AI Agents vs Workflows
How to separate true agent-like systems from straightforward AI workflows, and why most business use cases should start simpler.
How to separate true agent-like systems from straightforward AI workflows, and why most business use cases should start simpler.

Opening — Why this matters now Multimodal reasoning has quietly hit an efficiency wall. We taught models to think step by step with text, then asked them to imagine with images, and finally to reason with videos. Each step added expressive power—and cost. Images freeze time. Videos drown signal in redundancy. Somewhere between the two, reasoning gets expensive fast. ...

Opening — Why this matters now Multimodal AI has spent the last two years narrating its thoughts like a philosophy student with a whiteboard it refuses to use. Images go in, text comes out, and the actual visual reasoning—zooming, marking, tracing, predicting—happens offstage, if at all. Omni-R1 arrives with a blunt correction: reasoning that depends on vision should generate vision. ...

TL;DR UltraHorizon is a new benchmark that finally tests what real enterprise projects require: months‑long reasoning crammed into a single run—35k–200k tokens, 60–400+ tool calls, partially observable rules, and hard commitments at the end. Agents underperform badly versus humans. The pattern isn’t “not enough IQ”; it’s entropy collapse over time (the paper calls it in‑context locking) and foundational capability gaps (planning, memory, calibrated exploration). Simple scaling fails; a lightweight strategy—Context Refresh with Notes Recall (CRNR)—partially restores performance. Below we translate these findings into a deployer’s playbook. ...

TL;DR SFT memorizes co-occurrences; RL explores. That’s why RL generalizes better on planning tasks. Policy-gradient (PG) can hit 100% training accuracy while silently killing output diversity. KL helps—but caps gains. Q-learning with process rewards preserves diversity and works off‑policy. With outcome‑only rewards, it reward-hacks and collapses. Why this paper matters to builders If you’re shipping agentic features—tool use chains, workflow orchestration, or multi-step retrieval—you’re already relying on planning. The paper models planning as path-finding on a graph and derives learning dynamics for SFT vs RL variants. The results give a crisp blueprint for product choices: which objective to use, when to add KL, and how to avoid brittle one-path agents. ...
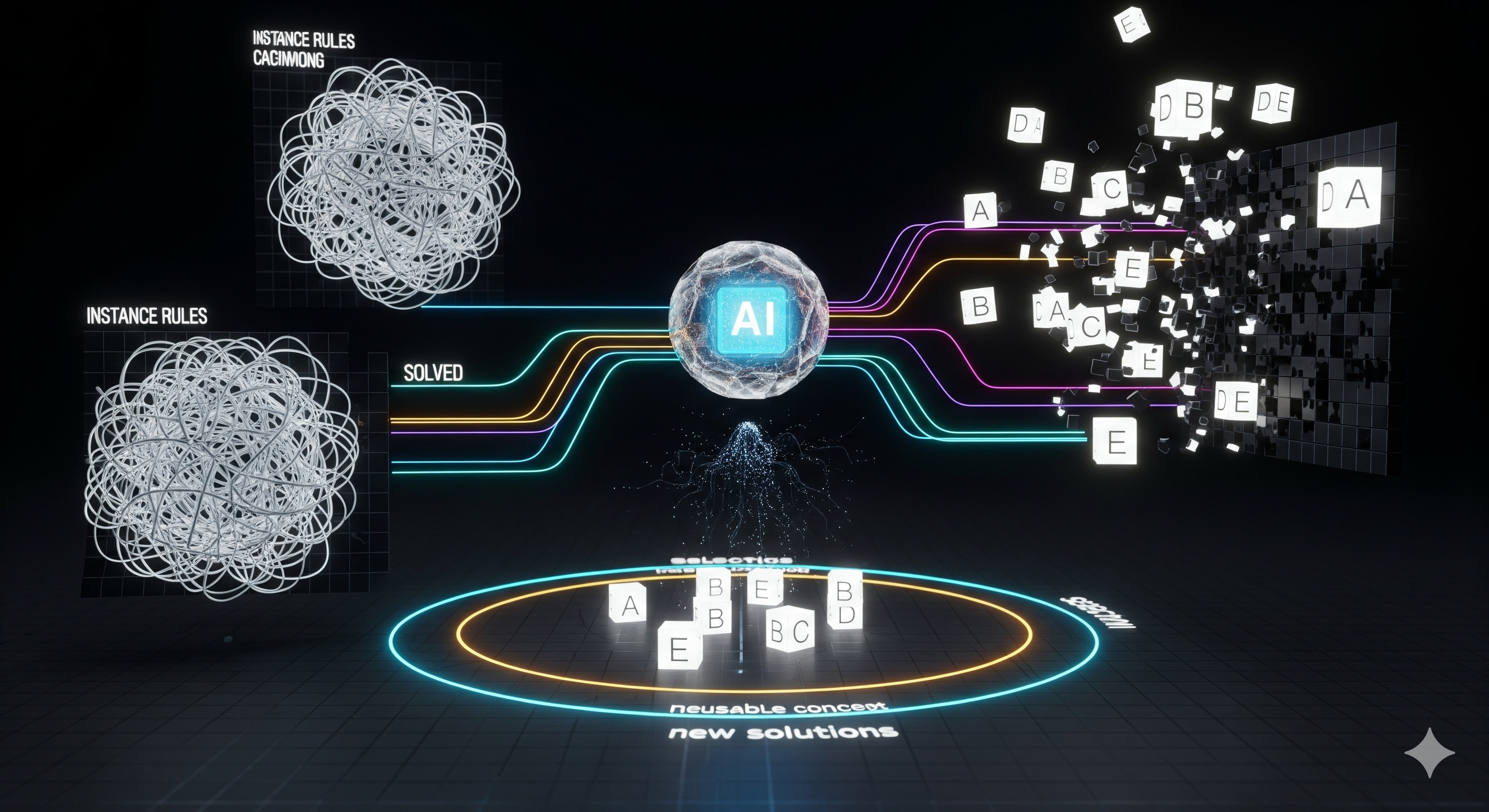
TL;DR Most memory systems hoard instances (queries, answers, snippets). ArcMemo instead distills concepts—compact, reusable abstractions of what a model learned while solving a problem. Those concepts are retrieved and recombined for new problems. On ARC‑AGI, this design beats strong no‑memory baselines and continues to scale with retries, showing a credible path to lifelong, test‑time learning without finetuning. Why this paper matters The status quo of “inference‑time scaling” is a treadmill: longer chains of thought today, amnesia tomorrow. Enterprises building agentic systems—customer ops copilots, finance/excel agents, or low‑code RPA flows—need their agents to keep what they learn and apply it later without weight updates. ArcMemo’s move from instance‑level to concept‑level memory is the right abstraction boundary: ...

TL;DR Deep Research agents are great at planning over messy data but bad at disciplined execution. Semantic-operator systems are the opposite: they execute efficiently but lack dynamic, cross-file reasoning. The Palimpzest prototype bridges the two with Context, compute/search operators, and materialized context reuse—a credible blueprint for an AI‑native analytics runtime over unstructured data. The Business Problem: Unstructured Data ≠ SQL Most companies still funnel PDFs, emails, HTML, and CSVs into brittle ETL or costly human review. Classic OLAP/SaaS BI stacks excel at structured aggregates, but stumble when a question spans dozens of noisy files (e.g., “What’s the 2024 vs 2001 identity‑theft ratio?”) or requires nuanced judgments (e.g., “Which Enron emails contain firsthand discussion of Raptor?”). Two current approaches each miss: ...

TL;DR Pair a classic mixed‑integer inventory redistribution model with an LLM-driven context layer and you get explainable optimization: the math still finds near‑optimal transfers, while the LLM translates them into role‑aware narratives, KPIs, and visuals. The result is faster buy‑in, fewer “why this plan?” debates, and tighter execution. Why this paper matters for operators Most planners don’t read constraint matrices. They read stockout risks, truck rolls, and WOS. The study demonstrates a working system where: ...

TL;DR — A new framework (EconAgentic) models DePIN growth stages, token/agent interactions, and macro goals (efficiency, inclusion, stability). Its key finding: more patient LLM agents (i.e., slower to exit) can increase inclusion and stability with little efficiency penalty. Sensible—but only if token price formation, data integrity, and geospatial participation are measured rigorously. Why this paper matters DePIN (Decentralized Physical Infrastructure Networks) turns physical capacity—wireless hotspots, sensors, compute, even energy—into token‑incentivized networks. The promise is Uber/Airbnb’s distribution without the platform as rent‑extractor. EconAgentic contributes a general model that: ...

Large models are passing tests, but they’re not yet passing life. A new paper proposes Experience‑driven Lifelong Learning (ELL) and introduces StuLife, a collegiate “life sim” that forces agents to remember, reuse, and self‑start across weeks of interdependent tasks. The punchline: today’s best models stumble, not because they’re too small, but because they don’t live with their own memories, skills, and goals. Why this matters now Enterprise buyers don’t want parlor tricks; they want agents that schedule, follow through, and improve. The current stack—stateless calls, long prompts—fakes continuity. ELL reframes the problem: build agents that accumulate experience, organize it as memory + skills, and act proactively when the clock or context demands it. This aligns with what we’ve seen in real deployments: token context ≠ memory; chain‑of‑thought ≠ skill; cron jobs ≠ initiative. ...