How to Design Human Review for AI Systems
How to build human review into AI workflows so oversight is meaningful, efficient, and matched to business risk rather than added as decoration.
How to build human review into AI workflows so oversight is meaningful, efficient, and matched to business risk rather than added as decoration.

TL;DR FinCast is a 1B‑parameter, decoder‑only Transformer trained on >20B financial time points with a token‑level sparse Mixture‑of‑Experts (MoE), learnable frequency embeddings, and a Point‑Quantile (PQ) loss that combines Huber point forecasts with quantile targets and a trend‑consistency term. In zero‑shot benchmarks across crypto/FX/stocks/futures, it reports ~20% lower MSE vs leading generic time‑series FMs, and it also beats supervised SOTAs—even without fine‑tuning—then widens the gap with a light fine‑tune. If you build risk or execution systems, the interesting part isn’t just accuracy points; it’s the shape of the predictions (tail‑aware, regime‑sensitive) and the deployment economics (conditional compute via sparse MoE + patching). ...
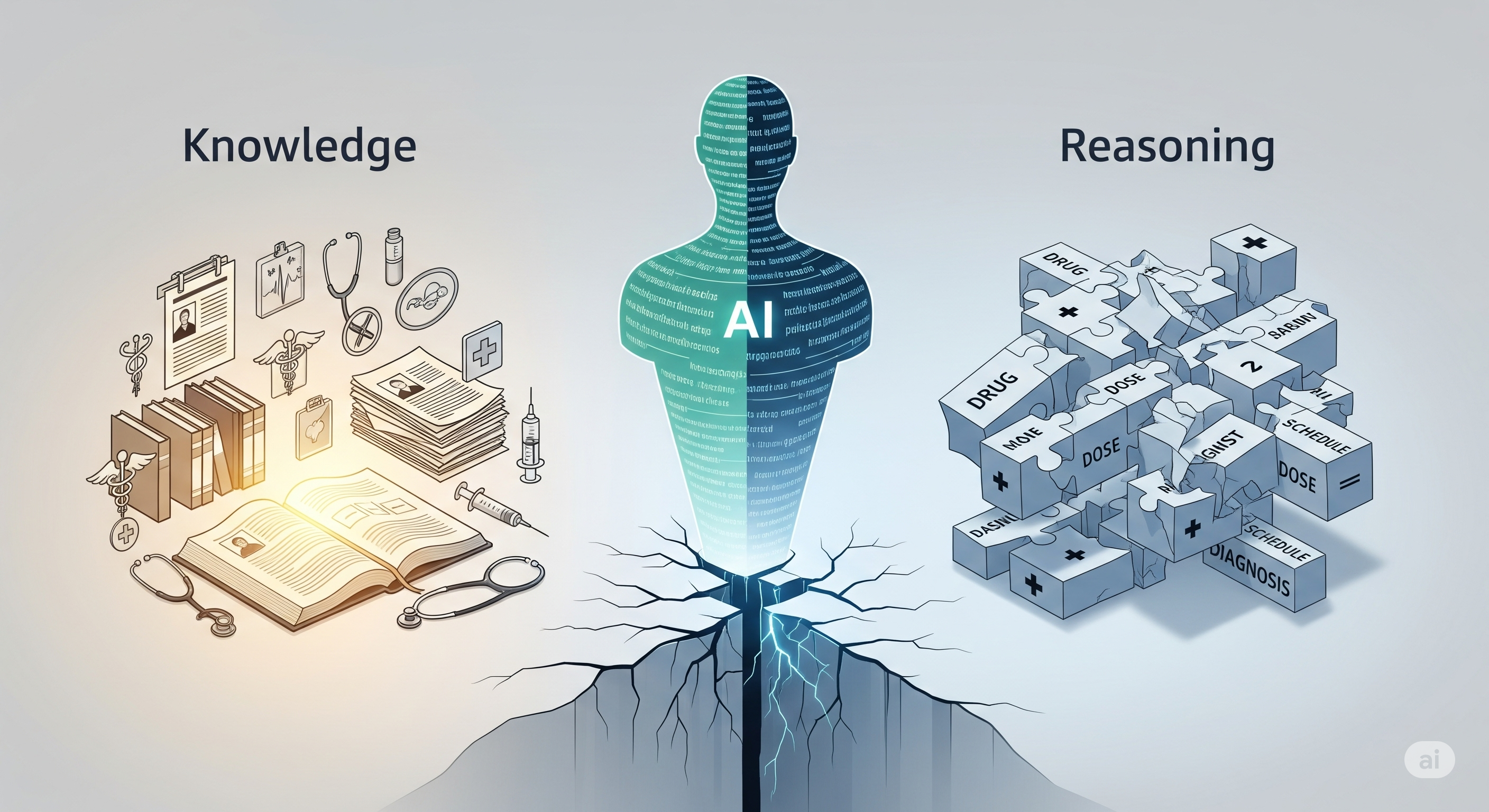
The gist A new clinical natural language inference (NLI) benchmark isolates what models know from how they reason—and the results are stark. State‑of‑the‑art LLMs ace targeted fact checks (≈92% accuracy) but crater on the actual reasoning tasks (≈25% accuracy). The collapse is most extreme in compositional grounding (≈4% accuracy), where a claim depends on multiple interacting clinical constraints (e.g., drug × dose × diagnosis × schedule). Scaling yielded fluent prose, not reliable inference. ...