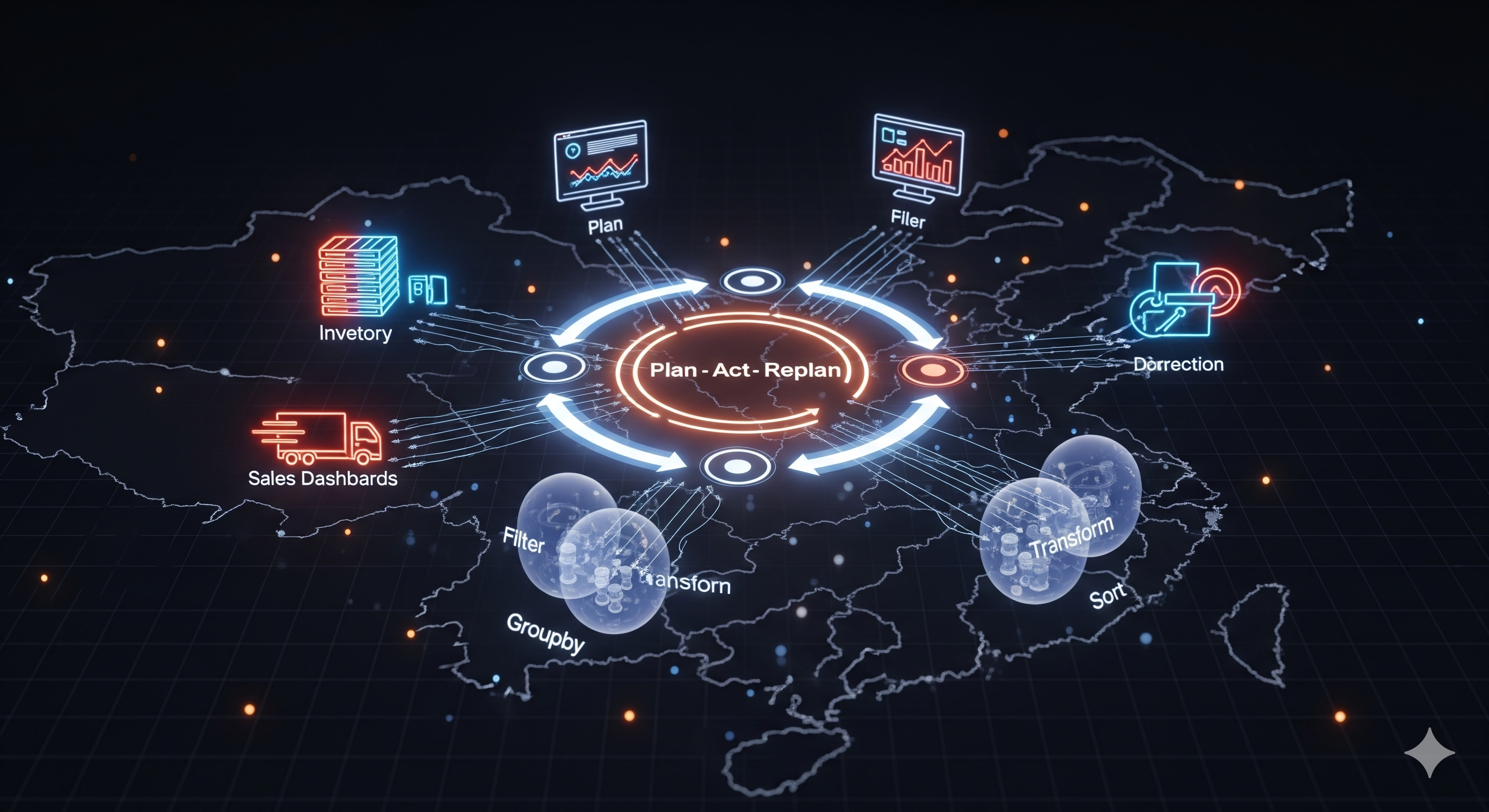
Modern retail planning isn’t a spreadsheet; it’s a loop. A new supply‑chain agent framework—deployed at JD.com’s scale—treats planning as a closed‑loop system: gather data → generate plans → execute → diagnose → correct → repeat. That shift from “one‑and‑done forecasting” to continuous replanning is the core idea worth copying.
What’s actually new here Agentic decomposition around business intents. Instead of dumping a vague prompt into a model, the system classifies the operator’s request into three intent families: (1) inventory turnover & diagnostics, (2) in‑stock monitoring, (3) sales/inventory/procurement recommendations. Each intent triggers a structured task list rather than ad‑hoc code. Atomic analytics, not monoliths. The execution agent generates workflows as chains of four primitives—Filter → Transform → Groupby → Sort—and stitches them with function calls to vetted business logic. This keeps code inspectable, traceable, and reusable. Dynamic reconfiguration. After every sub‑task, observations feed back into the planner, which prunes, reorders, or adds steps. The output isn’t a static report; it’s a plan that learns while it runs. Why it matters for operators (not just researchers) Traditional MIP‑heavy or rule‑based planning works well when the world is stationary and well‑specified. Retail isn’t. Promotions, seasonality, logistics bottlenecks, supplier constraints—these create moving objective functions. The agentic design here bakes in:
...