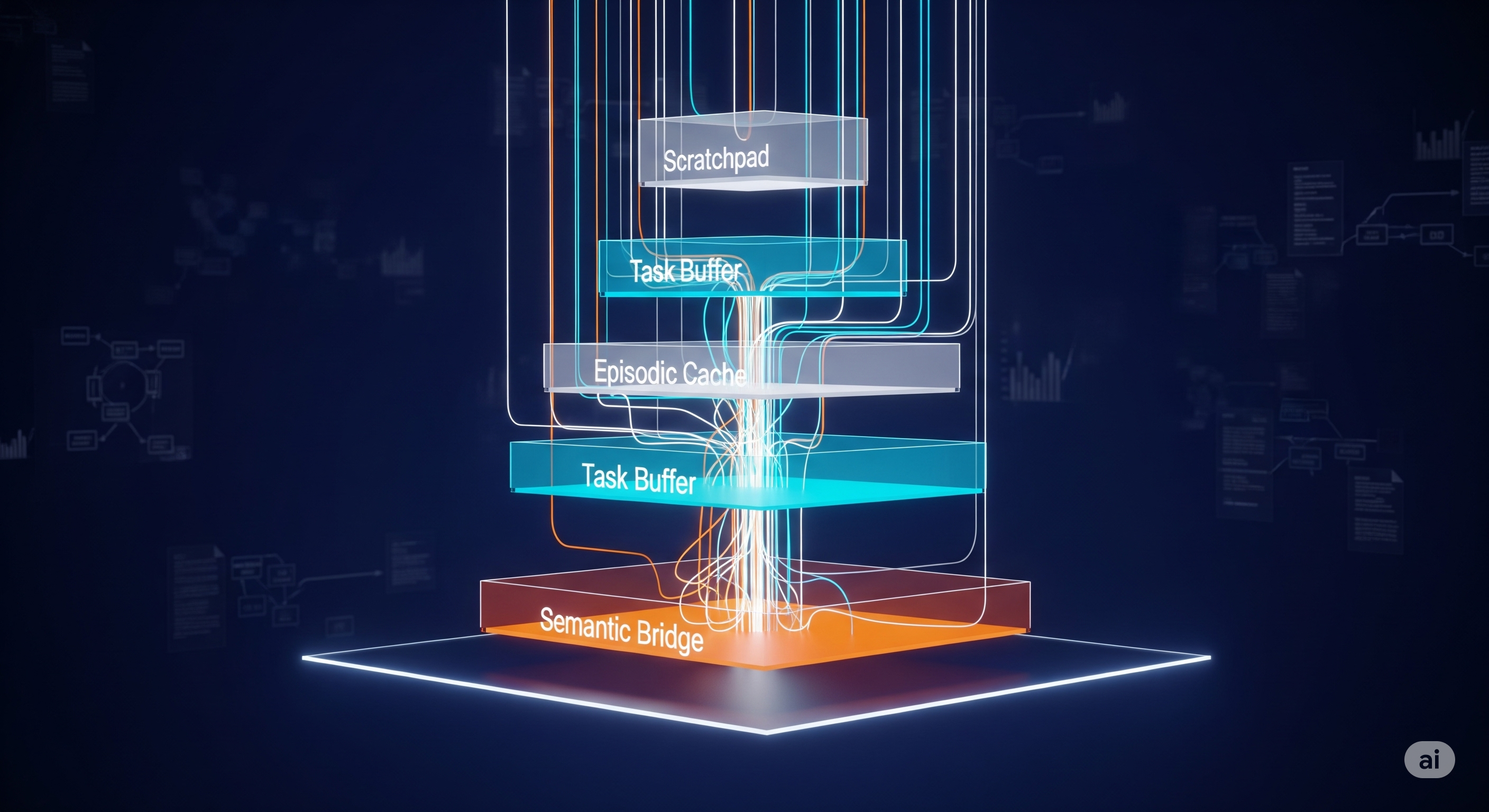
Click Less, Do More: Why API-GUI + RL Could Finally Make Desktop Agents Useful
TL;DR for operators ComputerRL is not interesting because a 9B model learned to click slightly better. That would be charming, in the way a robot vacuum wedged under a sofa is charming. The paper matters because it attacks the three actual bottlenecks in desktop automation: the wrong interface, the wrong training scale, and the wrong assumption that long RL runs keep exploring by magic.1 ...