Put It on the GLARE: How Agentic Reasoning Makes Legal AI Actually Think
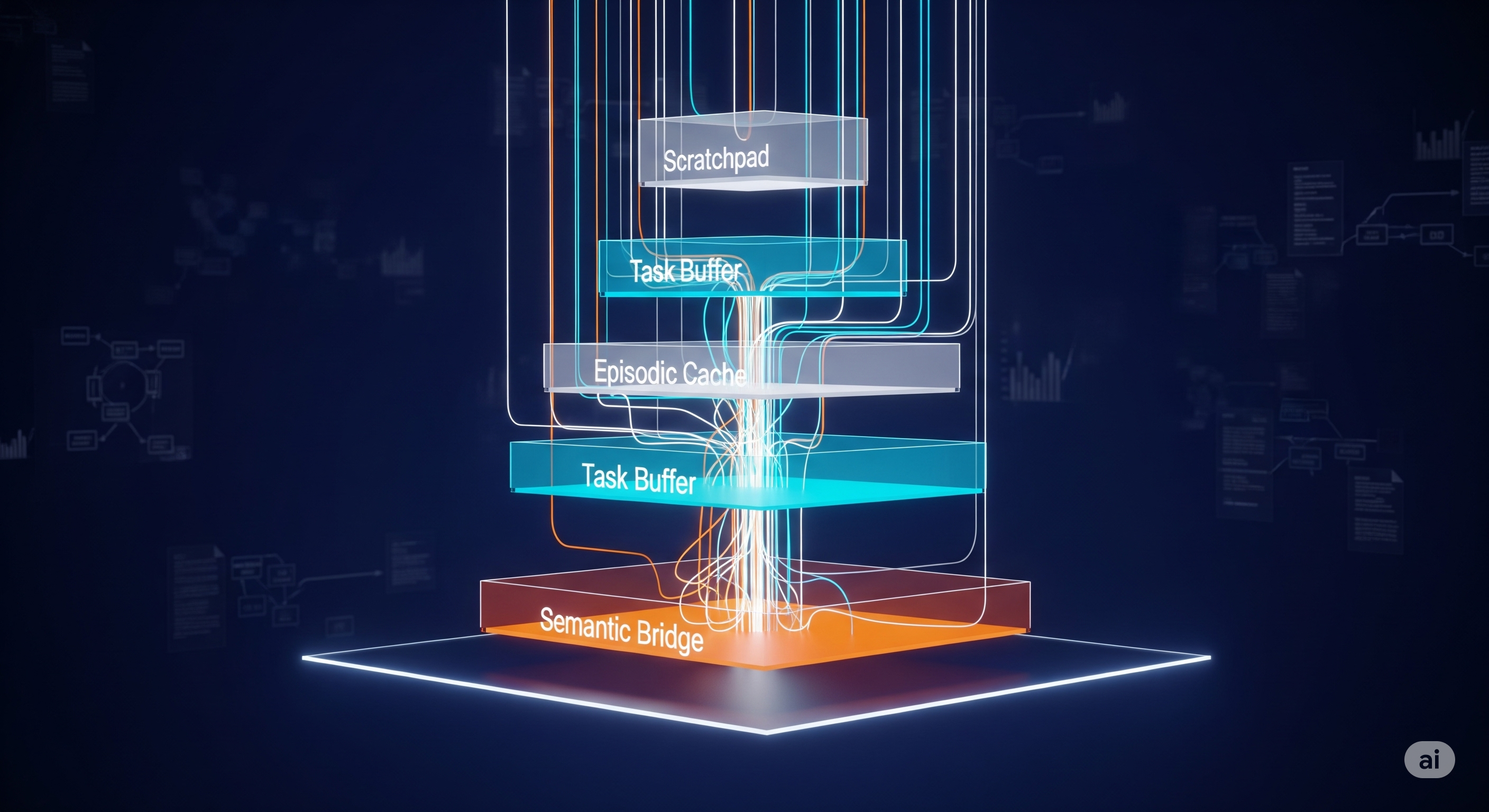
Legal judgment prediction (LJP) is one of those problems that exposes the difference between looking smart and being useful. Most models memorize patterns; judges demand reasons. Today’s paper introduces GLARE—an agentic framework that forces the model to widen its hypothesis space, learn from real precedent logic, and fetch targeted legal knowledge only when it needs it. The result isn’t just higher accuracy; it’s a more auditable chain of reasoning. TL;DR What it is: GLARE = Gent Legal Agentic Reasoning Engine for LJP. Why it matters: It turns “guess the label” into compare-and-justify—exactly how lawyers reason. How it works: Three modules—Charge Expansion (CEM), Precedents Reasoning Demonstrations (PRD), and Legal Search–Augmented Reasoning (LSAR)—cooperate in a loop. Proof: Gains of +7.7 F1 (charges) and +11.5 F1 (articles) over direct reasoning; +1.5 to +3.1 F1 over strong precedent‑RAG; double‑digit gains on difficult, long‑tail charges. So what: If you’re deploying LLMs into legal ops or compliance, agentic structure > bigger base model. Why “agentic” beats bigger The usual upgrades—bigger models, more RAG, longer context—don’t address the core failure mode in LJP: premature closure on a familiar charge and surface‑level precedent matching. GLARE enforces a discipline: ...