TL;DR for operators
Training data does not become risky only after a model has memorised it. It often leaves signals while training is still happening.
That is the useful idea behind Generative Data Cartography, or GenDataCarto: track how each pretraining sample behaves during early training, then use that behaviour to decide which data should be kept, up-sampled, down-weighted, or removed.1 The method uses two signals. The first is early loss, which approximates how difficult a sample is. The second is the frequency of “forget events”, where a sample appears learned and later becomes poorly fitted again. In the paper’s framing, frequent forget events are not just training noise. They are a warning that a sample may be unusually influential, repeatedly re-entering the model’s attention like a guest who refuses to leave the meeting.
The business interpretation is straightforward: per-sample training traces become an audit layer. A team can identify memorization hotspots before final deployment, intervene surgically, and then measure whether leakage risk drops without damaging model quality too much. In the paper’s experiments, pruning the top 5% highest-memorization samples in a synthetic canary setting reduces canary extraction success from 100% to 40%, with a 0.5% perplexity increase. In a GPT-2 Small experiment on Wikitext-103 with injected canaries, down-weighting hotspot samples reduces benchmark leakage by 30% and membership-inference AUC by 15%, with less than 1% perplexity increase.
That is promising. It is not a universal privacy certificate. The evidence is controlled and relatively small-scale: synthetic canaries, a small LSTM, and GPT-2 Small trained for three epochs on Wikitext-103. The theoretical claims rest on stability, smoothness, and convexity assumptions that are useful for reasoning but not a perfect mirror of frontier-model training. Treat GenDataCarto as a triage method for data governance, not as a ceremonial spell against memorization. The spell budget in AI is already over-allocated.
The leak starts before the leak
Most organisations think about memorization after the model misbehaves. A model regurgitates a private sequence. A benchmark score looks suspiciously good. A red-team test extracts a phrase that should never have been in production output. Then everyone discovers, with the usual corporate theatre, that the dataset was “large and heterogeneous”.
The paper’s sharper point is that this is the wrong moment to start looking. Memorization is not merely a model-output event. It is a training-dynamics event. Some examples become high-risk because of how the model learns, forgets, and re-learns them.
That distinction matters. If memorization is treated as a model-architecture problem, the default response is to modify the model, add privacy-preserving optimisation, or install a post-hoc output filter. Those may be necessary in some settings. But they are also blunt, expensive, and sometimes awkwardly detached from the actual source of the problem: specific pieces of data that behave badly under training.
GenDataCarto shifts the question from “how do we make the model less leaky?” to “which samples are creating the conditions for leakage?” That sounds less glamorous. Excellent. Glamour is a terrible data-governance strategy.
GenDataCarto turns training traces into a map
The mechanism is deliberately simple.
During an initial burn-in period, the training loop records per-sample losses across epochs. This produces an epoch-by-sample loss matrix. From that matrix, GenDataCarto computes two scores for every example.
The first score is difficulty. It is the mean per-sample loss over the burn-in window. If the model struggles with an example early, that example has higher difficulty. This is not exotic. It is the sort of signal engineers already understand: the model finds some samples easy and others stubborn.
The second score is memorization. The paper defines this using forget events. A forget event occurs when a sample’s loss had previously fallen below a threshold, then later rises above it. In plain language: the model seemed to learn the example, then lost its grip on it, then may need to fit it again. The memorization score is the normalised count of these events across training.
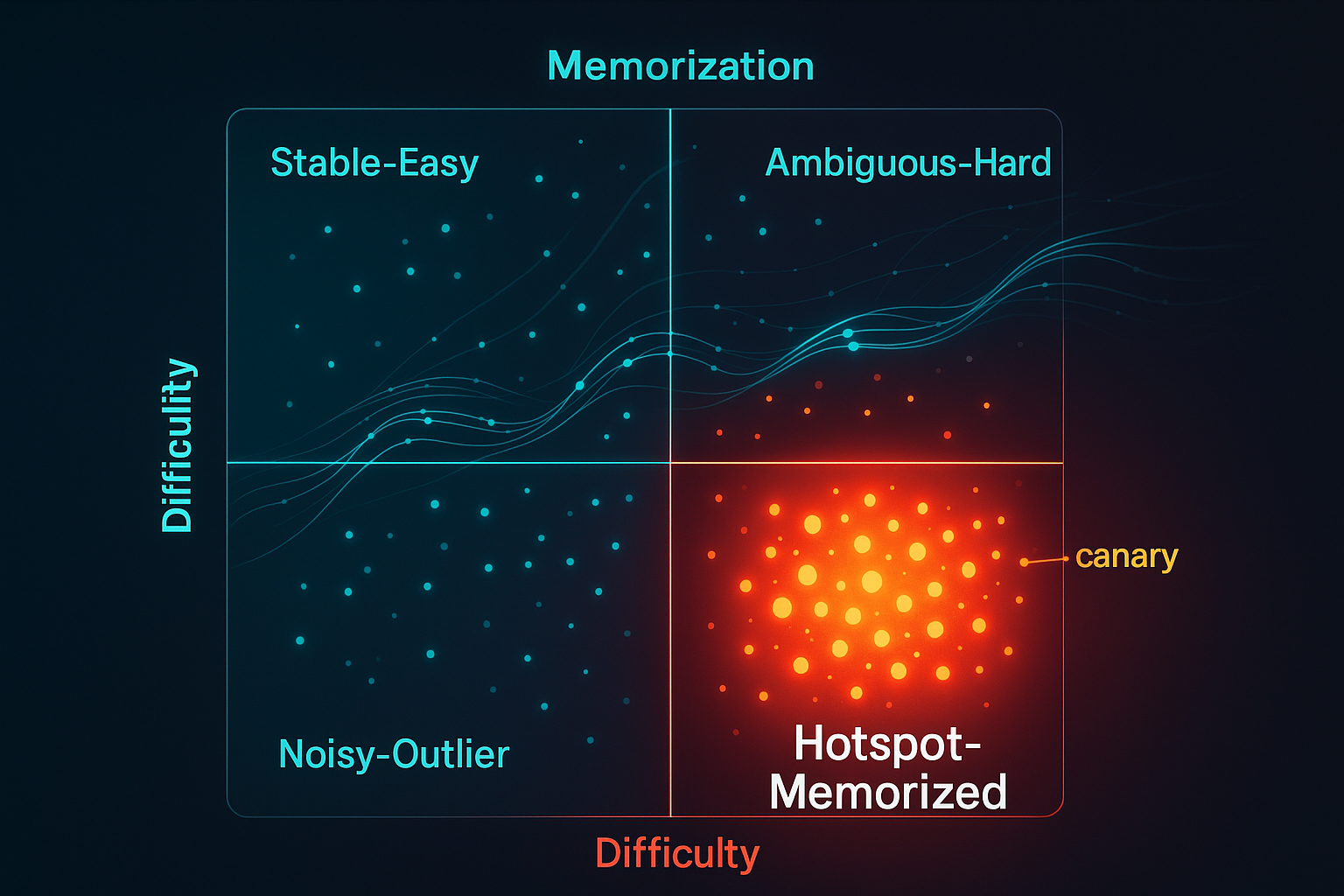
That gives each sample a coordinate: difficulty on one axis, memorization on the other.
The important move is not the scatterplot. Scatterplots have committed enough strategic crimes already. The important move is that the map becomes an intervention plan.
| Signal | What it measures | Operational reading | Why it matters |
|---|---|---|---|
| Early loss | How hard the sample is during burn-in | Difficulty | Helps separate useful hard cases from easy core patterns |
| Forget-event frequency | How often the sample becomes “unlearned” after being learned | Memorization pressure | Flags samples that may be disproportionately influential or leakage-prone |
| Quadrant label | Combination of difficulty and memorization | Data action category | Converts diagnosis into reweighting, pruning, or review |
The paper borrows the spirit of supervised data cartography but adapts it to generative pretraining, where there is no simple label-confidence story. Instead, the method watches the generative objective itself: negative log-likelihood over sequential examples.
That is the right level of pragmatism. Generative models do not need a moral essay from the dataset. They need measurable behaviour under optimisation.
The four quadrants are operating instructions
Once samples are scored, GenDataCarto partitions them into four regions using thresholds for difficulty and memorization. The paper uses percentile-style thresholds, with the difficulty threshold illustrated by a chosen percentile such as 75%. The precise setting is a tuning decision, not the main intellectual payload.
The four quadrants are the payload.
| Quadrant | Pattern | Paper interpretation | Default intervention |
|---|---|---|---|
| Stable–Easy | Low difficulty, low memorization | Well-learned core pattern | Keep, or lightly up-sample |
| Ambiguous–Hard | High difficulty, low memorization | Challenging but not repeatedly memorized | Up-sample to improve robustness on rare or hard patterns |
| Hotspot–Memorized | Low difficulty, high memorization | Easy yet repeatedly refitted | Down-weight or prune |
| Noisy–Outlier | High difficulty, high memorization | Hard and repeatedly refitted | Remove if corrupted, adversarial, private, or low-quality |
This is where the paper becomes useful for business readers.
A naive safety workflow treats risky data as a compliance category: personal data, copyrighted text, benchmark overlap, regulated records. That is necessary but incomplete. GenDataCarto adds a behavioural category: how the model interacts with each sample during training.
Those are different questions.
A sentence can look ordinary in a static data audit and still behave like a memorization hotspot. A rare contract clause, a unique medical note, a synthetic canary, or a benchmark fragment may not announce itself at ingestion. But if the model keeps learning and forgetting it, the training dynamics may reveal that the sample has unusual influence.
The result is a more operational view of data governance. The map does not merely say “this corpus contains risk”. It says “this subset is where your risk is concentrated, and here is the least destructive intervention to try first”.
That is a material improvement over the classic enterprise method of discovering problems after procurement has signed, deployment has started, and everyone suddenly remembers the word “auditability”.
The theory explains why forget events are not just noise
The paper provides two theoretical arguments. These should be read as support for the mechanism, not as a production guarantee.
The first argument uses uniform stability. In broad terms, if a learning algorithm is stable, changing or down-weighting one training example should have a bounded effect on loss. The paper argues that down-weighting high-memorization hotspot examples reduces the expected generalization gap in proportion to the total down-weighted mass, scaled by the stability parameter. The practical intuition is simple: if certain examples are contributing disproportionately to unstable generalisation behaviour, reducing their training weight should reduce the gap.
The second argument connects the memorization score to influence. Classical influence functions estimate how much a training point affects parameters or predictions, but exact influence-style computation is expensive in deep models. The paper argues that forget-event frequency can serve as a lower-bound proxy for influence under smoothness and convexity assumptions. The intuition is that a forget event implies a meaningful loss change; under smoothness, that loss change relates to gradient magnitude; accumulated across epochs, repeated forget events indicate persistent influence.
This is the mechanism-first heart of the paper:
- repeated forget events indicate unusual training dynamics;
- unusual training dynamics approximate influence;
- high-influence samples are plausible memorization and leakage hotspots;
- down-weighting or pruning those hotspots can reduce leakage with limited utility loss.
Notice what the theory does not say. It does not say every high-memorization sample is legally dangerous. It does not say every private record will have high forget frequency. It does not say a frontier LLM trained on trillions of tokens will obey a tidy convex proof because someone was polite enough to write one.
It says the signal is principled enough to deserve measurement. That is the right level of ambition.
The experiments test leakage reduction, not mystical cleanliness
The empirical section has two main experiments. They are small enough to read carefully and large enough to be useful as a proof of concept.
| Test | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| Synthetic canary extraction with a small LSTM | Main evidence for direct leakage reduction | High-memorization pruning can sharply reduce extraction of unique sequences | Does not prove the same reduction at frontier scale or across all data types |
| GPT-2 Small on Wikitext-103 with injected canaries | Main evidence for language-model pretraining relevance | Hotspot down-weighting can reduce benchmark leakage and membership-inference risk with small perplexity cost | Does not establish production-grade privacy guarantees |
| Trade-off figures for extraction success and perplexity | Evidence visualisation of intervention trade-offs | The method is meant to tune leakage reduction against quality degradation | Does not provide a universal pruning threshold |
| Stability and influence derivations | Mechanistic/theoretical support | Forget events are not arbitrary; they relate to influence and generalisation under assumptions | Does not fully characterise non-convex deep learning at scale |
| PyTorch integration and sorting overhead | Implementation detail | The approach is compatible with ordinary training loops if per-sample losses are available | Does not eliminate logging, storage, or pipeline engineering costs |
In the synthetic canary experiment, the authors train a small LSTM language model on a corpus augmented with unique canary sequences. They compute difficulty and memorization scores, then prune the top 5% highest-memorization samples. Canary extraction success drops from 100% to 40%. Perplexity increases by 0.5%.
The magnitude is worth pausing over. A 60% reduction in extraction success is not a rounding error. It suggests that high-memorization samples are not merely correlated with leakage; removing the most suspicious tail can materially change what the model regurgitates. At the same time, the perplexity cost is small in this setting, which supports the paper’s central trade-off claim: not all data contributes equally to utility, and the riskiest data may be removable without wrecking the model.
But the controlled nature of the test matters. Synthetic canaries are designed to be identifiable leakage targets. They are useful precisely because they make extraction measurable. Real corporate data is messier. Private information may be fragmented, repeated, paraphrased, or embedded inside otherwise useful documents. The canary result proves the mechanism has teeth; it does not prove the teeth bite every future risk.
The GPT-2 Small experiment is closer to the intended language-model use case. The authors train GPT-2 Small for three epochs on Wikitext-103 and inject two distinct canaries. GenDataCarto is used to identify hotspot samples, which are down-weighted by a factor of 0.5. The reported effects are a 30% reduction in benchmark leakage, measured by recall of held-out validation sequences; a 15% reduction in membership-inference AUC; and less than 1% increase in perplexity.
This second result is important because it expands the claim beyond one extraction toy setting. The method appears to affect multiple risk measures: canary-style leakage, benchmark contamination, and membership inference. That triangulation matters. Leakage risk is not one metric wearing three hats. Extraction, contamination, and membership inference each represent a different operational failure.
Still, the scale boundary is obvious. GPT-2 Small on Wikitext-103 is not a modern frontier pretraining run. The paper gives a credible mechanism and controlled evidence, not a final answer for trillion-token governance.
The business value is earlier triage
For AI teams, the most useful interpretation is not “GenDataCarto reduces canary extraction by X percent”. That is a paper result. The business value is the workflow it enables.
A practical GenDataCarto-style workflow would look like this:
| Stage | What the team does | Business function |
|---|---|---|
| Burn-in logging | Record per-sample losses during early training | Creates behavioural evidence about the corpus |
| Score computation | Compute difficulty and forget-event memorization scores | Turns training dynamics into audit signals |
| Quadrant assignment | Classify samples into stable, hard, hotspot, and outlier categories | Converts raw traces into governance actions |
| Targeted intervention | Keep, up-sample, down-weight, prune, or review samples | Reduces risk without blunt corpus deletion |
| Risk measurement | Re-test extraction, benchmark overlap, membership inference, and perplexity | Makes the utility-risk trade-off explicit |
| Documentation | Store map summaries, intervention rationale, and metric changes | Supports reproducibility, vendor review, and internal accountability |
The key word is targeted. Organisations often discuss data governance as if the only options are “use the data” or “delete the data”. That binary is comforting, dramatic, and usually operationally lazy.
GenDataCarto offers more degrees of freedom. Stable–Easy examples can stay. Ambiguous–Hard examples may deserve more attention, not less, because they may represent useful long-tail structure. Hotspot–Memorized examples can be down-weighted before they become extraction liabilities. Noisy–Outliers can be removed or routed to human review.
This has direct relevance for several business contexts.
For privacy-sensitive training, the method can prioritise records for red-team extraction tests or manual review. It will not replace privacy law, consent management, or differential privacy where those are required. But it can reduce the number of samples that deserve expensive scrutiny.
For copyright-sensitive corpora, memorization hotspots can flag content that behaves unlike generic background distribution. That does not determine legal status. A forget-event score is not a judge, though frankly it may be more consistent than some procurement policies. But it can help teams decide which content needs provenance checks.
For benchmark governance, the method provides a way to identify evaluation-like sequences that the model may have effectively internalised. The paper’s GPT-2 experiment explicitly connects the method to benchmark leakage. In business terms, this matters because contaminated evaluation is worse than useless: it creates confidence with a fake receipt.
For vendor due diligence, a buyer could ask model or dataset providers for aggregate cartography diagnostics: hotspot mass, intervention policies, leakage tests before and after down-weighting, and perplexity trade-offs. That would be more informative than yet another slide saying “responsible AI” in tasteful blue gradients.
The map changes the role of data teams
A useful side effect of this work is that it gives data teams a more active role in model safety.
In many organisations, safety controls sit downstream. The model is trained, then evaluated, filtered, red-teamed, policy-wrapped, and perhaps fine-tuned again. Data teams are asked to document sources and remove obvious prohibited material. After that, the optimisation process becomes a black box owned by model engineers.
GenDataCarto weakens that division. It says data quality is not only an ingestion property. It is also an optimisation property.
The same document can be acceptable in a static audit but problematic in training behaviour. Conversely, a hard example should not be deleted merely because it increases loss. It might be exactly the kind of long-tail pattern the model needs to learn. The difficulty-memorization split prevents the crude mistake of treating all hard data as bad data.
That distinction is valuable.
A high-difficulty, low-memorization sample may represent rare but useful structure. Up-sampling it could improve robustness. A low-difficulty, high-memorization sample is more suspicious: why is something easy being repeatedly refitted? That is the kind of pattern that deserves risk controls. A high-difficulty, high-memorization sample is even more concerning, because it may be noisy, corrupted, adversarial, or uniquely identifying.
The broader lesson is that “data quality” should not be reduced to cleanliness. Clean data can still be risky. Messy data can still be useful. The model’s learning trajectory helps separate the two.
What operators should measure before trusting the method
The paper’s implementation story is intentionally compatible with ordinary PyTorch-style training loops, assuming per-sample losses are available. That assumption is doing work. Per-sample loss logging is not free, especially at scale. It creates storage, instrumentation, and sampling-design questions.
A production team should not blindly copy the paper and call it governance. It should run a controlled intervention study.
At minimum, the team should measure four things.
First, leakage reduction. Use synthetic canaries, known sensitive sequences, memorization probes, and extraction tests. Synthetic canaries are not the whole story, but they provide a measurable baseline.
Second, membership-inference risk. The paper reports reduced membership-inference AUC in the GPT-2 Small setting. A business deployment should test whether similar reductions appear under its own attack model.
Third, utility degradation. Perplexity is a useful language-modelling metric, but it is not a business metric. Teams should also test task performance, retrieval quality, factuality, domain accuracy, and downstream user outcomes.
Fourth, distribution distortion. Aggressive pruning can remove long-tail content that is rare but valuable. This is especially important in legal, medical, financial, industrial, or multilingual settings, where rare phrases may encode the very expertise the model is supposed to preserve.
The paper’s best operational implication is not “prune 5% everywhere”. It is “draw the trade-off curve”. Extraction success, membership inference, benchmark leakage, and perplexity should be measured as intervention strength changes. The right point is the knee of the curve, not the nearest round number.
Boundaries: useful triage, not a privacy certificate
The limitations are not fatal, but they are important.
The first boundary is scale. The paper’s empirical evidence uses a small LSTM and GPT-2 Small on Wikitext-103. These are appropriate research settings for testing the mechanism. They are not proof that the same intervention will behave identically in contemporary frontier-scale pretraining.
The second boundary is data realism. Injected canaries make leakage measurable, which is good experimental design. Real leakage often involves partial memorization, paraphrase, repeated near-duplicates, private fragments, or copyrighted passages mixed into otherwise normal documents. GenDataCarto can help prioritise such risks, but it does not automatically identify legal status, consent, ownership, or confidentiality.
The third boundary is theoretical. The influence and stability arguments rely on smoothness, convexity, and uniform stability assumptions. These assumptions help explain why forget events are a plausible signal. They do not fully describe the non-convex, distributed, heavily engineered training regimes used for large foundation models.
The fourth boundary is observability. If a training pipeline cannot record or approximate per-sample losses, the method becomes harder to deploy. Sampling-based logging may help, but then the map becomes an estimate. That may still be useful, but the uncertainty should be documented.
The fifth boundary is intervention policy. Removing high-memorization samples may reduce leakage, but it can also erase rare knowledge. Down-weighting is often safer than deletion unless the content is clearly private, contaminated, corrupted, or prohibited. The map should inform human and policy decisions, not replace them.
This is the sober interpretation: GenDataCarto is a risk-ranking and intervention framework. It is not differential privacy. It is not a legal opinion. It is not a benchmark-cleanliness certificate. It is a practical way to stop treating the dataset as an inert pile of text and start treating it as a population of behaviours under training.
That alone is progress.
The Cognaptus take
The industry has spent years asking whether models memorize. GenDataCarto asks the more useful question: which training examples are teaching the model to memorize?
That reframing matters because it moves action earlier in the pipeline. Instead of waiting for output filters, red-team failures, or embarrassing benchmark surprises, teams can instrument the training run itself. They can observe per-sample loss dynamics, map difficulty against memorization, and intervene where the risk is concentrated.
The paper’s evidence is not the final word. It is too controlled, too small-scale, and too assumption-dependent for that. But the mechanism is practical enough to deserve serious attention. It gives AI teams a way to connect data curation, privacy risk, benchmark hygiene, and model utility in one measurable loop.
The best version of this idea is not a dashboard full of pretty quadrants. It is a governance habit: map before you train, intervene before you leak, and measure the trade-off before anyone starts congratulating the model for memorising the test.
As usual, the future of responsible AI may depend less on grand principles than on whether someone remembered to log the right boring numbers.
Cognaptus: Automate the Present, Incubate the Future.
-
Laksh Patel and Neel Shanbhag, “Data Cartography for Detecting Memorization Hotspots and Guiding Data Interventions in Generative Models,” arXiv:2509.00083, 2025, https://arxiv.org/abs/2509.00083. ↩︎