USB‑C for Agents, Stress‑Tested: What MCP‑Universe Really Reveals
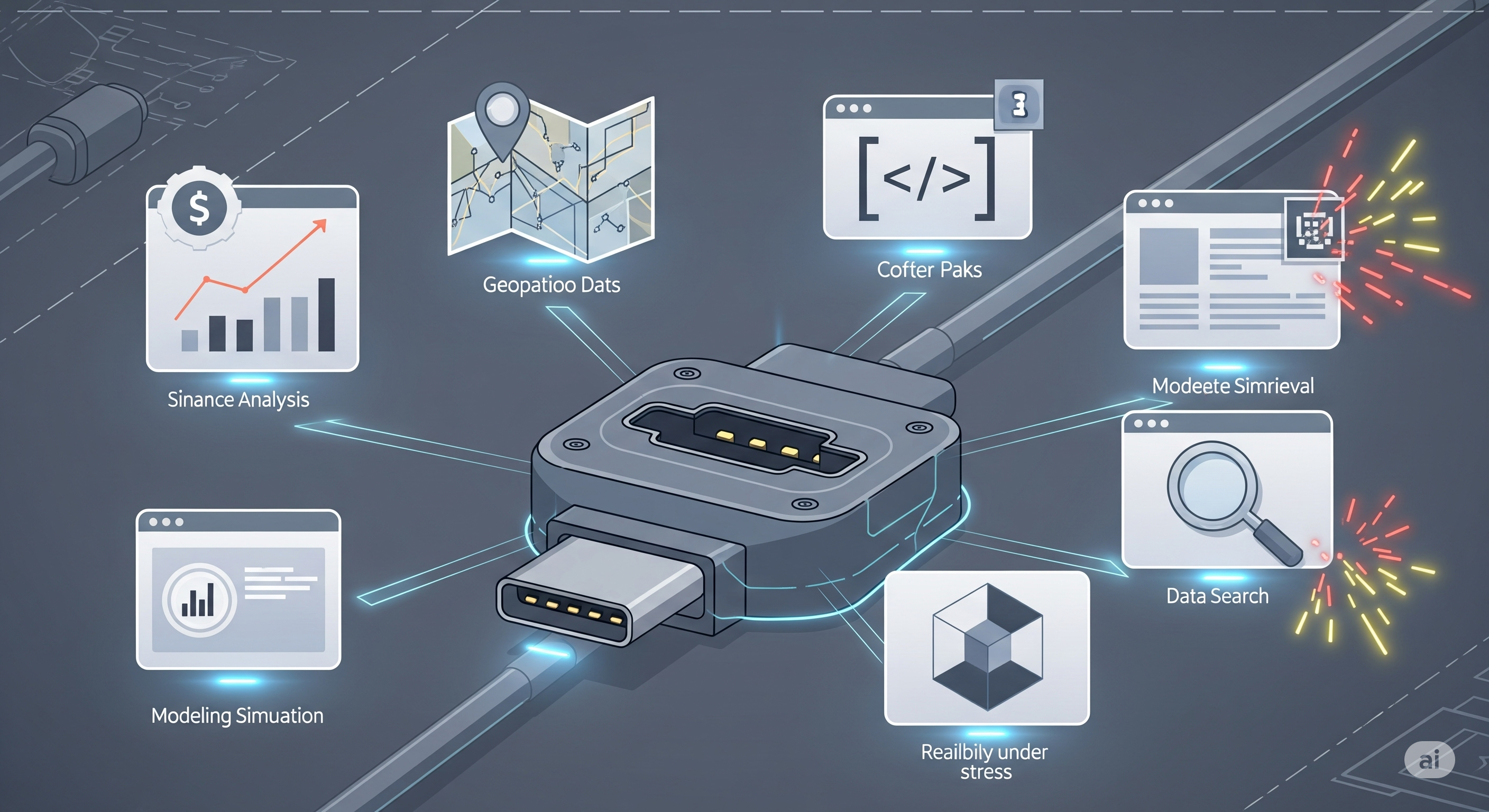
TL;DR for operators MCP-Universe is useful because it punctures a very convenient belief: once an LLM is connected to tools through MCP, the agent is basically “integrated” and therefore close to production-ready. The paper says: adorable, but no.1 The benchmark tests agents against real MCP servers rather than toy APIs. It covers 231 tasks across Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. It uses 11 MCP servers, 133 tools, and 84 execution-based evaluators, including dynamic evaluators that retrieve live ground truth for time-sensitive tasks. ...