Map Before You Train: Data Cartography to Defuse LLM Memorization
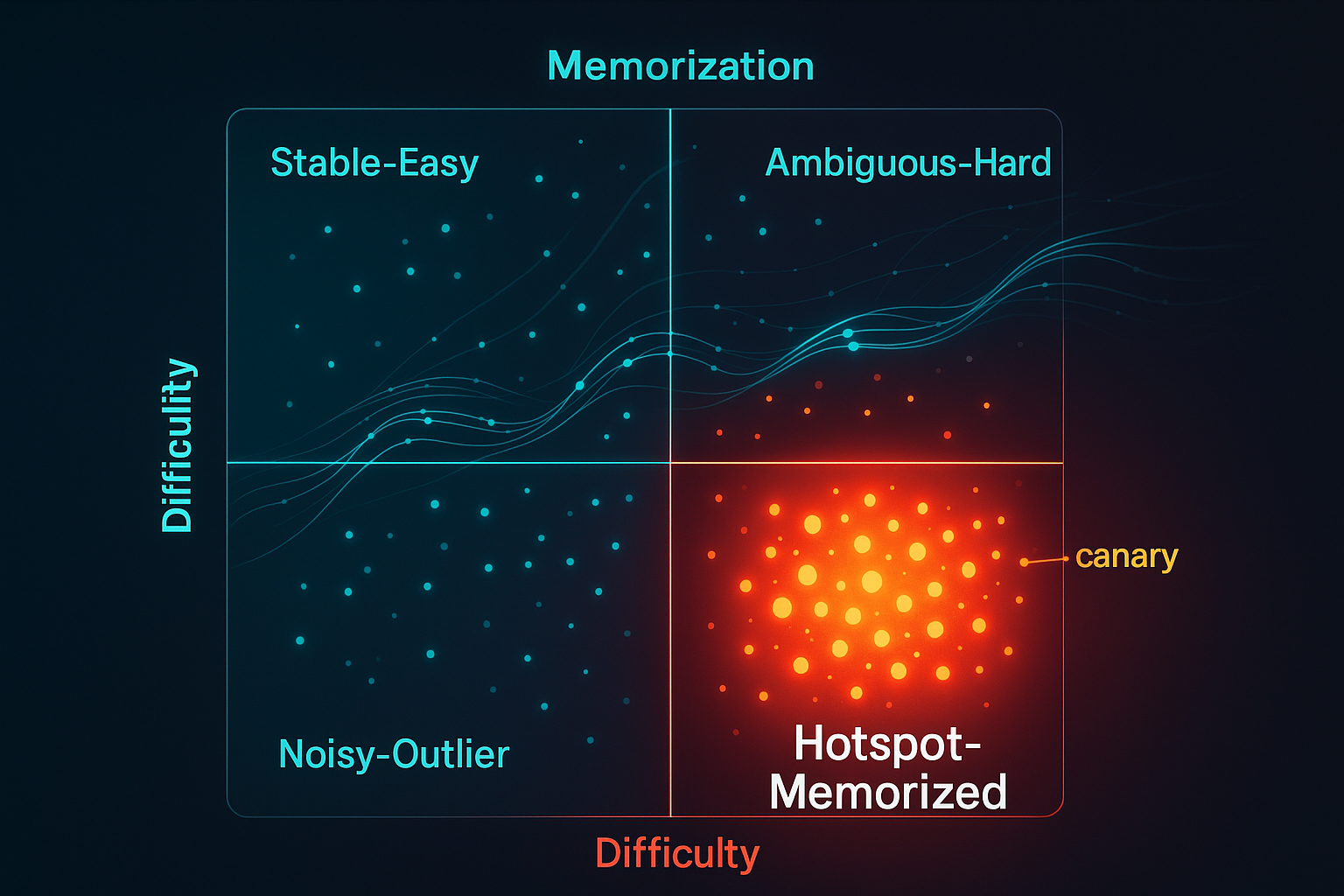
TL;DR for operators Training data does not become risky only after a model has memorised it. It often leaves signals while training is still happening. That is the useful idea behind Generative Data Cartography, or GenDataCarto: track how each pretraining sample behaves during early training, then use that behaviour to decide which data should be kept, up-sampled, down-weighted, or removed.1 The method uses two signals. The first is early loss, which approximates how difficult a sample is. The second is the frequency of “forget events”, where a sample appears learned and later becomes poorly fitted again. In the paper’s framing, frequent forget events are not just training noise. They are a warning that a sample may be unusually influential, repeatedly re-entering the model’s attention like a guest who refuses to leave the meeting. ...