Modern oncology is an overwhelming cognitive battlefield: clinicians face decades of fragmented notes, tests, and treatment episodes, scattered across multiple languages and formats. Large Language Models (LLMs) promise relief—but without careful design, they often collapse under the weight of these chaotic Electronic Health Records (EHRs), hallucinate unsafe recommendations, or fail to reason over time.
Enter CliCARE: a meticulously designed framework that not only tames this complexity but grounds the entire decision process in clinical guidelines. Rather than stuffing raw records into long-context transformers or bolting on retrieval-augmented generation (RAG), CliCARE introduces a radically more structured approach.
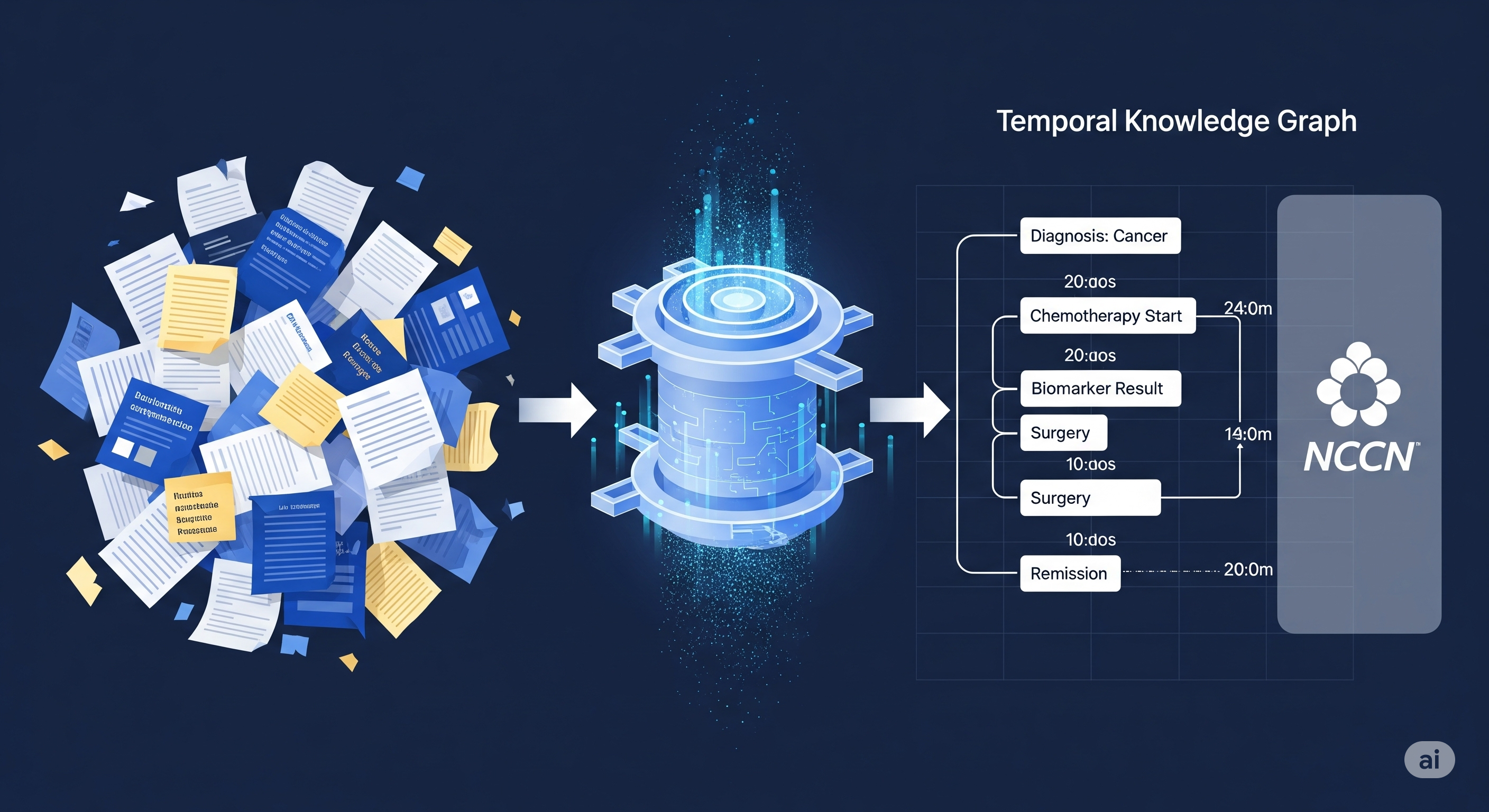
📐 The Architecture: From Raw Notes to Guideline-Aligned Knowledge
CliCARE transforms messy, multi-year cancer EHRs into structured Temporal Knowledge Graphs (TKGs). Here’s how it works:
- Compression via Longformer: Raw clinical notes are summarized into two narratives—past history and current illness—preserving critical information.
- Event Extraction: These summaries are parsed into discrete clinical events with time stamps.
- TKG Construction: Events are embedded into a graph structure using standard biomedical ontologies. This TKG captures disease progression over time.
But that’s just half the magic. The next step? Guideline alignment.
- A static knowledge graph of normative treatment paths (e.g., from NCCN guidelines) is created.
- Each patient trajectory is aligned to these guideline paths using BERT-based semantic similarity, then refined by an LLM-based reranker and bootstrapped expansion.
This creates a tightly fused context where each patient’s journey is mapped to best-practice expectations—a feat that standard RAG pipelines simply can’t achieve.
⚖️ Why This Matters: Evaluation with Clinical Muscle
Medical AI isn’t just about fluency—it’s about safety, soundness, and relevance. CliCARE raises the bar here too, proposing a LLM-as-a-Judge evaluation protocol that:
- Uses an ensemble of GPT-4.1, Claude 4.0, and Gemini 2.5 for scoring.
- Validates these ratings against senior oncologists, achieving Spearman correlations around 0.7.
The rubric doesn’t stop at ROUGE—it asks: Is the summary accurate? Are the recommendations actionable? Would an oncologist trust this?
📊 Results: Not Just Better, But Safer
Across two datasets—China’s private CancerEHR (20,000-token records) and the public English MIMIC-Cancer set—CliCARE consistently outperformed both vanilla RAG and KG-enhanced RAG (like MedRAG or KG2RAG).
Here’s a summary of the gains:
| Model | Dataset | Standard RAG | CliCARE | Gain |
|---|---|---|---|---|
| Qwen-3-8B | CancerEHR | 1.49 / 1.53 | 3.17 / 3.21 | +1.68 |
| Gemini-2.5-Pro | CancerEHR | 2.74 / 2.82 | 4.98 / 4.97 | +2.24 |
| GPT-4.1 | MIMIC-C | 4.42 / 4.43 | 4.74 / 4.68 | +0.32 |
(Scores are Clinical Summary / Recommendation, per LLM judge)
🔬 Beyond Benchmarks: Lessons for AI Safety in Healthcare
CliCARE’s success isn’t just in better numbers—it’s in the philosophy:
- Structure over scale: Compressing long EHRs into temporal graphs beats brute-force context windows.
- Process grounding > fact retrieval: Clinical safety depends not just on what was said, but when and why.
- Rigor in evaluation: Ground-truthing with human experts is still essential, especially for open-ended generation.
This framework is a blueprint for other domains—law, finance, education—where unstructured history meets structured guidance.
Cognaptus: Automate the Present, Incubate the Future.