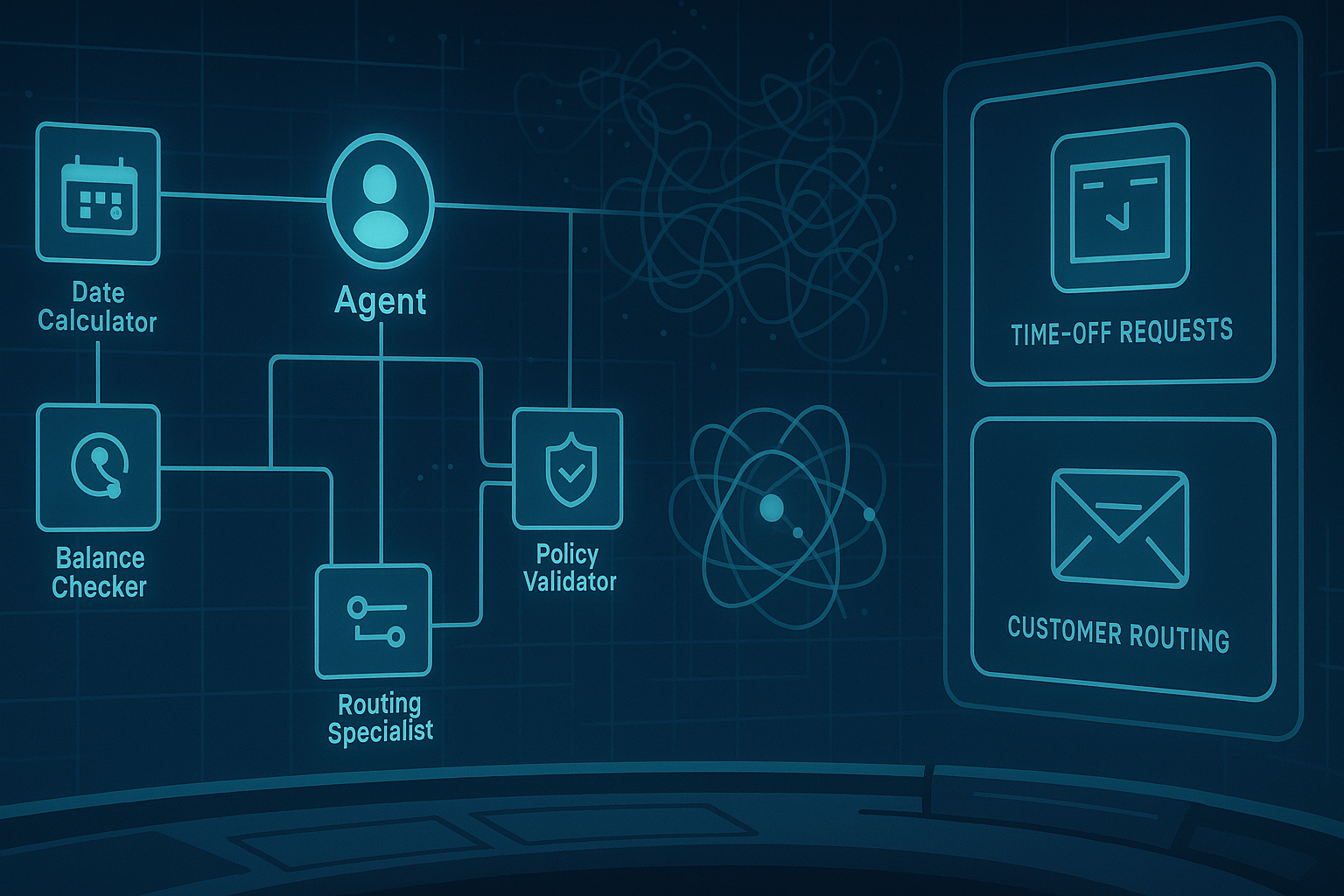
If you’ve ever tried turning a clever chatbot into a reliable employee, you already know the pain: great demos, shaky delivery. AgentArch, a new enterprise-focused benchmark from ServiceNow, is the first study I’ve seen that tests combinations of agent design choices—single vs multi‑agent, ReAct vs function-calling, summary vs complete memory, and optional “thinking tools”—across two realistic workflows: a simple PTO process and a gnarly customer‑request router. The result is a cold shower for one‑size‑fits‑all playbooks—and a practical map for building systems that actually ship.
TL;DR for Builders
- There’s no universally best architecture. The “right” design depends on the task.
- Function‑calling wins broadly; multi‑agent ReAct underperforms and hallucinates.
- Thinking tools (structured math/synthesis) help on simple tasks; barely matter on complex routing.
- If your KPI is the final business decision (not perfect tool usage), multi‑agent function‑calling often wins.
Below I translate AgentArch’s results into design rules you can apply this quarter—plus a simple rubric for your next proof‑of‑value.
The Setup (No Lab Toys—Real Workflows)
AgentArch evaluates 18 architectural combinations across six models on two enterprise scenarios:
- Requesting Time Off (TO) — a structured, rules‑based flow (8 tools, 3 agents). Think: date math, leave balances, policy checks.
- Customer Request Routing (CR) — messy triage (31 tools, 9 agents). Think: classification, escalation, ambiguity handling.
The benchmark grades success only when all three are correct: 1) tool choice (lenient), 2) tool arguments (exact), and 3) the final decision. That’s the right standard for production automation.
What Mattered, Where
1) Orchestration & Agent Style
Function‑calling > ReAct almost everywhere. ReAct shines in papers; in production multi‑agent settings it added latency and hallucinations without consistent gains.
- Simple flow (TO): Best scores came from single‑agent + function‑calling (with thinking tools).
- Complex routing (CR): Top overall scores were modest even for the best models, but the highest final‑decision accuracy often came from multi‑agent + function‑calling—even when overall acceptability lagged. Translation: division of labor helps the decision, but models still fumble tool hygiene.
2) Memory Strategy
Complete vs summarized memory barely moved the needle in multi‑agent settings. If tokens are money (they are), default to summarized unless your domain has deep cross‑step dependencies.
3) “Thinking Tools”
On the PTO flow, explicit math/synthesis tools boosted non‑reasoning models noticeably. On complex routing, the lift was negligible. My take: use them to harden arithmetic and tabulation; don’t expect miracles on judgment calls.
A Choosing‑Architecture Cheat Sheet
| Task pattern | Recommended default | When to override |
|---|---|---|
| Deterministic, rules‑heavy (dates, balances, policy gates) | Single‑agent + function‑calling + thinking tools; summarized memory | If tools fan out beyond ~10 or inputs are very long, move to orchestrated (isolated) multi‑agent to cap context bloat |
| Ambiguous triage / routing / escalation | Multi‑agent + function‑calling, summarized memory; thinking tools off | If final decisions are good but tool arguments fail, add validator agents (schema checkers) and forced‑finish tools |
| Exploratory or creative (rare in strict enterprise flows) | Consider single‑agent ReAct for transparency | Avoid multi‑agent ReAct until your models and prompts are hardened |
From Benchmark to Playbook
Here’s a concrete rollout path for Cognaptus clients moving from demo to production.
Phase 1 — Nail the “Golden Path”
- Start single‑agent function‑calling for deterministic flows. Add a math thinking tool if totals/intervals matter.
- Enforce schemas: tool argument validators, required keys, and a finish tool that demands a structured self‑summary.
- Instrument pass@1 metrics by stage: tool choice (lenient), arg exactness, final decision. Celebrate the last one; fix the first two with guardrails.
Phase 2 — Scale to Multi‑Agent (Only When Needed)
- Split responsibilities (e.g., Classification → Retrieval → Decision). Keep orchestrator‑isolated comms to avoid chatty agents.
- Keep function‑calling; treat ReAct as an opt‑in for a single role (e.g., Planner) if you must.
- Add anti‑loops: repetition detectors, backoff on identical tool calls, and “ask‑for‑clarity or stop” branches.
Phase 3 — Reliability Engineering
- Shadow‑run K trials per record (pass^K). Aim >95% for critical paths before full automation.
- Canary deploy with human‑in‑the‑loop on escalations; graduate tools one by one from “read‑only” to “write”.
- Cost discipline: summarized memory by default; long contexts only where they pay.
Why This Matters for KPIs
- Cycle time drops when single‑agent flows are used where appropriate; multi‑agent is reserved for judgment‑heavy steps.
- Error rates fall when you privilege final‑decision accuracy and retrofit validators/guards around tool calls.
- Unit economics improve when thinking tools are deployed where they’re accretive (math, synthesis), not everywhere.
Where I Disagree (Constructively)
AgentArch’s complex routing task still rewards exact tool/argument matching. In production, we should grade the system, not just the LLM: allow post‑tool business rule engines (deterministic) and argument auto‑fixers (schema + retrieval) to absorb model variance. That’s how you convert a 35% “acceptable” into a 90% service level without a model upgrade.
Field Checklist (Paste into your runbook)
- Use function‑calling by default; avoid multi‑agent ReAct.
- Add thinking tools only for math/synthesis‑heavy steps.
- Prefer summarized memory; log full transcripts outside the prompt.
- Instrument final‑decision accuracy separately from tool hygiene.
- Add validators: argument schema checks, duplication guard, forced finish.
- Gate write tools behind read→dry‑run→write promotions.
Cognaptus: Automate the Present, Incubate the Future