Mirror, Signal, Manoeuvre: Why Privileged Self‑Access (Not Vibes) Defines AI Introspection
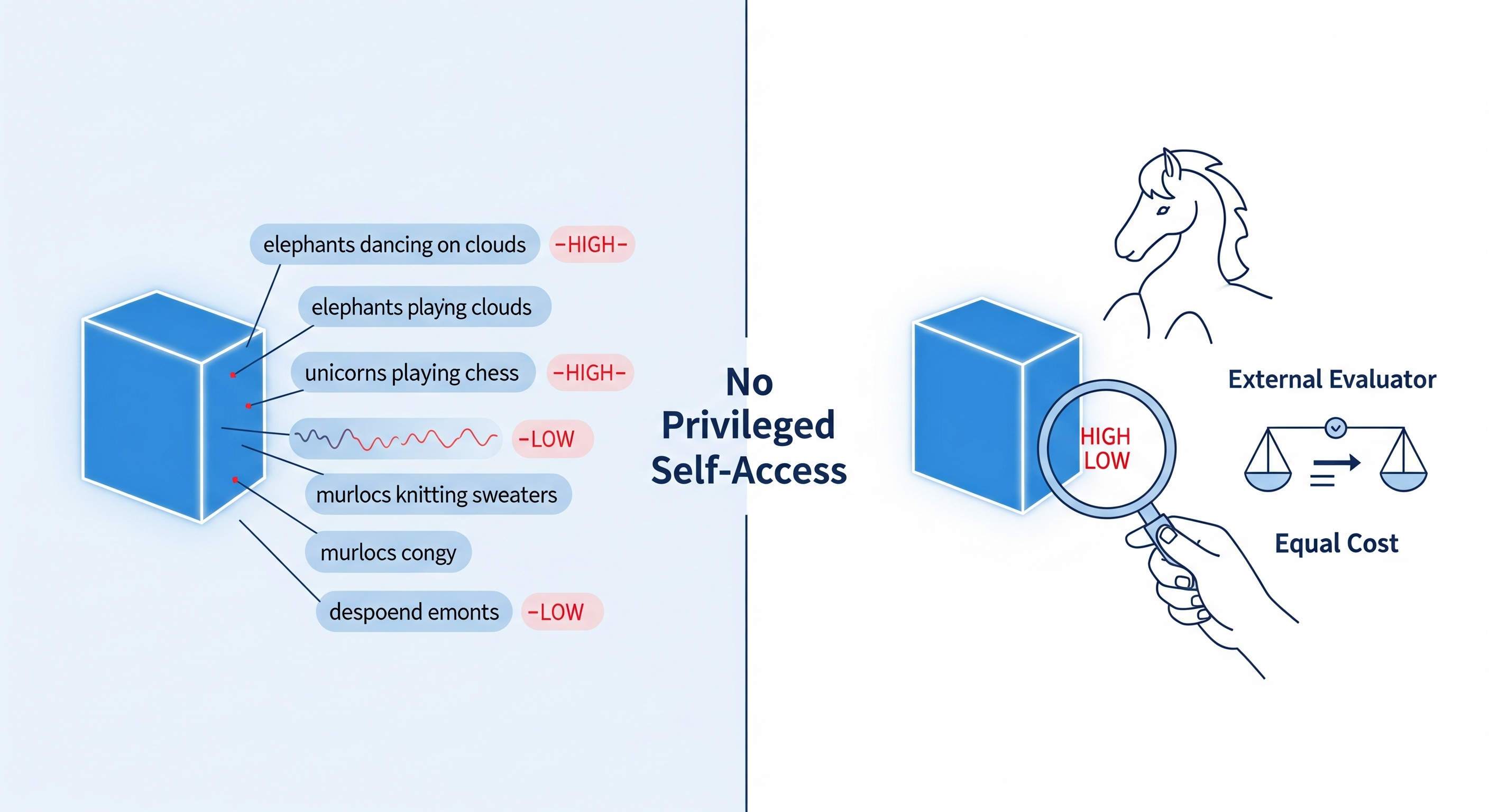
TL;DR for operators Dashboard lights are useful because they are wired into the machine. A sticker saying “probably fine” is less useful, even if the sticker was generated in a reassuring font. That is the practical distinction in this paper. Song, Lederman, Hu, and Mahowald argue that AI introspection should not mean “the model says something plausible about itself.” It should mean the model has privileged self-access: it can report an internal state more reliably than an outside evaluator using the same visible evidence at equal or lower computational cost.1 ...