TL;DR
Today’s long-context and RAG systems scale storage, not thinking. Cognitive Workspace (CW) reframes memory as an active, metacognitive process: curate, plan, reuse, and consolidate. In tests, CW reports ~55–60% memory reuse and 17–18% net efficiency gains despite a 3.3× operation overhead—precisely because it thinks about what to remember and why.
The Setup: Context ≠ Cognition
Over the past 18 months we’ve cheered >1M-token windows and slicker attention kernels. But piling tokens into a context is like dumping files on a desk; it’s storage without stewardship. In knowledge work, what moves the needle is not how much you can “see” but how well you organize, recall, and reuse—with intent.
The paper we examine proposes Cognitive Workspace, an architecture that elevates memory from a passive database into an active cognitive partner. Concretely, CW formalizes:
- Active memory management (anticipate information needs; prioritize; forget) and a loop for deliberate reuse and consolidation.
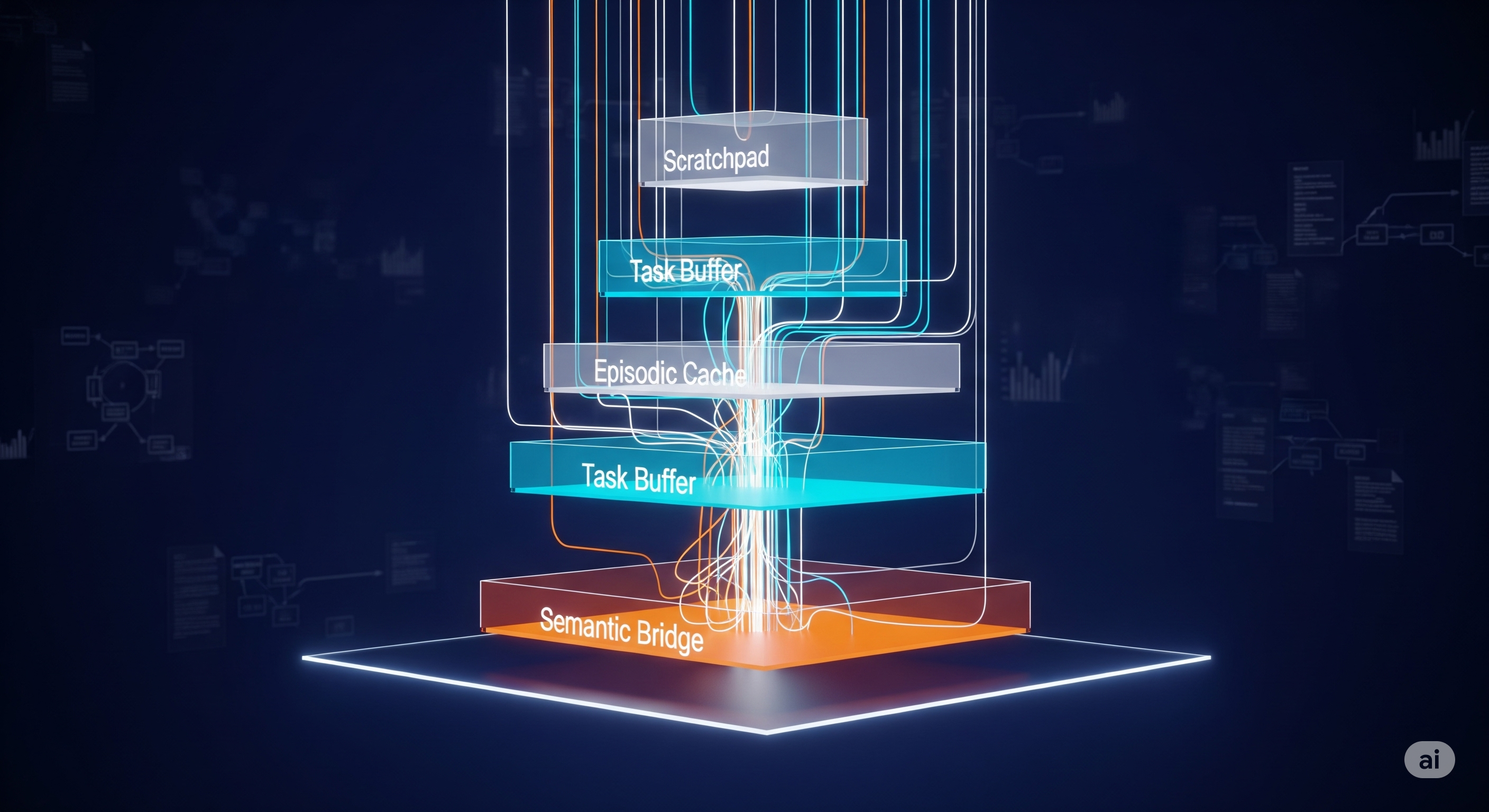
- Hierarchical cognitive buffers (immediate scratchpad, task buffer, episodic cache, semantic bridge) with tailored retention and access patterns.
- Task-driven context optimization that switches attention modes and compute depth as the job evolves.
This is less “give me chunks” and more “maintain a working state and plan memory as a resource.”
Why This Matters for Business Builders
For enterprise AI, cost and reliability hinge on three questions:
- Do we keep paying to rediscover the same facts? CW’s reuse-first design aims to amortize knowledge across turns and sessions. In experiments, CW shows ~55–60% reuse and sub-linear ops growth versus linear baselines.
- Can the system stay coherent over multi-week projects? The architecture’s episodic and semantic layers preserve reasoning chains and context, enabling continuity—not just per-turn retrieval.
- Does it actually pay back in efficiency? Despite 3.3× more operations for active management, net savings land at ~17–18%, with p < 0.001 significance and very large effect sizes across tasks.
Quick Contrast
| Capability | Long-Context LLM | Classic RAG | Cognitive Workspace |
|---|---|---|---|
| Memory agency | None (passive attention) | Reactive retrieval | Active curation, anticipatory retrieval, adaptive forgetting |
| Working state | No persistence | Stateless across turns | Persistent, evolving problem representation |
| Buffers | Single window | External DB + chunks | Scratchpad / Task / Episodic / Semantic tiers |
| Ops growth | Often linear with tokens | Linear with queries | Sub-linear via reuse |
| Reported outcomes | N/A for reuse | N/A for reuse | ~55–60% reuse; ~17–18% net efficiency |
| Metacognition | None | None | Explicit controller & policies |
Sources: architecture and outcomes as reported in the paper’s design and experiments.
Under the Hood: How CW “Thinks About Memory”
Algorithmic loop: decompose tasks → predict info needs → check for reuse → retrieve if missing → update cognitive state → consolidate. That planning posture is the difference between a notebook you search and a colleague who remembers the plan.
Buffers with roles:
- Immediate scratchpad (8K) for high-frequency reasoning, task buffer (64K) to hold problem state, episodic cache (256K) for session history, semantic bridge (1M+) to connect to external knowledge.
Attention as a dial, not a switch: a controller shifts between Focused / Scanning / Integration / Consolidation modes; a Mixture‑of‑Depths router routes hard steps down deeper stacks. Translation: compute where it counts, not everywhere.
Memory lifecycle: selective consolidation, anticipatory retrieval, and controlled forgetting implement a functional infinite context—bounded hardware, unbounded utility.
Do the Numbers Hold Water?
The authors evaluate against a classic RAG baseline on multi‑turn dialogue, multi‑hop reasoning, and conflict resolution. Results are directional but notable:
- Reuse: ~54–60% (4–10 rounds, multi-hop, conflict tasks).
- Efficiency: 17–18% net after accounting for ~3.3× ops overhead.
- Stats: t(18)=69.6, p<0.001, Cohen’s d ranging from 23 to nearly 196 depending on task. (Huge effect sizes; treat cautiously given small-scale setup.)
Caveats: The corpus is small (8 docs), the stack uses GPT‑3.5‑turbo, and runs top out at ~10 rounds—so we’d treat the figures as promising but early. Scaling to enterprise workloads (thousands of docs, weeks-long projects) remains an open test.
What We’d Do Differently in Production
- Treat memory like a quota-managed resource. Put policy around what’s kept, what’s compressed, and what’s evicted—measured by reuse yield per token stored.
- Instrument for memory ROI. Track “retrievals avoided,” “latency saved,” and “duplicate tool calls avoided” per task and user. Tie to $/request.
- Make the workspace a first‑class API. Expose episodic state and task graphs so downstream tools (CRM, BI, code repos) can both read and write memory with guardrails. The paper sketches an MCP‑style integration; we’d push this into policy + audit.
- Shared workspaces with tenancy. The multi‑agent angle needs isolation semantics, lineage, and rollback. Treat it like a data lakehouse for thoughts.
- User‑tunable forgetting. Surface “pin,” “snooze,” and “expire” controls to align with human workflows (people do forget on purpose).
Where This Fits in Our Ongoing Debate
We’ve argued before that RAG is table stakes and planning is necessary but insufficient. CW threads the needle: it borrows the best of planning agents (ReAct/ToT) but binds them to a persistent, reusable working state. It’s the difference between a clever conversation and a memoryful collaborator. The qualitative distinction the paper draws—passive vs active memory—is the right obsession for the next 12 months.
Executive Checklist (to pilot CW in your org)
- Pick a narrow, high‑drag process (e.g., policy Q&A over evolving standards) where reuse is plausible.
- Define memory KPIs: reuse rate, avoided retrievals, saved tool calls, sub-linear ops growth.
- Stand up tiered buffers with conservative quotas; log reuse hits and misses.
- Add metacognitive hooks: before/after steps must state what will be remembered or discarded and why.
- Run A/Bs over 2–4 weeks; look for sub-linear growth curves as the system “settles.”
Bottom Line
Bigger windows won’t make models thoughtful. Active, policy‑driven memory—with persistence, consolidation, and selective forgetting—can. The early data isn’t definitive, but it’s compelling enough to change how we design enterprise AI systems this year.
Cognaptus: Automate the Present, Incubate the Future