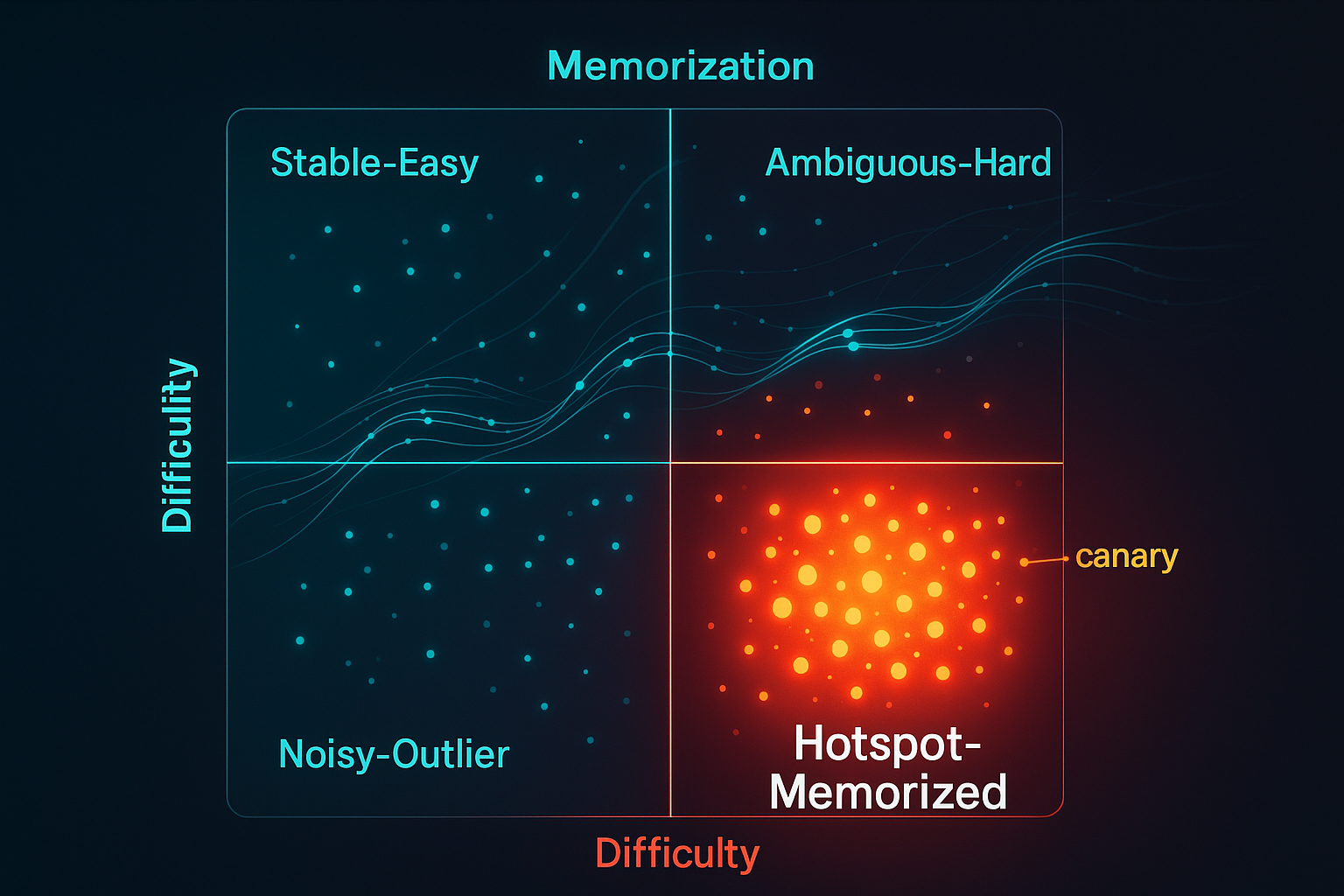
When Benchmarks Forget What They Learned
The leaderboard said “learning.” The model may have heard “storage.” Benchmarks are supposed to answer a simple business question: does this model actually perform the task? That sounds clean. A model receives a test. It gives answers. Someone turns the answers into a score. Procurement teams, product managers, investors, and mildly overconfident LinkedIn commentators then convert the score into a story about intelligence. The machinery is familiar enough to feel objective. ...