Speculation, But With Standards: Training Draft Models That Actually Get Accepted
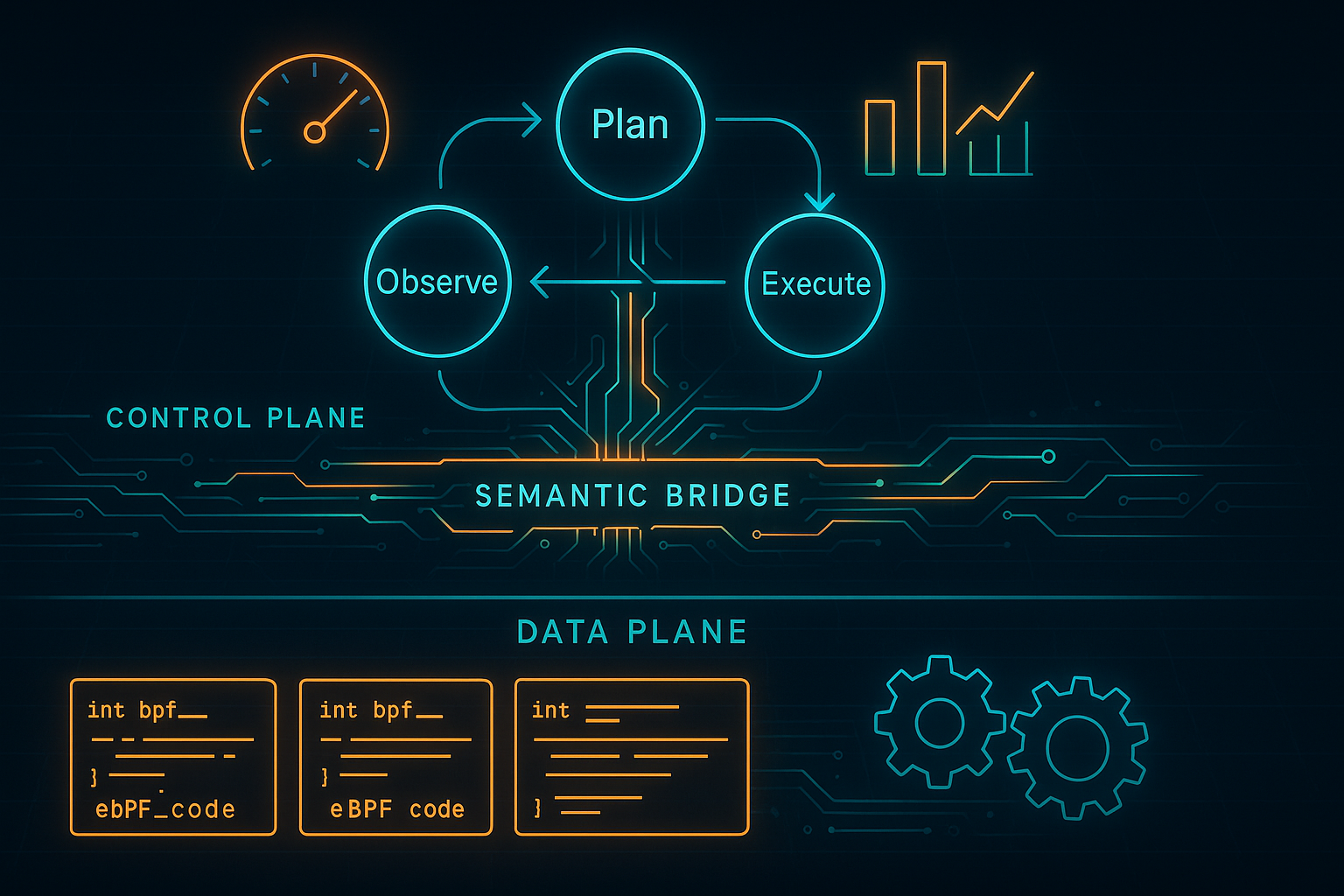
Opening — Why this matters now Speculative decoding has quietly become one of the most important efficiency tricks in large language model inference. It promises something deceptively simple: generate multiple tokens ahead of time with a cheap draft model, then let the expensive model verify them in parallel. Fewer forward passes, lower latency, higher throughput. ...