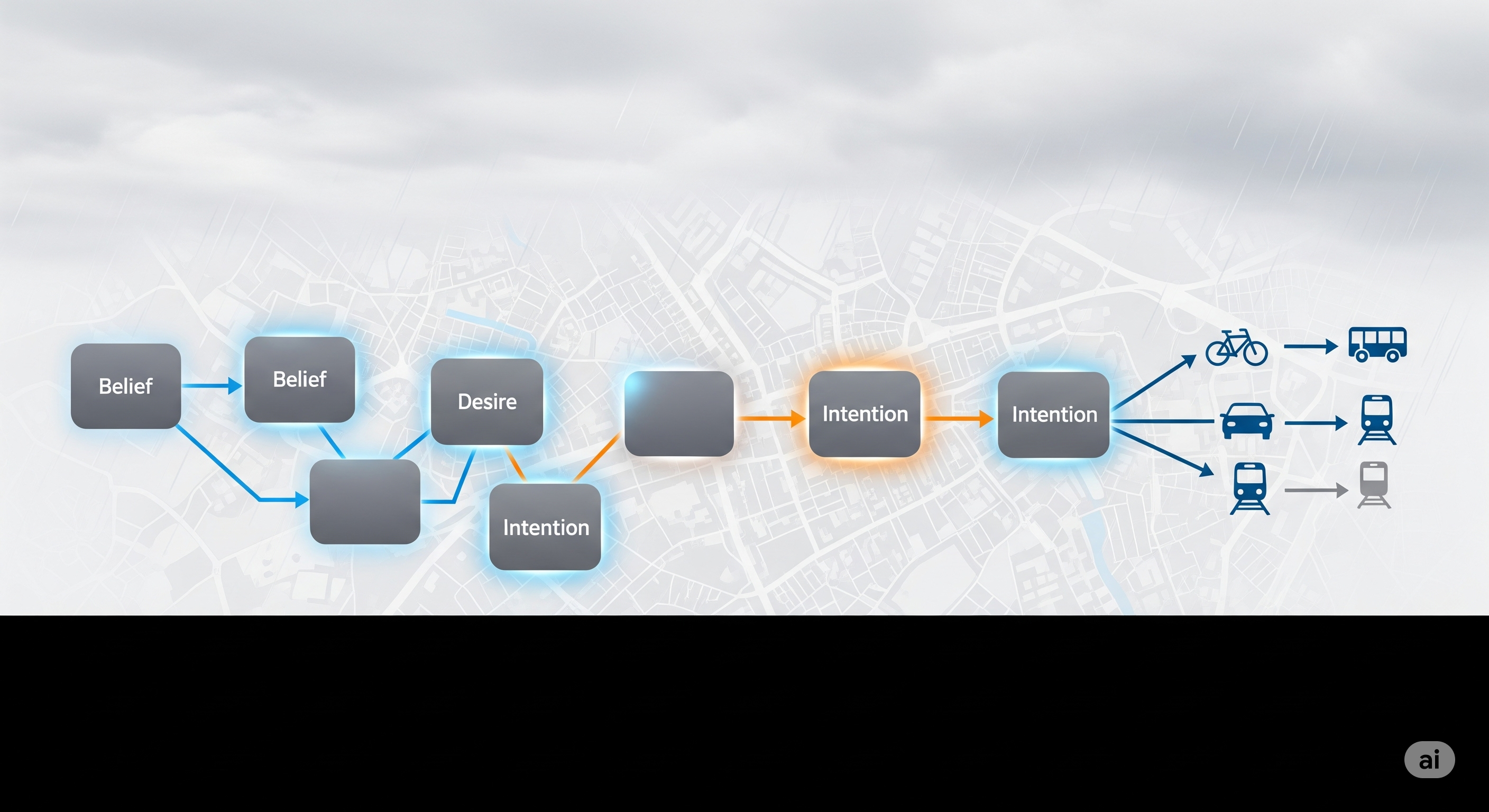
The gist
Most “LLM agents for cities” sound magical until you ask them a basic planning question—which mode would this person actually take at 8am in Cambridge? This paper’s answer is refreshingly concrete: put a belief–desire–intention (BDI) graph around the agent, retrieve analogous people and contexts (Graph RAG), score paths through that graph to get prior choice probabilities, then let the LLM remodel those priors with current conditions (weather, time, place). The authors call this a Preference Chain.
Why I care: it’s the first mobility‑focused recipe I’ve seen that balances three real‑world constraints at once—data scarcity, domain grounding, and agent flexibility—without jumping straight to heavy supervised learning.
What’s actually new here (and why it matters)
- Graph as a choice prior, not a knowledge dump. The graph isn’t a long‑term memory; it’s a probabilistic scaffold linking a simulated person to similar people → similar desires → past intentions. Multiply edge weights along simple paths to get a prior over choices, then normalize across options. No training loop, just clever structure.
- Retrieval that respects topology. They don’t just vector‑search “similar profiles”; they expand to nearby desires and intentions (depth‑limited) to harvest subgraphs that look like the present case. That’s qualitatively different from “stuff chunks into the prompt.”
- LLM as context adapter. The LLM doesn’t invent behavior ex nihilo. It adjusts prior probabilities when the environment shifts (e.g., rain, weekday vs weekend). Think of it as a human analyst who says, “Okay, given it’s raining, bump transit and ride‑hail; cut biking.”
Business takeaway: This is an agent pattern you can port beyond cities—insurance triage, retail route planning, even customer‑support next‑best‑action—anywhere actions depend on similar people, similar situations + current context.
How the Preference Chain is built
- BDI Behavior Graph. Nodes: Agent, Person, Desire, Intention. Edges (weighted 0–1): relative_of, similar_to, want_to, choose_to.
- Similarity & Subgraphing. Embed profiles with a modern text‑embedding model; do cosine‑sim to find “nearest” people; run a depth‑first expansion (depth≈3) to pull in desires and intentions they actually chose.
- Path‑score Priors. For each candidate intention i, sum products of edge weights along all simple paths from agent → i (up to length K). Normalize across i to get a choice prior.
- LLM Remodeling. Treat those priors as Bayesian‑like starting beliefs; prompt the LLM with live context to nudge the distribution (e.g., from fair‑weather biking to rainy‑day transit) and sample an action.
Think “graph‑conditioned logits” before the LLM writes a sentence.
Do the numbers move?
- Traffic flow realism: In a 24‑hour, 1,000‑agent Cambridge sim, Preference‑Chain agents reduce distributional divergence vs ground truth and pick the right spine (Mass Ave) more often than LLM‑only agents.
- Data‑scarce edge: With ≈50–100 reference samples, the Preference Chain consistently beats LLM‑only, and competes well with classical ML. Past ~100 samples, an MLP starts to win—expected once you have enough labeled data.
- Cross‑city transfer: Training priors on San Francisco and applying to Cambridge (and vice‑versa) still helps over LLM‑only, though not as much as local data. Useful for new towns with no logs.
A simple way to think about “what to use when”
| Data you actually have | Structure you can encode | Best default |
|---|---|---|
| Tiny (≤50 cases) | Medium (you know actors, desires, options) | Preference Chain (Graph priors + LLM) |
| Small (50–100) | Medium–High | Preference Chain, revisit edge weights & retrieval depth |
| Growing (100–5,000) | Low | MLP / XGB baselines begin to surpass |
| Large (≥10k) | Any | DL sequence/graph models + features; use LLMs for data cleaning & reasoning UIs |
Where this beats common baselines
- vs. Hand‑coded ABM rules: You escape brittle if‑else trees but keep explicit knobs (edge types/weights, depth, path cap) for governance and audit.
- vs. RAG‑only agents: You don’t just retrieve text; you retrieve structured analogues and turn them into probabilities.
- vs. pure LLM agents: You get coherent distributions (not one‑off vibes) and graceful degradation when data is thin.
Sharp edges & how to blunt them
- Latency. Graph expansion + LLM remodeling is slower than ML inference. Tactics: cache subgraphs, memoize priors per cohort, batch remodelings.
- Hallucinations. Keep the LLM’s job minimal: adjust priors, don’t justify long stories; constrain to calibrated deltas; log every prior→posterior change.
- Discrete outputs. Durations and modes are bucketed. If you need continuous travel time, add a post‑step regressor or spline calibrator over the sampled class.
If we productize this at Cognaptus
-
Use case: New‑town demand sketching for a developer or city. Start with public demographics + a few dozen seed diaries; build a Preference Chain per cohort (students, shift workers, caregivers).
-
Stack:
- Graph store: lightweight (SQLite/duckdb + edge tables) or Neo4j if needed.
- Embeddings: one strong OS model for profiles; normalize across cities.
- Choice engine: path enumeration (length cap 3–4), vectorized weight products, softmax normalize.
- LLM gate: a small model is enough; prompt to nudge priors with weather/time/policy toggles.
- Observability: emit priors, context deltas, posteriors; plot cohort‑level KLD/MAE nightly.
-
Deliverables: hourly OD maps, mode shares by cohort, POI visit heatmaps, what‑if toggles (bike‑lane added, bus headway cut, storm day).
One‑page mental model
- Start grounded (graph‑scored priors from real analogues).
- Contextualize (LLM tweaks the prior under today’s conditions).
- Constrain & log (keep adjustments small, visible, reproducible).
That’s how you get agents that feel human and stay plannable.
Footnote for practitioners: The sweet spot is small‑data planning—when you can encode a sensible BDI schema and harvest ~50–100 real analogues per cohort. Beyond that, hand the wheel to ML, and keep the LLM as your reasoning UI.
Cognaptus: Automate the Present, Incubate the Future