Circuits of Understanding: A Formal Path to Transformer Interpretability
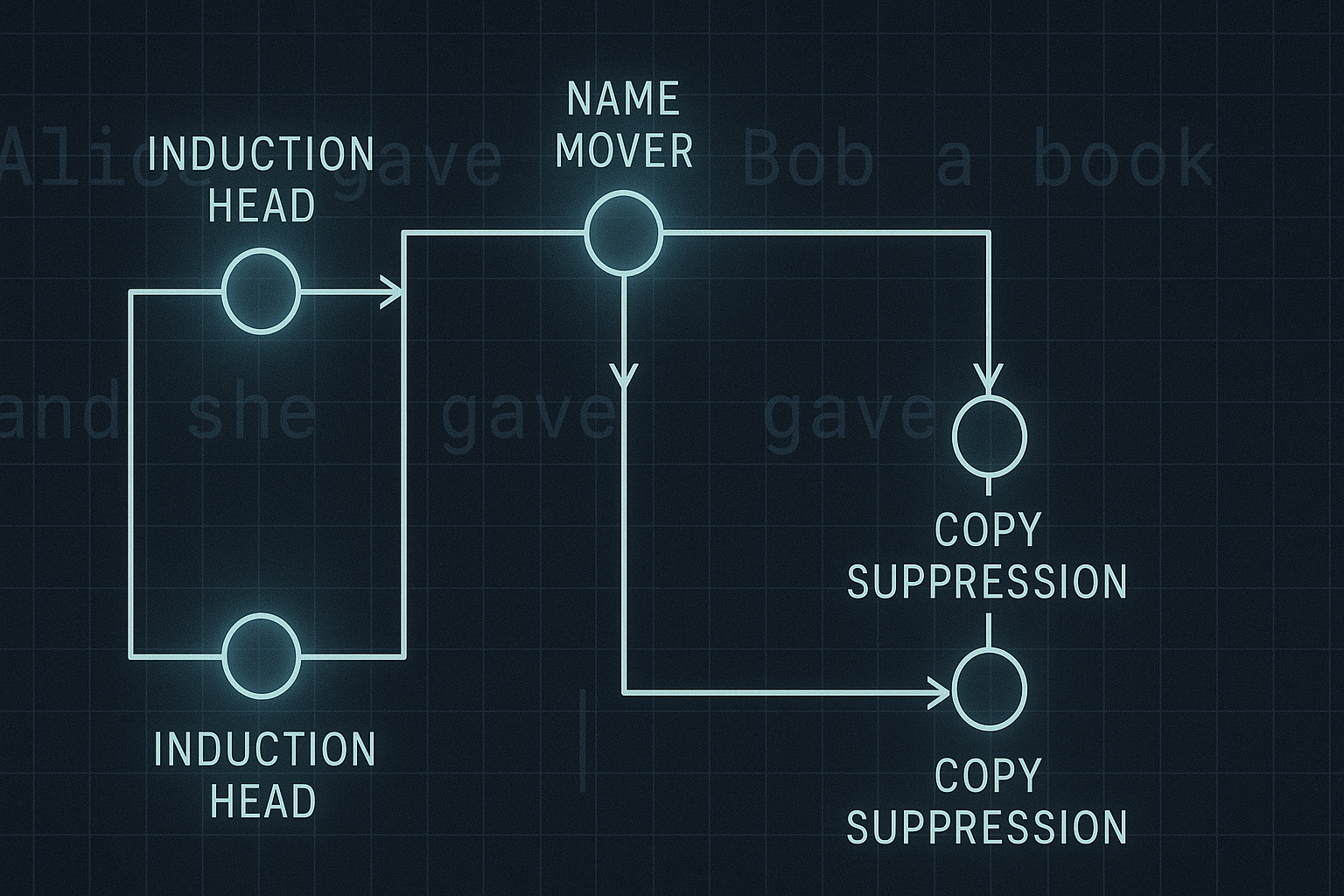
TL;DR for operators Debugging. That is the useful mental entry point, not “AI transparency,” which has become a conference badge phrase with slightly better lighting. The paper at the centre of this article, Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small, shows that a real linguistic behaviour in a transformer can be decomposed into a circuit of internal components, then tested using causal interventions rather than admired through colourful attention maps.1 The task is indirect object identification: given a sentence where two names appear and one is repeated, the model predicts the other name. Small grammar problem, large interpretability bill. ...
