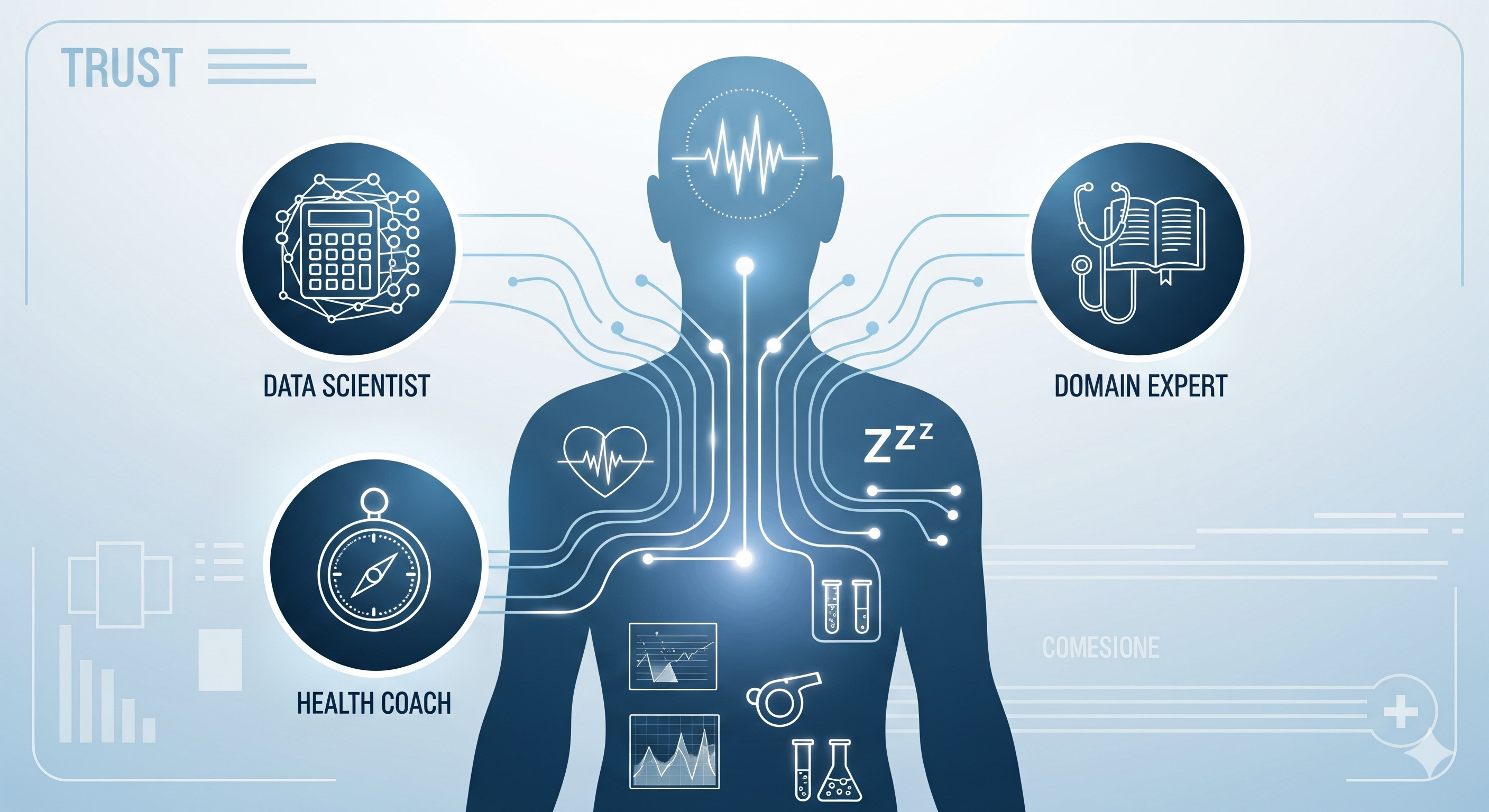
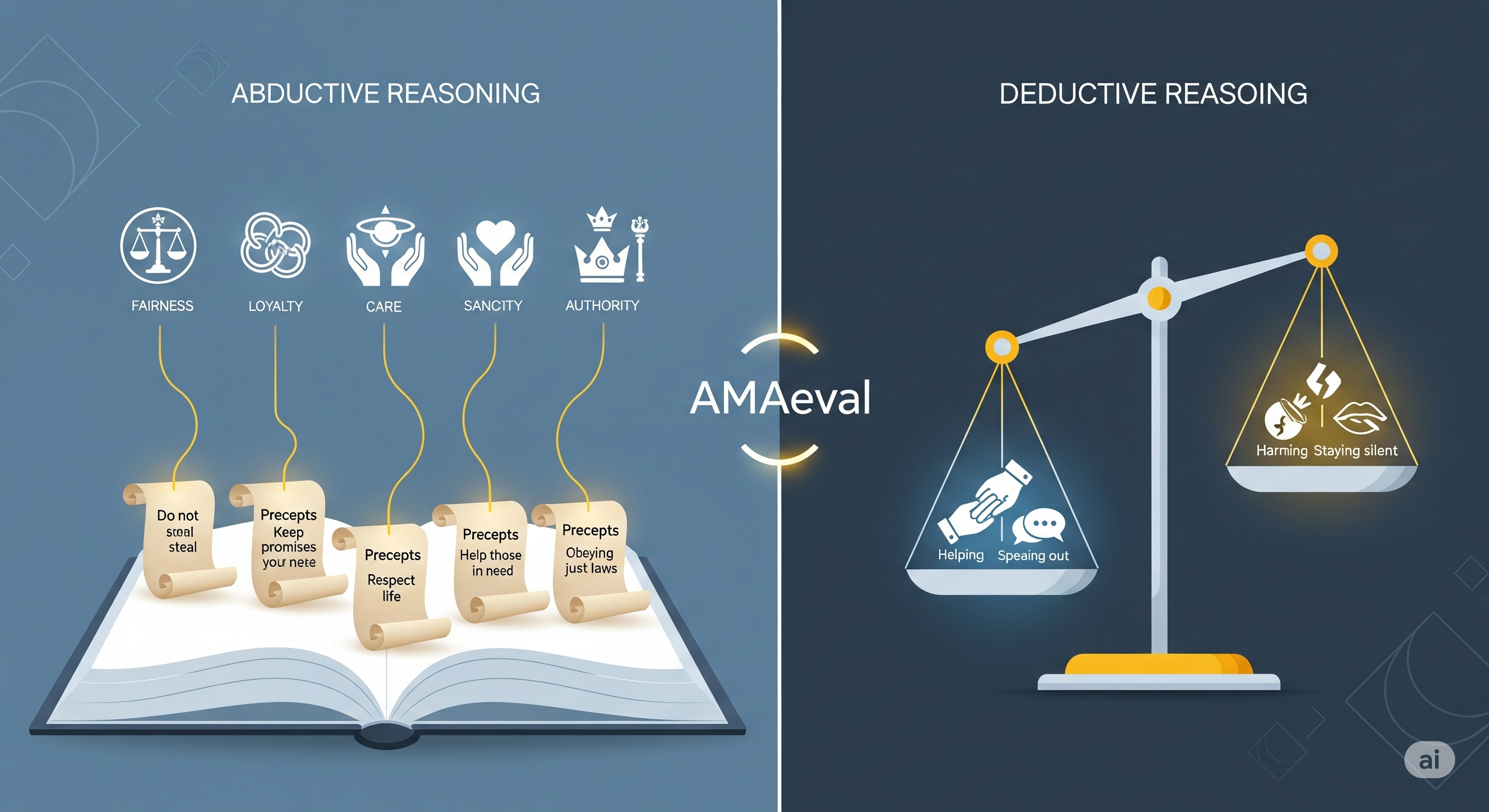
Terms of Engagement: Building Trustworthy AI Agents Before They Build Us
As agentic AI moves from flashy demos to day‑to‑day operations—handling renewals, filing tickets, triaging inboxes, even buying things—the question is no longer can we automate judgment, but on what terms. This isn’t ethics-as-window‑dressing. Agent systems perceive, decide, and act through real interfaces (email, bank APIs, code repos). They can help—or hurt—at machine speed. Today I’ll argue three things: Alignment must shift from “answer quality” to action quality. Social agents change the duty of care developers and companies owe to users. We need a governance stack for multi‑agent ecosystems, not one‑off checklists. The discussion is grounded in the Nature piece by Gabriel, Keeling, Manzini, and Evans (2025), but tuned for operators shipping products this quarter—not a hypothetical future. ...