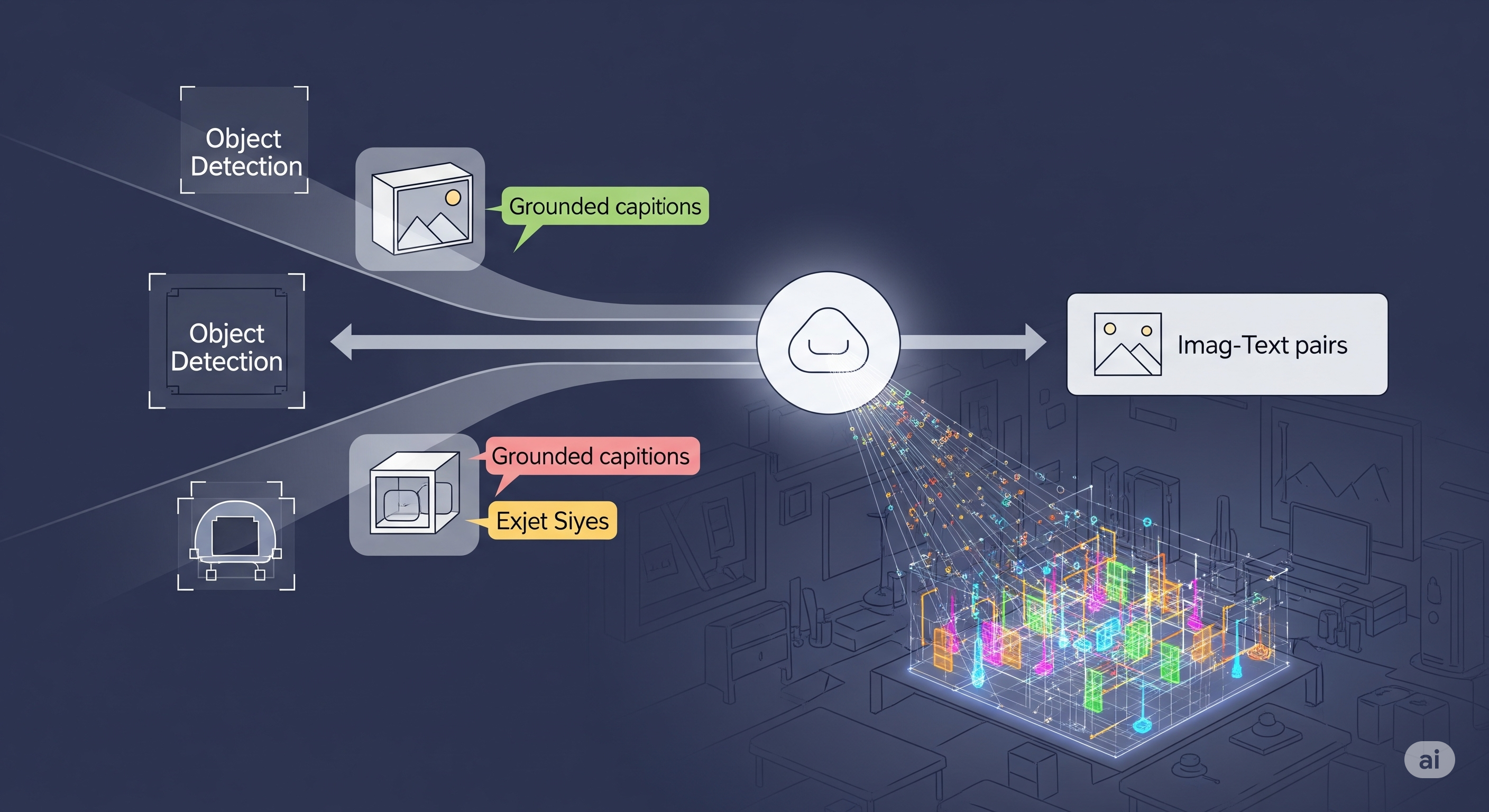
Seeing Is Deceiving: Diagnosing and Fixing Hallucinations in Multimodal AI
TL;DR for operators A multimodal model can look at an image and still answer from memory, habit, or linguistic guesswork. That is the uncomfortable core of visual hallucination: the output is fluent, relevant-looking, and sometimes even useful, while being only loosely attached to the pixels it claims to describe. The practical lesson is not “never use multimodal AI.” That would be tidy, dramatic, and mostly useless. The lesson is narrower and more valuable: visual hallucinations need to be diagnosed by where grounding fails, not merely counted after the model has embarrassed itself. ...