
In the high-stakes world of business process automation (BPA), it’s not enough for AI agents to just complete tasks—they need to complete them correctly, consistently, and transparently. At Cognaptus, we believe in treating automation with the same scrutiny you’d expect from a court of law. That’s why we’re introducing CognaptusJudge, our novel framework for evaluating business automation, inspired by cutting-edge research in LLM-powered web agents.
⚖️ Inspired by Online-Mind2Web
Earlier this year, a research team from OSU and UC Berkeley published a benchmark titled An Illusion of Progress? Assessing the Current State of Web Agents (arXiv:2504.01382). Their findings? Many agents previously hailed as top performers were failing nearly 70% of tasks when evaluated under more realistic, human-aligned conditions.
The key innovation wasn’t just a better test—it was a better judge. Their framework, WebJudge, used a large language model (LLM) to mimic how a human evaluator would judge success, using action history, intermediate screenshots, and explicit task criteria.
This shift—from rule-based pass/fail scripts to LLM-based human-like evaluation—marks a significant moment in AI evaluation. And it’s exactly the mindset we’re bringing into business automation.
🧠 Enter CognaptusJudge
We’ve adapted that philosophy for business settings. CognaptusJudge is a modular evaluation framework tailored for automated workflows such as invoice approvals, CRM entries, or HR form processing.
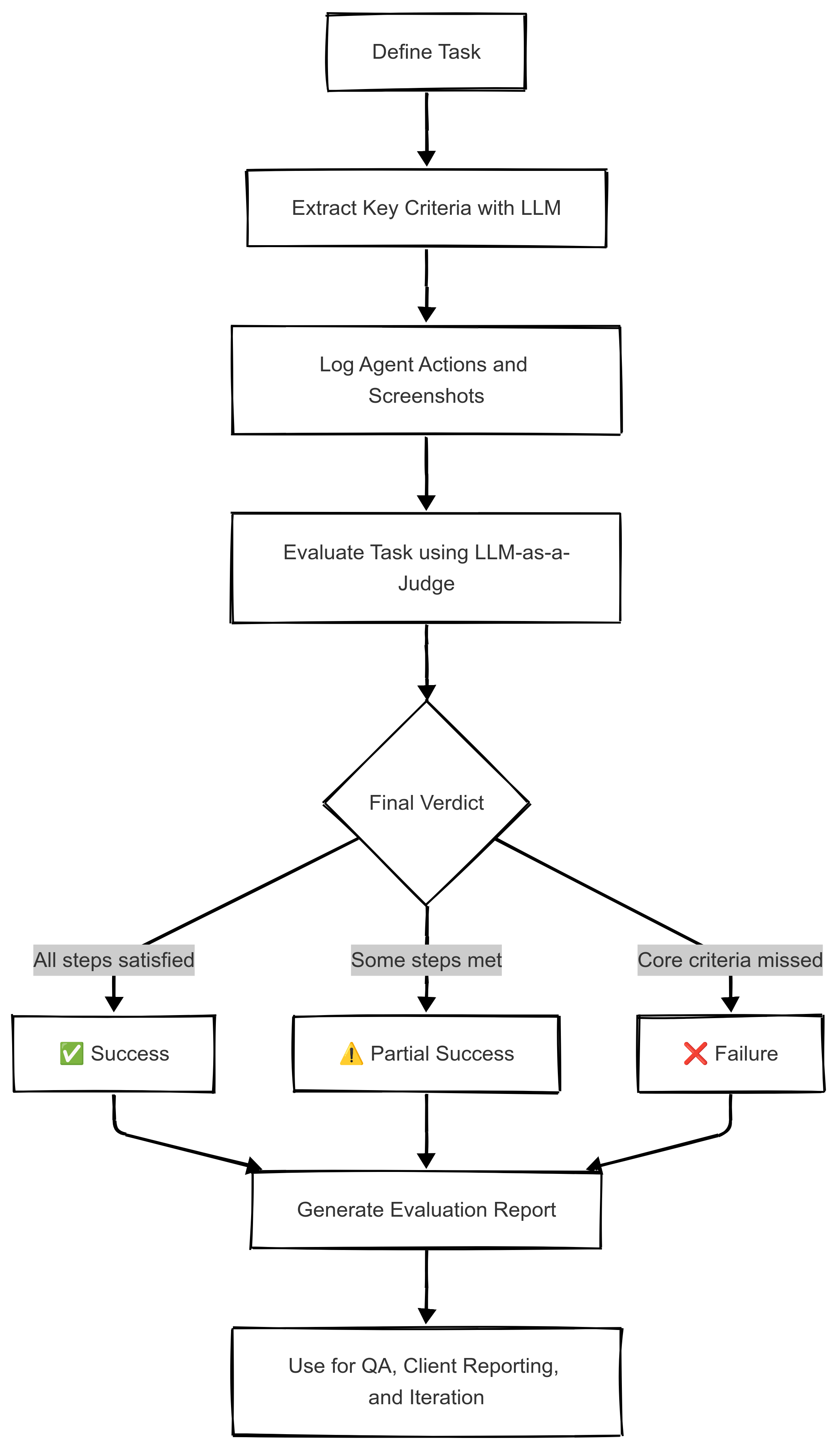
Here’s how it works:
📋 Step 1: Define the Task
The automation goal is written in natural language, like:
“Approve invoices over $500 and email Finance for confirmation.”
🧩 Step 2: Extract Key Criteria
An LLM (e.g., GPT-4) is prompted to extract key steps or constraints:
- Check if amount > $500
- If true, click ‘Approve’
- Send confirmation email to [email protected]
📜 Step 3: Log the Agent’s Behavior
We collect structured logs of what the agent did:
- Actions (clicks, form inputs, API calls)
- Screenshots (optional)
- System messages or responses
🧑⚖️ Step 4: Evaluate with GPT
We feed the task, key steps, and logs into a prompt chain. The LLM acts as a business logic judge, issuing one of:
- ✅ Success
- ⚠️ Partial Success
- ❌ Failure
With reasoning attached.
This mimics how a human reviewer might verify a task—by checking if each requirement was followed and if the end result makes sense—bridging the gap between automated metrics and human expectations.
🔄 Step 5: Analyze Patterns
Just like a judge sets precedent, CognaptusJudge helps us:
- Categorize common failure types (e.g., misapplied filters, skipped confirmations)
- Compare automation performance across workflows
- Generate transparent evaluation reports for clients
📊 CognaptusJudge Flow
💼 Why It Matters for Clients
CognaptusJudge isn’t just an internal QA tool—it’s part of our promise of verifiable performance. Clients using Cognaptus automation gain:
- Auditable results: Every agent action is traceable and evaluable.
- Continuous improvement: We learn from failures and iterate quickly.
- Real-world robustness: No more inflated success claims based on idealized demos.
🚀 What’s Next
We’re integrating CognaptusJudge into our deployment pipelines, and soon, into client dashboards. We’re also exploring open-sourcing a version for broader community use.
Because in the world of AI, it’s not about being the flashiest agent in the courtroom—it’s about having receipts.
Stay tuned for more from Cognaptus Insights as we continue bringing clarity, integrity, and measurable impact to AI automation.