Less Prompt, More Blueprint: MOSAIC and the Data-Science Agent That Keeps Receipts
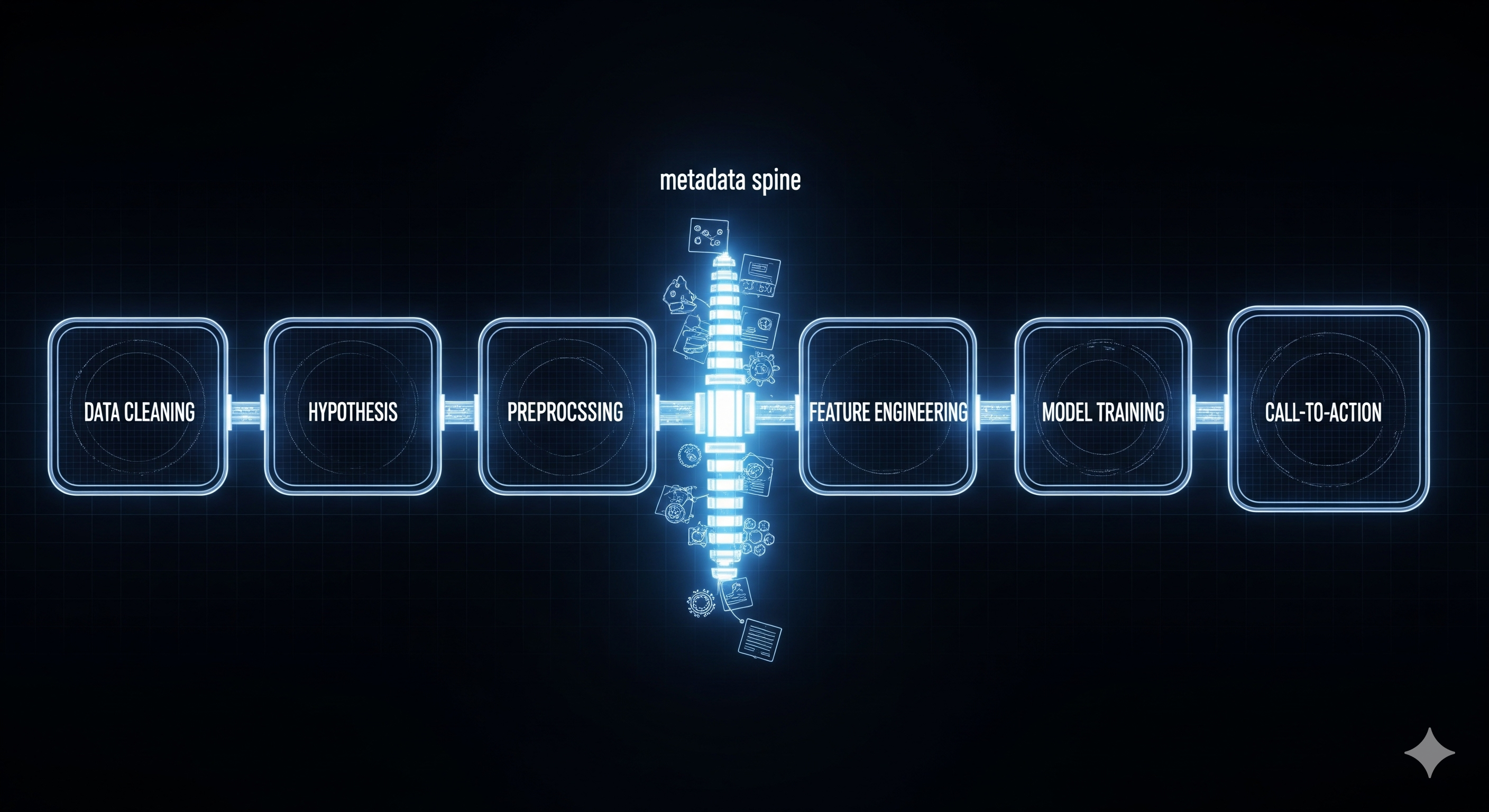
TL;DR for operators MOSAIC is best read as a system-design paper, not as another entry in the increasingly crowded genre of “we attached an LLM to Python and hoped for the best.” The paper introduces a structured agentic framework for automated data science where the agent builds an explicit workflow blueprint before generating code, then verifies, executes, and refines candidates using diagnostic feedback and failure-aware offline reinforcement learning.1 ...