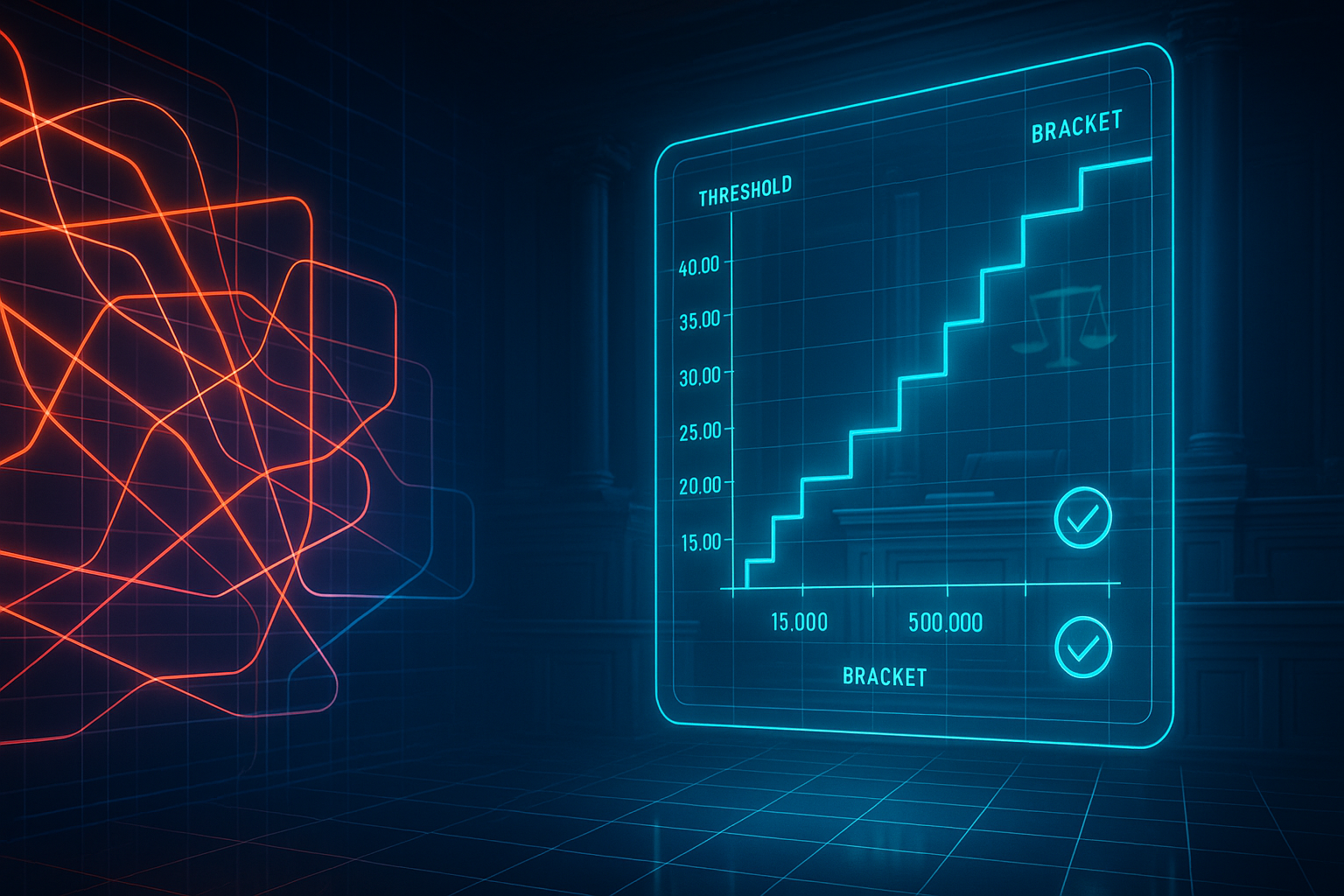
TL;DR Tax law is full of brackets, caps, cliffs, phase-outs, and exceptions. Conveniently, those are also the places where software quietly breaks.
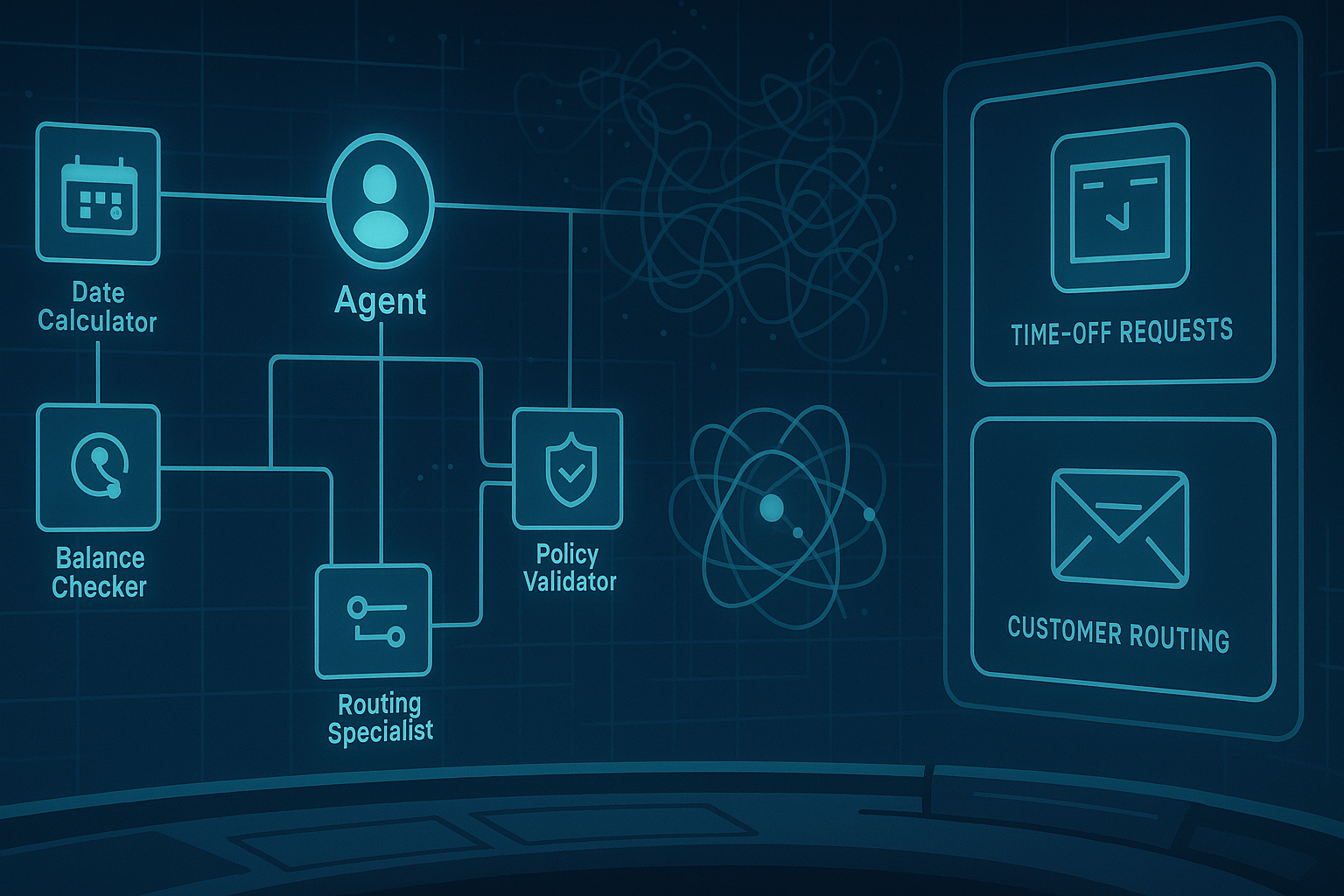
The paper behind this article introduces Synedrion, a multi-agent LLM framework for translating legal tax documents into executable software.1 Its most useful idea is not “use agents” in the vague conference-demo sense. It is more specific: split legal interpretation, code generation, senior review, and behavioural testing into separate roles, then use higher-order metamorphic testing to catch systematic errors that normal test cases and pairwise comparisons can miss.
...