One Model to Train Them All: How OmniTrain Rethinks Open-Vocabulary Detection
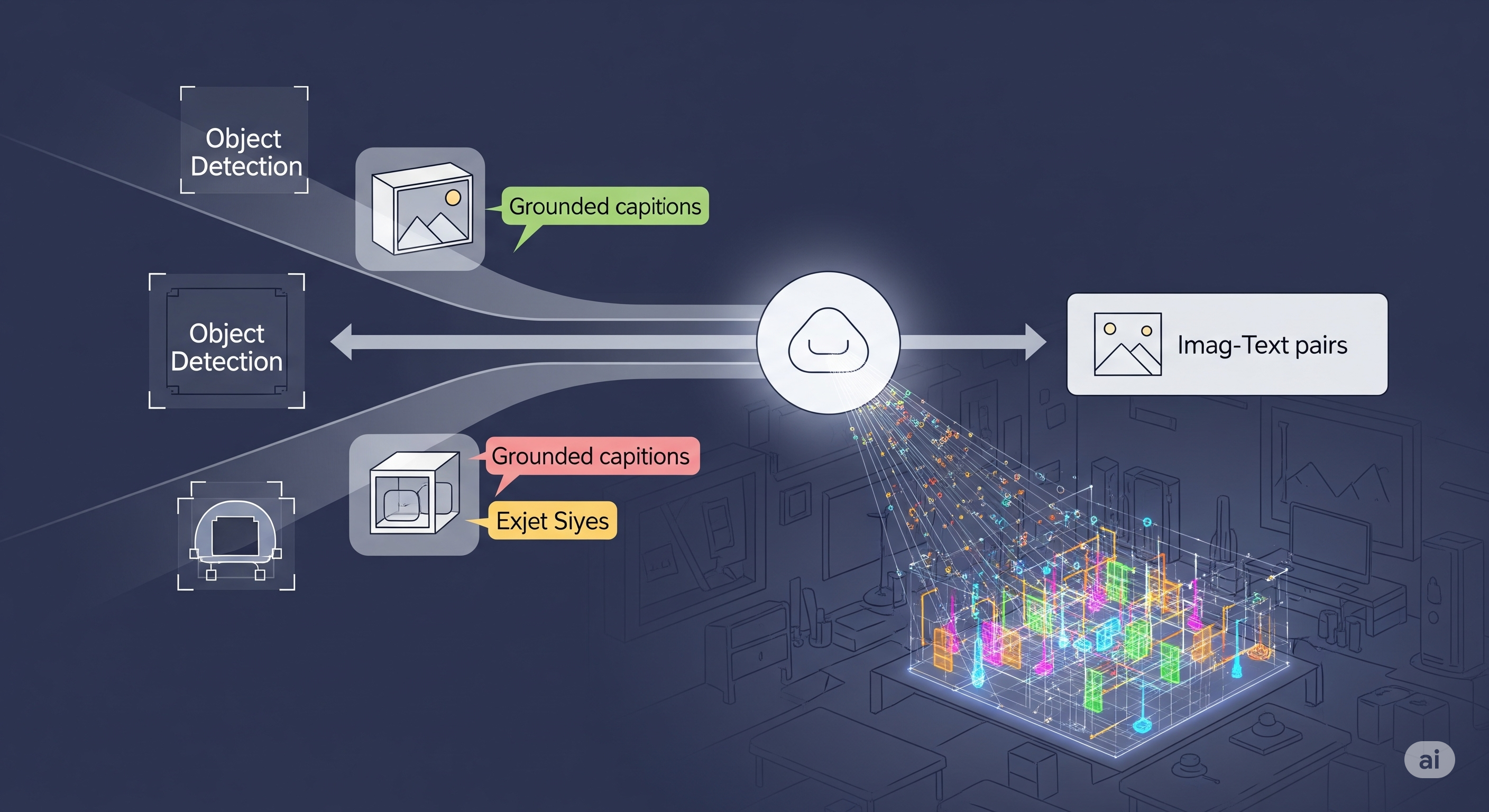
TL;DR for operators OmniTrain’s useful claim is not that open-vocabulary object detection needs a bigger vocabulary, a more theatrical prompt, or yet another detection head with a confident acronym stapled to it. Its claim is simpler and more operational: the training interface is the bottleneck.1 Open-vocabulary detection asks a detector to find categories it may not have seen as boxed labels during training. That promise is attractive for retail shelves, industrial inspection, visual search, robotics, and any business where the object list changes faster than the annotation budget. But many systems still inherit a messy workflow: pre-train a vision-language model, fine-tune a detector, add grounding supervision, reconcile losses, then hope the pieces do not quietly disagree. ...