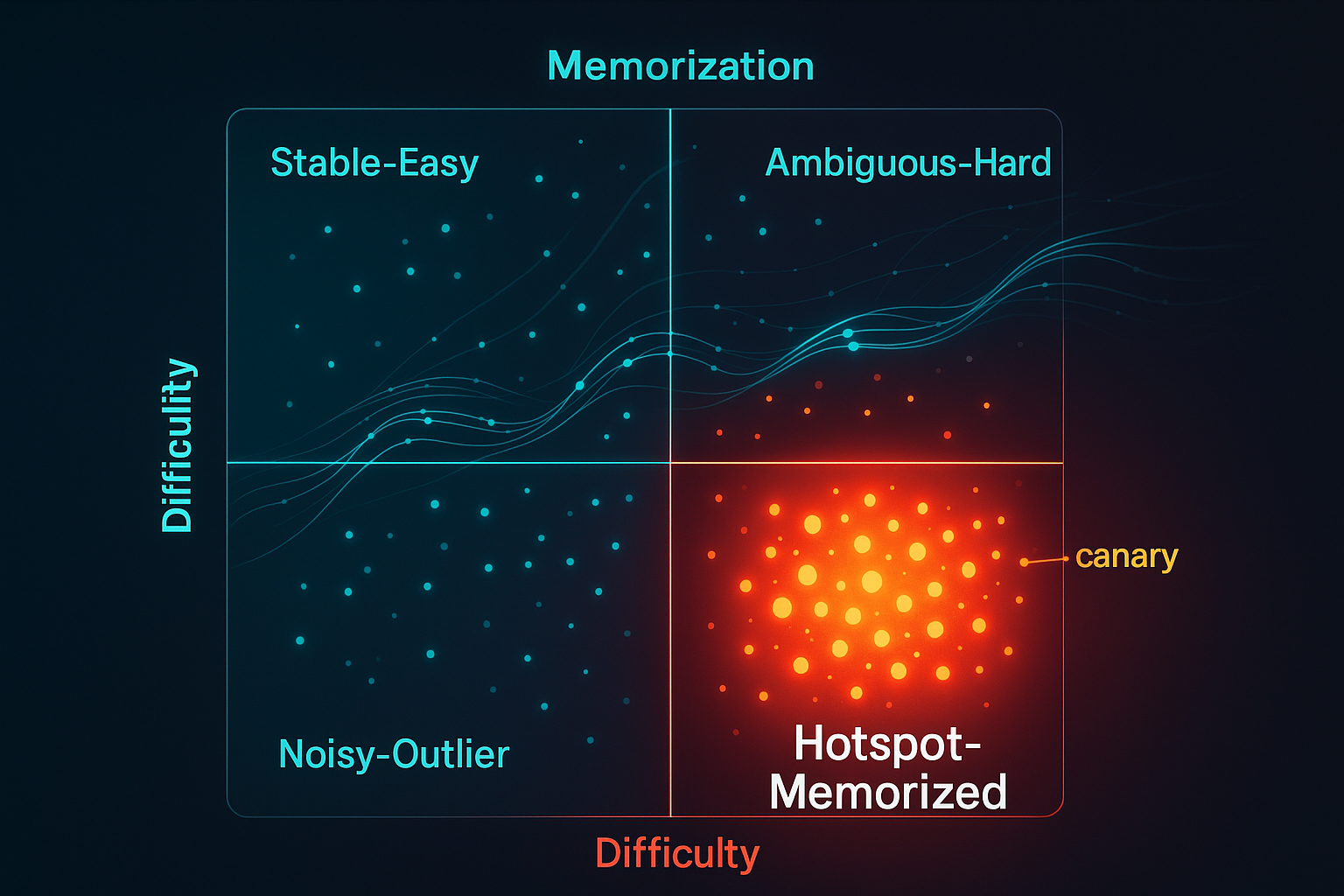
When Models Start to Forget: The Hidden Cost of Training LLMs Too Well
Opening — Why this matters now Large language models are getting better at everything that looks like intelligence — fluency, reasoning, instruction following. But beneath that progress, a quieter phenomenon is taking shape: models are remembering too much. The paper examined in this article does not frame memorization as a moral panic or a privacy scandal. Instead, it treats memorization as a structural side-effect of modern LLM training pipelines — something that emerges naturally once scale, optimization pressure, and data reuse collide. ...