TL;DR for operators
Galaxy is best read as a design argument, not merely a new agent benchmark entry. The paper says personal agents cannot become genuinely useful by stacking tools under a chat window. They need a structured internal map of the user, their own capabilities, available environments, and the system logic behind those capabilities.1
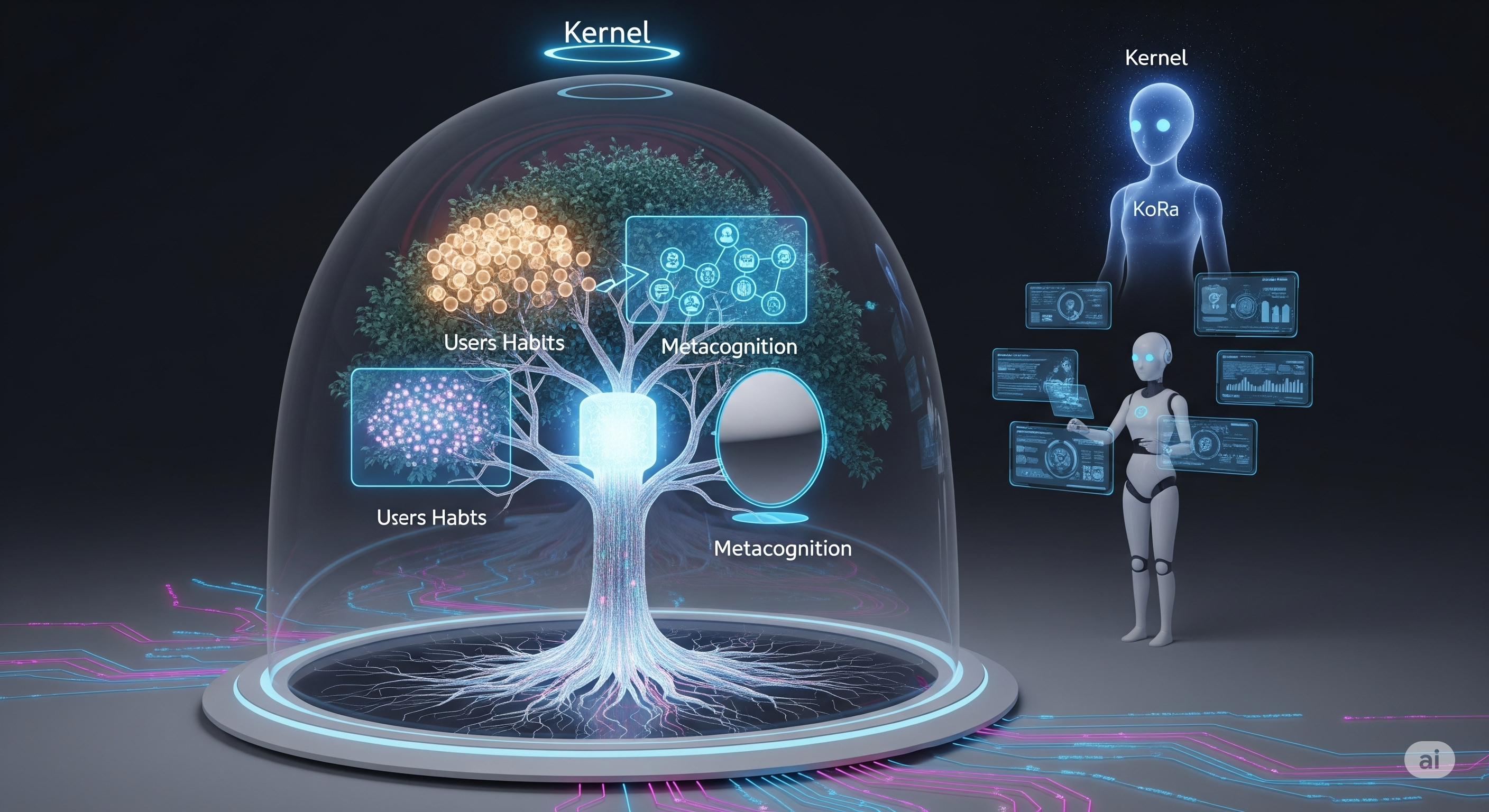
The mechanism is called Cognition Forest. It connects semantic understanding, callable functions, and implementation design in one tree-like structure. That matters because an agent that understands “send email” as a concept, a tool, and a piece of system design can do more than call an API. It can detect missing context, recover from failures, and decide when current tooling no longer fits the user’s routine.
Galaxy turns that architecture into two cooperating agents. KoRa is the user-facing assistant: it responds to instructions, follows plans, retrieves relevant cognition, constructs action chains, and asks for missing information when required. Kernel is the meta-agent: it monitors execution, manages privacy through masking and demasking, generates or modifies Spaces, and performs limited self-repair when the system breaks.
The paper reports strong results across AgentBoard, PrefEval, and PrivacyLens. The most operationally important result is not that Galaxy wins many columns in a table. It is that removing Kernel leaves general task performance largely intact but badly weakens preference retention and privacy protection. In the authors’ benchmark table, PrefEval zero-shot preference retention improves from 11.0% without Kernel to 94.0% with Kernel, while PrivacyLens leakage rate drops from 50.5% to 18.5%.
For businesses, the implication is clear enough: the next useful agent will not be “a chatbot with more integrations”. It will look more like a governed workflow organism: sensing routines, modelling preferences, generating tools, executing actions, masking sensitive data, and recovering from predictable failures. That is attractive. It is also dangerous if deployed with the usual “move fast and hope the compliance team is busy” energy.
The boundary is equally clear. Galaxy is a prototype-style research system evaluated through benchmarks, latency tests, ablations, and case studies. It does not prove enterprise readiness. A production version would still need permissioning, audit logs, approval policies, security review, privacy classification tests, data residency controls, rollback mechanisms, and hard limits on autonomous action.
The familiar problem: assistants wait too politely
Most digital assistants are obedient. That is not the same as useful.
A calendar assistant that waits for the user to say “schedule this” is responsive. A travel assistant that books nothing until every field is specified is safe, in the narrow sense that furniture is safe: it will not act without you. Many LLM agents inherit this posture. They can decompose instructions, call tools, and produce polished explanations, but they still live inside the command-response loop.
Galaxy starts from a different assumption. Personal assistance becomes interesting only when the system can notice repeated behaviour, infer a need, generate or select a better interface, and offer help at the right time. In the paper’s running example, a user repeatedly translates academic papers during regular working hours. Galaxy observes the pattern, recognises that the chat window is a clumsy interface for the task, aligns with the user, generates a dedicated translation Space, and later launches it proactively during the relevant period.
That example sounds simple. It is not. To do it properly, the system must answer several questions at once:
| Question | Why it is hard |
|---|---|
| What has the user been doing repeatedly? | Requires multi-source behavioural modelling, not one-off chat memory. |
| Is the pattern stable or temporary? | Requires long-term user modelling and decay, not permanent memory hoarding. |
| Does the current interface fail the user? | Requires metacognition about capability boundaries. |
| What new tool or Space would help? | Requires linking user intent to system design. |
| Can the system act without exposing private data? | Requires contextual privacy handling before cloud inference. |
| What happens when execution fails? | Requires monitoring and recovery, not just an apologetic stack trace. |
This is why the paper’s core contribution is not “proactive AI”. Proactivity is the visible symptom. The more interesting claim is architectural: cognition and system design should reinforce one another.
Cognition Forest is the operating map, not a decorative memory tree
Galaxy’s central structure is the Cognition Forest, a set of semantic subtrees representing different dimensions of the agent’s world. The paper describes four main subtrees:
| Subtree | What it represents | Operational role |
|---|---|---|
Tuser |
The user’s identity, habits, preferences, and behavioural patterns | Supports personalisation and delegated decisions. |
Tself |
Galaxy, KoRa, Kernel, and their roles or capabilities | Lets the system reason about what it can and cannot do. |
Tenv |
Tools, Spaces, interfaces, functions, and perceivable environment | Grounds intent in available operations. |
Tmeta |
Execution pipelines, monitoring, failure handling, and metacognition | Supports oversight, adaptation, and self-repair. |
The neat part is not merely that these trees exist. Plenty of systems keep memory, tool schemas, or user profiles. Galaxy’s unusual move is that each node is represented through three dimensions:
| Node dimension | Meaning | Why it matters |
|---|---|---|
| Semantic | What the node means to the model | Allows natural-language reasoning and routing. |
| Function | What callable operation the node maps to | Allows execution rather than passive memory. |
| Design | How that operation is implemented | Allows Kernel to inspect or adjust system design. |
This is the mechanism that turns the Cognition Forest from a memory store into an operating map. A “write text” node in a Memo Space is not just a phrase. It can connect to a function such as write_text() and to its implementation logic. If a newly added node fails, Kernel can reason about whether the failure comes from an incorrect execution sequence or from the implementation itself.
That is the paper’s sharpest architectural point. An agent that only knows tool descriptions can choose tools. An agent that knows the semantic, functional, and design layers of its own environment can begin to reason about why a tool does not fit, why an action failed, or what new capability should exist.
This is also where the article should resist the easy hype. Galaxy does not prove open-ended self-improvement in the science-fiction sense. It proposes a constrained loop where user cognition can expose unmet needs, Kernel can translate those needs into system design goals, new Spaces can expand capability, and those new structures can then become part of the Cognition Forest. It is self-evolution with scaffolding, not a little software homunculus becoming enlightened in a MacBook.
KoRa turns cognition into action chains
KoRa is the agent users would experience most directly. It supports two modes: responsive assistance when the user asks for something, and proactive assistance when the system has a plan derived from Agenda and Persona.
The paper’s important design detail is the cognition-action pipeline. When KoRa receives an intent or follows a plan, it proceeds through three stages:
- Semantic routing: traverse the Cognition Forest to locate relevant branches such as user, environment, self, or dialogue context.
- Forest retrieval: pull supporting nodes from the relevant subtree based on context, lexical similarity, or inferred relevance.
- Action chain construction: assemble operations such as generating content, aligning missing intent, invoking tools, and producing natural-language feedback.
This matters because it addresses a common failure mode in personal agents: the system moves too quickly from intent to tool call. “Email Don” sounds straightforward until the system needs to know which Don, what tone to use, whether an address is missing, and whether the request duplicates an already scheduled action.
KoRa’s pipeline gives the agent a reason to pause. If a required parameter is absent or node retrieval fails, KoRa suspends the action chain and asks for alignment before resuming. That is not glamorous. It is exactly the kind of unglamorous control logic that separates useful automation from a very confident intern with root access.
The paper also notes that KoRa maintains only a subset of the Cognition Forest for privacy isolation. Its working forest includes the user cognition tree, KoRa’s own self-model, the environment KoRa can interact with, and dialogue fallback. This matters because Galaxy does not simply dump all internal context into every cloud call. The architecture at least tries to separate what the assistant needs from what the full system knows.
Kernel is where the paper becomes operationally interesting
KoRa is the butler. Kernel is the facilities manager, security officer, and occasional mechanic. Quietly, that is where much of the practical value sits.
Kernel has three jobs.
First, it oversees execution. It monitors Galaxy’s pipelines, including LLM calls across layers, and watches KoRa’s task behaviour. When it detects abnormal patterns, it can trigger meta-reflection and predefined failure-handling routines.
Second, it performs user-adaptive system design. When long-term behaviour indicates an unmet need, Kernel can confirm the need with lightweight alignment and then modify or extend relevant Spaces. This is how the paper’s translation example moves from repeated chat-window usage to a dedicated translation Space.
Third, it manages contextual privacy. Kernel maintains an autonomous avatar aligned with the User Cognition Tree and uses an LLM-based Privacy Gate before cloud transmission. The Privacy Gate applies masking at four levels, from lighter masking to stricter anonymisation across more attributes, then selectively demasks returned results for downstream use.
This is the point where a likely misconception needs to be killed cleanly. “Privacy-preserving” here does not mean no sensitive data ever touches a cloud-adjacent workflow. The paper’s design is based on masking before transmission and demasking after response. That can reduce leakage, but it depends on correct privacy classification, appropriate masking level, secure local handling, and safe restoration. In production, each of those verbs would need a test plan, not just a diagram.
Still, Kernel gives the architecture its spine. Without it, Galaxy is closer to a capable cognition-guided agent. With it, the system gains memory maintenance, privacy gating, user-adaptive capability growth, and recovery routines. The benchmark results support that distinction.
The benchmark table is less about winning and more about Kernel’s job description
The paper evaluates Galaxy across three public benchmarks and one ablated version, Galaxy without Kernel. The setup matters: the experiments use a local Kernel model, Qwen2.5-14B, and a cloud KoRa model, GPT-4o-mini, running on an M3 Max macOS platform, with averages over 100 trials.
The results are broad, but not all columns are equally informative. The article’s main business interpretation should focus on what changes when Kernel is removed.
| Evidence item | Likely purpose | What it supports | What it does not prove |
|---|---|---|---|
| AgentBoard comparison | Main evidence for multi-round agent task performance | Galaxy performs strongly on selected multi-turn task metrics; Kernel removal does not materially hurt the reported AgentBoard scores. | It does not prove robust performance across an enterprise’s proprietary workflows. |
| PrefEval comparison | Main evidence for preference retention | Kernel appears central to long-term preference retention, especially under zero-shot conditions. | It does not prove stable memory governance over months of real use. |
| PrivacyLens comparison | Main evidence for privacy norm handling | Privacy Gate substantially lowers reported privacy leakage compared with Galaxy without Kernel. | It does not prove compliance-grade privacy protection. |
| Latency and model-size analysis | Sensitivity and implementation evidence | Larger local models improve intent extraction but raise latency, especially in Space Design. | It does not settle deployment economics at scale. |
Missing PYTHONPATH recovery case |
Qualitative implementation detail | Kernel can use system-design awareness to repair a concrete setup failure. | It does not prove general autonomous debugging competence. |
| Agenda/Persona ablation | Ablation evidence | Analysis-layer modules help KoRa produce structured plans and interpret repeated behaviour across tools. | It does not quantify long-term behavioural drift in messy real environments. |
On AgentBoard, Galaxy and Galaxy without Kernel both reach the same reported score on ALF, 88.4, and show the same or near-identical numbers across several task categories. That tells us something important: Kernel is not mainly adding raw multi-step task ability in this table. KoRa plus the Cognition Forest already provides strong task execution.
The more meaningful separation appears in PrefEval and PrivacyLens. Without Kernel, Galaxy reports 11.0% on the PrefEval Z300 condition. With Kernel, the number rises to 94.0%. The paper interprets this as evidence that Kernel’s evolving Cognition Forest supports long-term preference retention and personalised planning even without reminders.
Privacy shows a similar pattern. Galaxy without Kernel reports a PrivacyLens leakage rate of 50.5%. Full Galaxy reports 18.5%. That is a 32-point absolute drop. The result supports the claim that Kernel’s Privacy Gate is doing real work in the benchmark setting.
The business translation is not “buy a Kernel”. Please, let us remain adults. The translation is that memory and privacy cannot be glued on after the assistant is already making decisions. The same layer that tracks preferences and capability boundaries also needs to control what context gets exposed to stronger cloud models. Otherwise, personalisation and privacy are pulling in opposite directions.
The latency results expose the cost of cognition
A system that retrieves cognition, checks privacy, routes intent, and constructs action chains will not be as cheap or fast as a simple API wrapper. The paper’s latency analysis makes that trade-off visible.
For complex tool calls, the reported total latency is 1.34 seconds. The largest component is Kernel cognition retrieval at 0.87 seconds, followed by Kernel calling the Space function at 0.22 seconds, KoRa’s cloud API call at 0.13 seconds, and KoRa feeding back the result at 0.12 seconds.
| Execution route | Cloud API? | Latency |
|---|---|---|
| KoRa calls cloud API | Yes | 0.13s |
| Kernel retrieves cognition | No | 0.87s |
| Kernel calls Space function | No | 0.22s |
| KoRa feeds back result | Yes | 0.12s |
| Overall | — | 1.34s |
This is useful because it reverses a lazy assumption. In many agent discussions, cloud model latency is treated as the main bottleneck. In this setup, the largest slice for a complex tool call is local cognition retrieval. The “thinking infrastructure” costs time.
The model-size analysis sharpens the point. With Qwen2.5-14B as Kernel’s local model, Galaxy reaches a one-shot intent extraction success rate of 81.5%. The larger model is more capable, but Figure 5 also shows that latency increases with larger local configurations, with the 14B setup reaching up to 6.3 seconds on the Space Design task.
That is not a fatal flaw. It is a design budget. Businesses need to decide which tasks deserve cognition-heavy processing and which should remain simple. A weekly workflow redesign can tolerate a few extra seconds. A high-frequency operational approval flow probably cannot. The glamour of “self-evolving cognition” still has to pass through latency, hardware, and cost accounting. How rude of reality.
Spaces are the bridge between interface and cognition
Galaxy’s Spaces are easy to underread. They sound like UI modules. They are more important than that.
A Space wraps a user-facing interaction environment with three components:
| Space component | Role |
|---|---|
| Perception Window | Observes actions and environmental signals, converting them into structured TimeEvent entries and state snapshots. |
| Interaction Component | Provides a user-facing interface or standalone personalised module. |
| Cognitive Protocol | Maps high-level intent into concrete operations and embeds the Space into the Cognition Forest. |
This design makes Spaces cognitively accessible. The agent does not merely call a tool from a list; it understands the Space as part of its environment. That is why a generated translation Space can become part of the system’s future reasoning. Once a new Space exists, it gives Galaxy new perceptual signals, new callable functions, and new cognitive pathways.
For businesses, this is the most practical architectural pattern in the paper. Enterprise agents often fail because tools are integrated technically but not cognitively. The tool exists, but the agent does not know when it is relevant, how it changes the user’s workflow, or whether it should replace an older interaction pattern. Spaces suggest a better abstraction: wrap each recurring workflow as an observable, callable, and semantically described environment.
That is also where governance should attach. A production Space should not just contain functions. It should contain permissions, audit rules, data exposure rules, rollback logic, escalation paths, and human approval thresholds. Galaxy points to the shape of that architecture, even if the paper itself does not solve the enterprise governance layer.
The self-repair case is useful, but it is not magic
The paper includes a real deployment case where the system fails after cloning across devices. Running main.py raises a ModuleNotFoundError because the system cannot locate the world_stage module. Kernel remains operational as a minimal runtime unit, reasons that the module should reside in the project root, infers a missing PYTHONPATH, injects the correct path, restarts execution, and restores operation.
This is a good case study because it shows why design awareness matters. A conventional agent might return the stack trace and ask the user to fix it. Kernel can connect the failure to the system’s structure.
But the case should not be inflated. It is a concrete recovery example, not proof that Kernel can autonomously repair arbitrary production incidents. PYTHONPATH issues are familiar, bounded, and diagnosable. Enterprise failures are often distributed, stateful, permission-related, or caused by partial data corruption. Those are less likely to be solved by a neat local patch.
The right interpretation is narrower and more useful: agents that know implementation design can recover from some predictable structural failures without waiting for a human. That alone has value. It turns a class of minor operational interruptions into self-healing events. The word “minor” is doing responsible work here.
The ablations explain why memory alone is too thin
The paper’s ablation discussion focuses on the Analysis Layer, especially Agenda and Persona. These are not decorative modules. They explain why Galaxy’s proactive behaviour is not simply “remember what the user did last time”.
Without Agenda, KoRa depends heavily on memory-stream context. Plans become less structured and require more clarification from the user. Agenda matters because it consolidates multi-source perceptual signals into a coherent behavioural profile, which then feeds plan generation.
Persona handles another failure mode. In the paper’s example, a user repeatedly asks KoRa to translate paper abstracts and introductions. Kernel generates a dedicated literature translation Space. On a later day, KoRa might incorrectly infer that the user has stopped translating if it only sees that the old chat-window behaviour has disappeared. With Persona available, Galaxy can interpret the new tool usage as continuity rather than abandonment.
That distinction is subtle but important. A weaker agent sees a behaviour disappear. A better agent sees the behaviour migrate into a new interface. In business terms, this is the difference between shallow telemetry and workflow understanding.
What Cognaptus infers for business use
The paper directly shows a prototype architecture, benchmark comparisons, a latency analysis, a recovery case, and ablation evidence. Cognaptus’ business inference is broader: if organisations want useful personal or team agents, they should stop treating memory, privacy, tool use, and workflow adaptation as separate product features.
A practical enterprise version of Galaxy-like thinking would look something like this:
| Technical idea in Galaxy | Operational interpretation | Business relevance |
|---|---|---|
| Cognition Forest | Maintain structured maps of user, agent, environment, and metacognition | Better continuity across workflows and fewer context resets. |
| KoRa cognition-action pipeline | Route intent through relevant user and tool context before acting | Fewer brittle tool calls and fewer missing-parameter failures. |
| Kernel | Separate execution from supervision, privacy, and adaptation | Cleaner governance and more resilient operations. |
| Spaces | Wrap recurring workflows as observable, callable, semantically mapped modules | More useful automation than generic chat-based task execution. |
| Privacy Gate | Mask sensitive context before cloud inference and demask afterward | Potential leakage reduction, if classification and controls work. |
| Agenda and Persona | Combine schedules, observed behaviours, and long-term user cognition | Better proactivity without constant manual prompting. |
| Self-repair routines | Use system-design awareness to recover from bounded failures | Reduced support burden for predictable operational issues. |
The ROI pathway is not “the agent gets smarter”. That phrase should be banned from vendor decks for at least one fiscal year.
The actual pathway is more concrete:
- Recurring user behaviours become structured signals.
- Structured signals reveal repeated friction.
- Repeated friction triggers a new Space or workflow adaptation.
- The new Space reduces manual steps.
- Kernel monitors execution, privacy exposure, and failure conditions.
- The adapted workflow becomes part of future cognition.
This is where value may emerge: reduced repetitive work, better continuity, fewer clarification loops, and faster workflow customisation. The gains are plausible in knowledge work where users repeatedly perform similar actions across documents, schedules, email, research, reporting, or administrative systems.
The risk is also obvious. A system that observes behaviour, models preferences, and proposes actions is a governance problem wearing a productivity hat.
The boundary: privacy masking is not compliance
Galaxy’s Privacy Gate is one of the paper’s strongest practical ideas, but it should not be mistaken for a compliance programme.
The paper’s design uses contextual masking before transmitting data to a cloud model, then demasking after results return. It reports a substantial reduction in PrivacyLens leakage rate. That is encouraging. It is not the same as proving safety for regulated environments.
A production deployment would need answers to questions the benchmark does not settle:
| Deployment question | Why it matters |
|---|---|
| Who decides the masking level? | Incorrect risk classification can expose sensitive attributes or over-mask useful context. |
| Where are mask mappings stored? | Demasking requires local mappings that become sensitive assets themselves. |
| Can users inspect what was sent? | Auditability matters for trust, compliance, and incident response. |
| What actions require approval? | Proactive agents need hard boundaries around spending, sending, deleting, signing, and disclosing. |
| How is drift detected? | User preferences and behaviours change; stale cognition can produce confident misalignment. |
| What is the rollback model? | Generated Spaces and self-repair patches need versioning and reversibility. |
| How are permissions scoped? | A Space that can read documents should not automatically gain permission to email, export, or publish them. |
The paper’s own limitations point in the same direction. It identifies alignment overfitting, where short-term alignment inputs may be overweighted and fail to reflect long-term habits. It also notes human-dependent Space expansion, meaning complex Spaces may still require multiple rounds of human guidance despite automated extensibility.
Those are not minor footnotes. They define where the architecture must be strengthened before serious deployment.
The strategic lesson: stop separating the mind from the machinery
Galaxy’s best idea is not that agents should be proactive, private, or self-evolving. Everyone wants those adjectives now. The useful idea is that these capabilities are interdependent.
A proactive agent needs behaviour modelling. Behaviour modelling creates privacy risk. Privacy risk requires contextual masking. Contextual masking requires metacognition about what information is needed. Metacognition is stronger when the system understands its own design. System-design understanding enables new Spaces. New Spaces change future behaviour signals. The loop closes.
That is why a mechanism-first reading matters. A module-by-module summary makes Galaxy sound like another agent framework with a forest metaphor and a confident benchmark table. The mechanism reveals the deeper claim: a personal agent’s cognition should include the system that implements that cognition.
For operators, the near-term lesson is not to rebuild Galaxy tomorrow morning. The lesson is to evaluate agent platforms by asking harder architectural questions:
- Does the agent know only the tool schema, or also the workflow context around the tool?
- Is user memory connected to action policy, or merely appended to prompts?
- Is privacy handled before cloud inference, or only promised in the privacy policy?
- Can the agent recognise when a workflow should become a dedicated interface?
- Can supervision and execution be separated cleanly?
- Can generated capabilities be audited, permissioned, rolled back, and retired?
If the answer is no, the system may still be useful. It is just not the kind of self-evolving personal agent Galaxy is pointing toward.
The forest is a governance problem before it is a productivity miracle
Galaxy offers a credible research direction for the next generation of personal agents. It moves beyond chat responsiveness toward systems that sense routines, maintain structured cognition, generate workflow-specific Spaces, protect context through masking, and repair bounded failures.
The paper’s benchmark results are strongest where Kernel’s role is most visible: preference retention and privacy leakage. The latency analysis usefully shows that cognition has a cost. The ablations explain why Agenda and Persona matter. The recovery case makes system-design awareness tangible.
The business implication is therefore neither hype nor dismissal. Galaxy is not enterprise-ready just because it performs well on selected benchmarks. But it does show what enterprise agents will probably need: not bigger prompts, but better internal organisation; not more integrations, but cognitively mapped workflows; not vague privacy assurances, but contextual data controls; not “autonomy”, but supervised adaptation.
The agent of the future may indeed have a forest within. Sensible organisations will make sure it also has fences.
Cognaptus: Automate the Present, Incubate the Future.
-
Chongyu Bao et al., “Galaxy: A Cognition-Centered Framework for Proactive, Privacy-Preserving, and Self-Evolving LLM Agents,” arXiv:2508.03991, 2025. https://arxiv.org/abs/2508.03991 ↩︎