Most “AI for analytics” pitches still orbit model metrics. The more interesting question for executives is: What should we do next, and why?
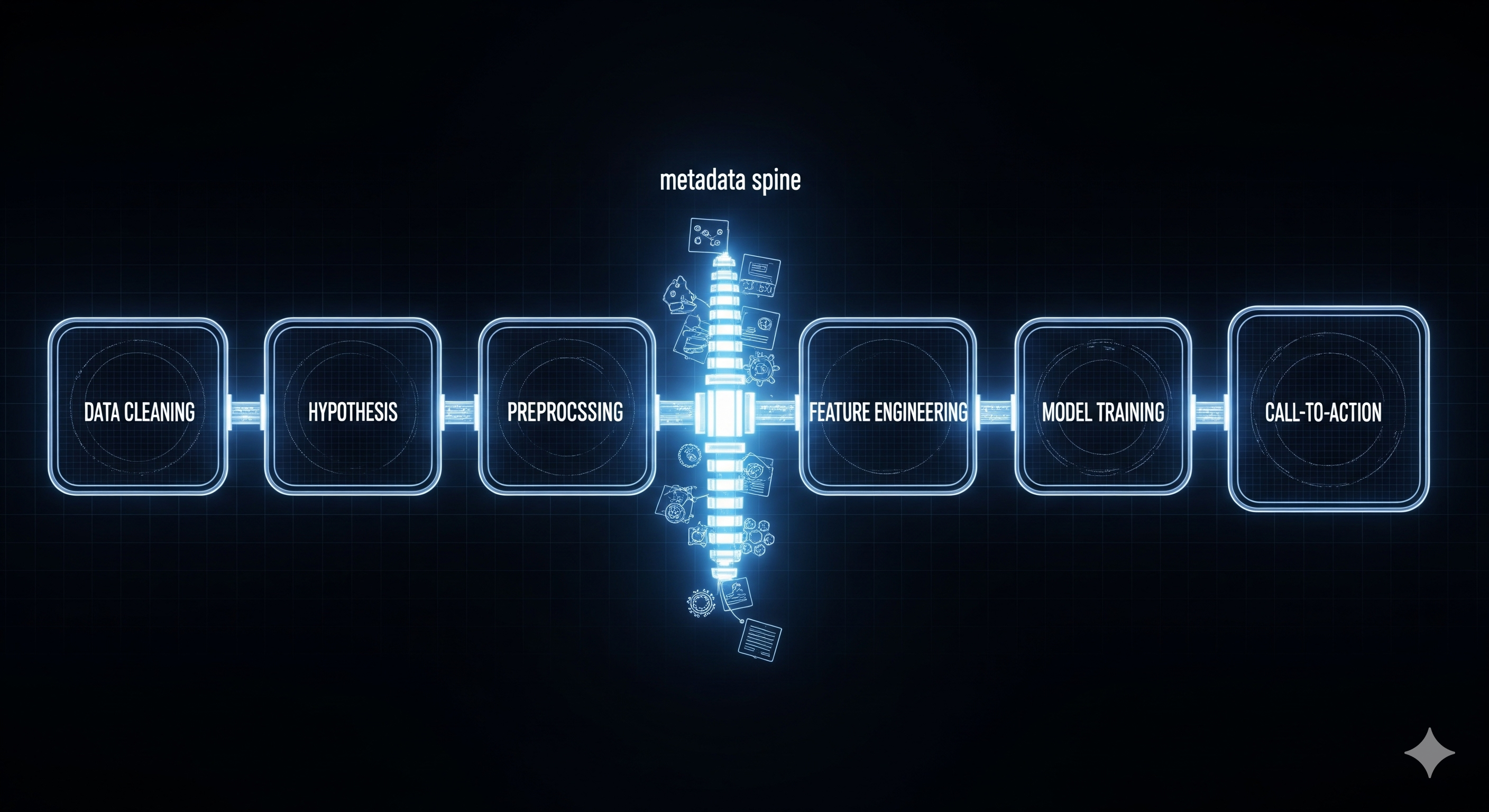
A recent paper proposes an AI Data Scientist—a team of six LLM “subagents” that march from raw tables to clear, time‑boxed recommendations. The twist isn’t just automation; it’s hypothesis‑first reasoning. Instead of blindly optimizing AUC, the system forms crisp, testable claims (e.g., “active members are less likely to churn”), statistically validates them, and only then engineers features and trains models. The output is not merely predictions—it’s an action plan with KPIs, timelines, and rationale.
TL;DR for operators
- Why it matters: Converts data into defensible actions, shrinking the gap between analysis and execution.
- What’s new: A disciplined, hypothesis-driven pipeline that carries statistical proof forward as metadata.
- Where it wins: Tabular business problems—churn, pricing, risk—where interpretability and speed beat exotic deep nets.
- What to watch: Causality, fairness, and governance. The paper is honest about limits and offers a pragmatic rollout path.
The six-subagent relay (and why it’s different)
| Subagent | Job-to-be-done | Why it’s useful to business |
|---|---|---|
| Data Cleaning (DC) | Impute, standardize, outlier handling; record every step as metadata | Reduces “unknown unknowns” and speeds re-runs/audits |
| Hypothesis (HYP) | Propose & test claims (t‑tests, chi‑square, ANOVA, correlations, survival, changepoints) | Translates noise into evidence; only validated signals progress |
| Preprocessing (PREP) | Scaling/encoding with awareness of validated signals | Preserves meaning (e.g., don’t bin Age if it’s linearly predictive) |
| Feature Engineering (FEAT) | Build interactions, temporal lags, group stats tied to hypotheses | Features inherit business logic; easier to explain & monitor |
| Model Training (MT) | Ensembles across trees/linear/probabilistic; CV + tuning | Competitive accuracy without black-box mystique |
| Call‑to‑Action (CTA) | Turn findings into timelines, KPIs, and ownership | Puts decisions on rails; closes the loop from evidence → action |
What’s genuinely novel: the metadata spine. Each subagent appends JSON notes—transformations, p‑values, effect sizes, importance scores—so downstream steps inherit verified context. In practice, that means the CTA can point to exact tests and features behind each recommendation.
Why this beats “pure AutoML” in the enterprise
Most AutoML assumes clean labels and optimizes metrics. This agentic design:
- Starts with claims, not hyperparameters. You get statements leaders can debate.
- Elevates interpretability because features are built from validated relationships (not just from brute-force transformations).
- Shortens action distance: recommendations are pre-wired with KPIs and timelines.
Business example: In banking churn, validated hypotheses like “< 3-year tenure increases exit risk” and “fewer than two products elevates churn” become dataset flags and board-level talking points.
Results that matter (and how to read them)
- Churn classification: ~86.7% accuracy / 85.5% F1 with a tree-ensemble built on hypothesis‑driven features, outperforming strong Kaggle baselines by ~1–1.5 pts.
- Pricing regressions (diamonds, used cars): sizable RMSE reductions alongside feature sets that stakeholders can interpret.
- Model-agnostic agent: Performs consistently across GPT‑4‑class and open models (Qwen, Llama, Phi), enabling cost–performance trade‑offs by role (e.g., use a pricier model for hypothesis generation, a cheaper one for feature synthesis).
Takeaway: small metric gains plus clarity and speed often outperform larger but opaque lifts when the goal is decisions, not leaderboards.
Where the bodies are buried (limits & risks)
- Correlation ≠ causation: Statistics can validate associations; only experiments/interventions settle cause. Treat CTA as policy hypotheses, then A/B.
- Fairness & bias: Automated hypothesis mining can surface spurious or discriminatory cuts. Bake in subgroup analysis, disparate impact tests, and human review.
- Over‑eager features: Rapidly exploding feature spaces demand regularization and drift monitoring to avoid brittle dashboards and models.
A rollout that survives procurement
The paper outlines a practical adoption path. Here’s a condensed Cognaptus playbook we’d recommend to clients:
- Months 0–3 — Proof of Value (PoV)
- Pick two tabular problems with public baselines (e.g., churn & pricing).
- Success bar: beat baseline by ≥1 pt (cls) or ≥5% RMSE (reg), and ship a CTA memo with KPIs & owners.
- Infra: 8 vCPU / 32 GB RAM is sufficient. Wire guardrails (prompt filters, stat sanity checks) and a lightweight model registry.
- Months 4–9 — Operate & Educate
- Train analysts on statistical reasoning for LLM agents and prompt auditing.
- Add dual observability: technical metrics (latency, token use, error rates) + business metrics (uplift in retention, margin, cycle time).
- Introduce RBAC and red‑team reviews for high‑impact CTAs.
- Months 10–18 — Scale with Governance
- Multimodel strategy by subagent (e.g., high‑accuracy LLM for HYP; frugal LLM for FEAT).
- Add RAG front‑ends so execs can query rationale, linked to the metadata spine.
- Institute an AI Governance Board to review drift, fairness, and ROI quarterly.
Build vs. buy: what to implement first
- Start with the spine: a schema for step‑wise metadata (transforms, tests, effects, feature lineage). Everything else can swap.
- Codify the test library: chi‑square, t‑tests/ANOVA, correlations, survival, changepoints—with automatic power checks and FDR control.
- CTA templates: Opinionated, time‑boxed action plans (owner, metric, target, review cadence) so outputs look like ops memos, not notebooks.
How this connects to past Cognaptus pieces
We’ve argued that agentic AI wins when it closes loops (reason → act → validate). This paper is that loop, specialized for analytics. Its hypothesis-first stance mirrors our earlier points on “LLMs as disciplined analysts, not autocomplete coders.” For leaders wrestling with messy BI stacks and weak model adoption, this is a credible blueprint.
Executive checklist (print this)
- Are our “insights” actually validated hypotheses with effect sizes and tests?
- Can I trace features back to business‑legible claims?
- Do CTAs specify owner, KPI, target, and review date?
- Are we monitoring fairness across segments and drift across time?
- Do we have dual observability (tech + business) and an escalation path?
Conclusion: The value isn’t that an LLM can code a t‑test. It’s that an agentic, hypothesis‑first assembly line turns data into explainable, auditable, and actionable decisions at business speed.
Cognaptus: Automate the Present, Incubate the Future