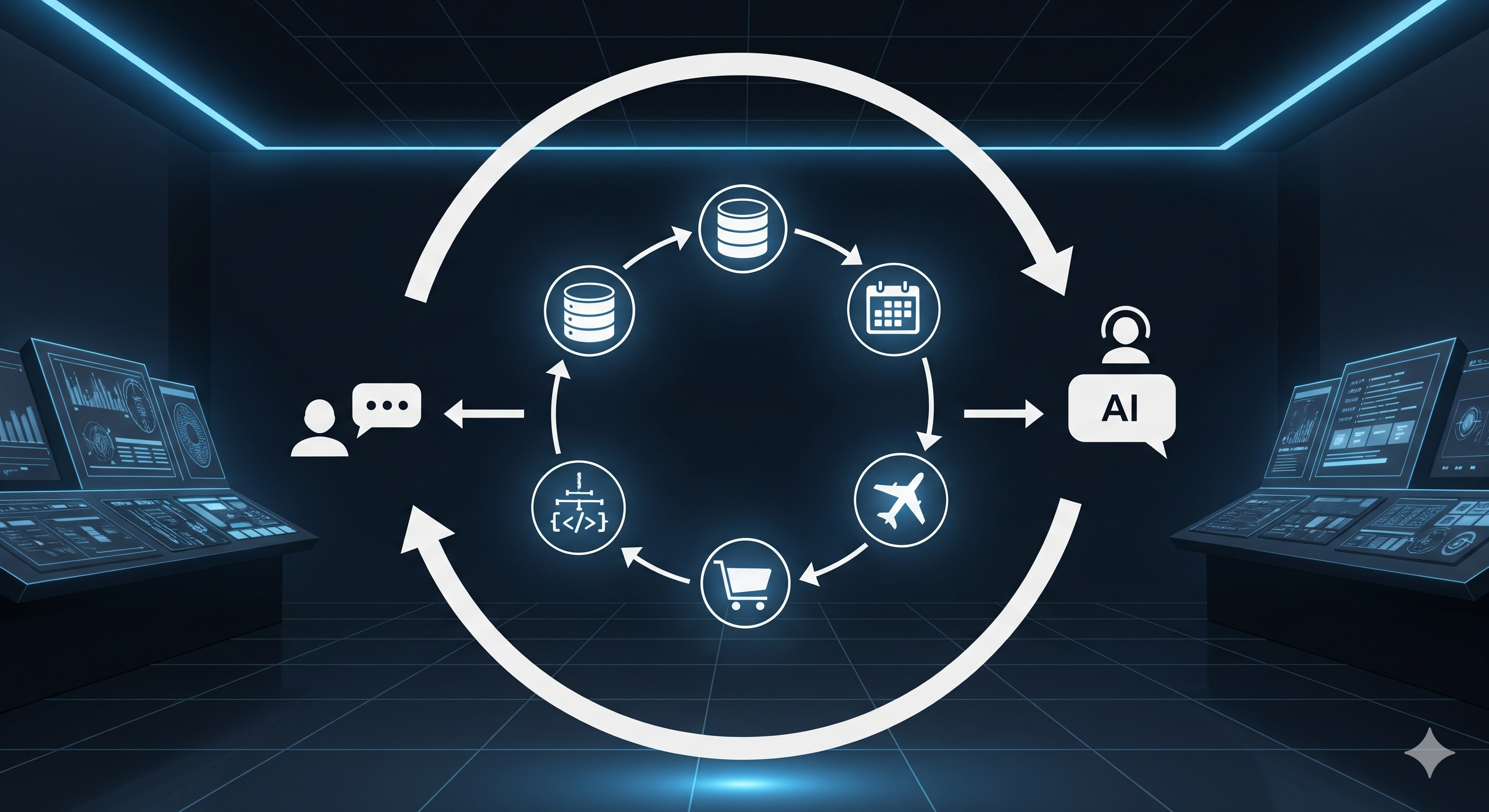
How a new survey formalizes the shift from RLHF’d text bots to tool-using operators—and the practical playbook for product teams.
TL;DR Agentic RL reframes LLMs from one-shot text generators to policies acting in dynamic environments with planning, tool use, memory, and reflection. The paper contrasts PBRFT (preference-based RL fine-tuning) with Agentic RL via an MDP→POMDP upgrade; action space now includes text + structured actions. It organizes the space by capabilities (planning, tools, memory, self-improvement, reasoning, perception) and tasks (search, code, math, GUI, vision, embodied, multi-agent). Open challenges: trust, scalable training, and scalable environments. For builders: start with short-horizon agents (verifiable rewards), invest early in evaluation, and plan a migration path from RAG pipelines to tool-integrated reasoning (TIR) with RL. What the paper actually changes Most “LLM RL” work you’ve seen is PBRFT—optimize responses to fit human/AI preferences (RLHF/DPO/etc.). This new survey argues that real autonomy needs Agentic RL: treat the model as a policy embedded in a sequential, partially observable world. That sounds academic, but the practical consequences are huge:
...