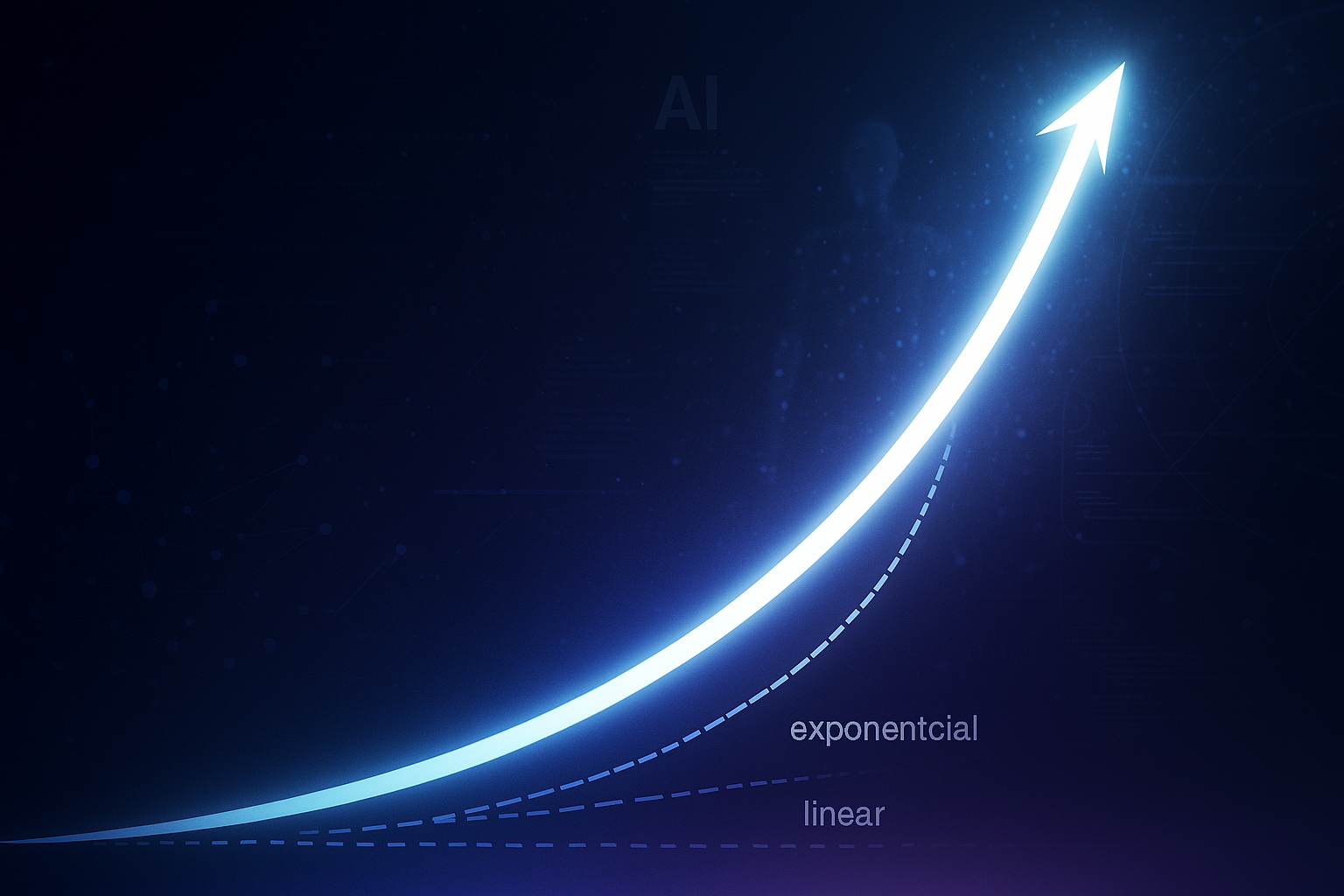
Jolting Ahead: Why AI’s Acceleration Is Accelerating
TL;DR for operators Dashboards are good at telling you where performance is today. They are worse at telling you whether the rate of improvement is itself accelerating. That is the useful business translation of David Orban’s paper on “jolting” AI capabilities: do not only monitor model scores; monitor the shape of improvement. ...








