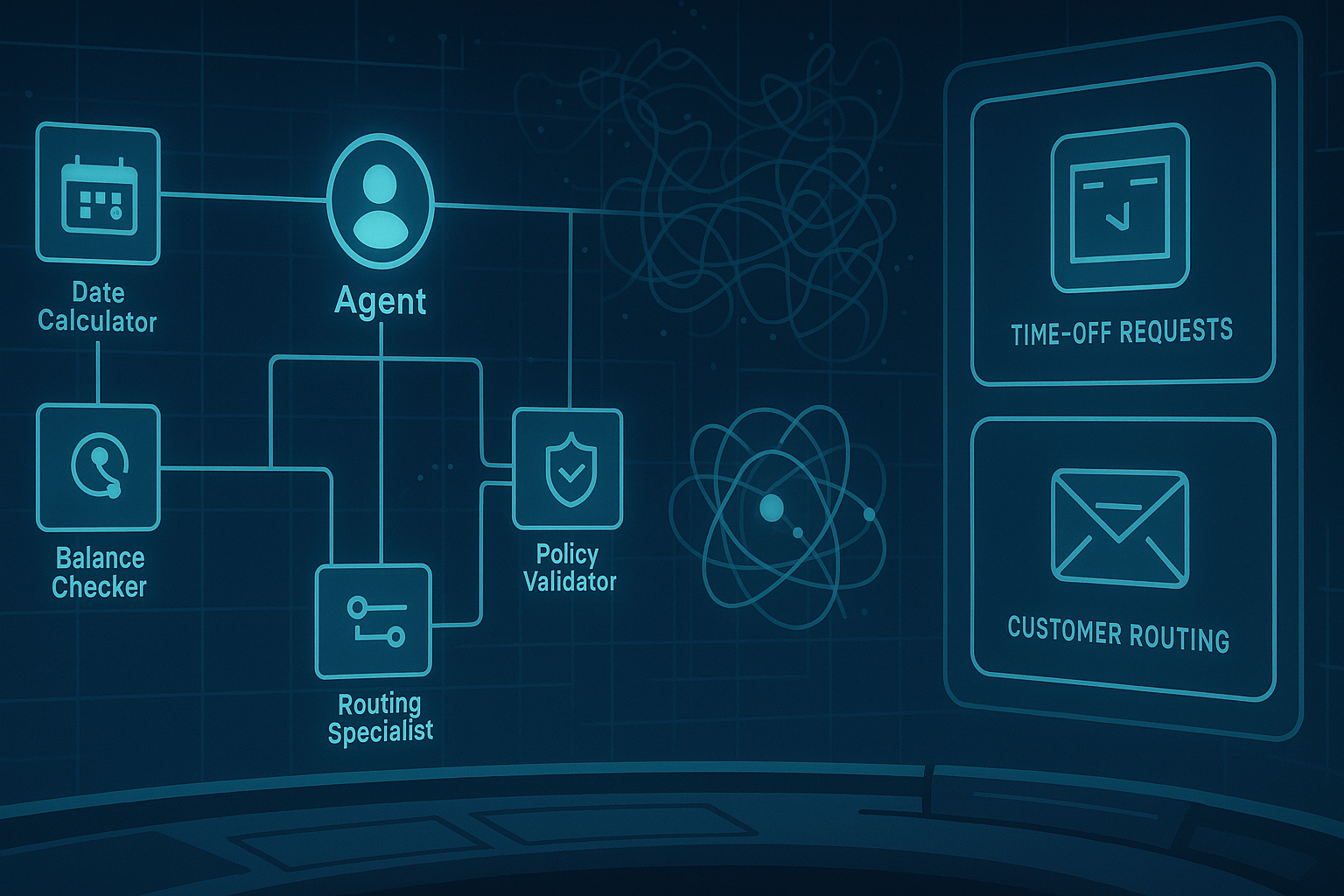
Enviro-Mental Gymnastics: Why Cross-Environment Agents Still Trip Over Their Own Feet
Demo day is easy. Give an AI agent one workflow, one tool stack, one database schema, one approval rule, and one forgiving evaluator, and it may look surprisingly competent. It files the ticket. It updates the CRM. It writes the SQL query. Everyone nods. Someone says “agentic transformation,” because apparently every procurement meeting now needs a spell. ...