Agents on the Clock: Turning a 3‑Layer Taxonomy into a Build‑Ready Playbook
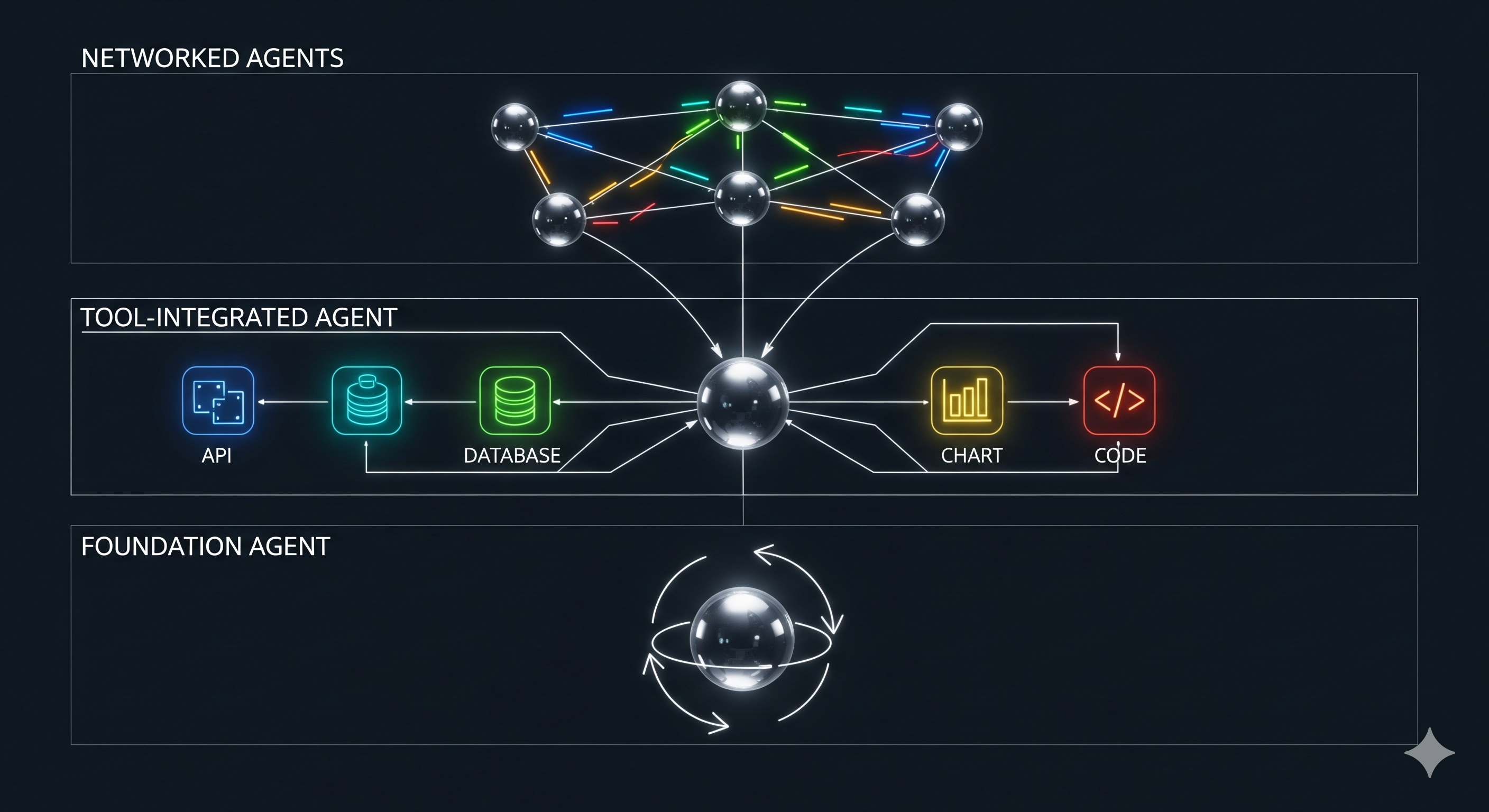
Most “agent” decks promise autonomy; few explain how to make it shippable. A new survey of LLM‑based agentic reasoning frameworks cuts through the noise with a three‑layer taxonomy—single‑agent methods, tool‑based methods, and multi‑agent methods. Below, we translate that map into a practical build/run playbook for teams deploying AI automation in real workflows. TL;DR Single‑agent = shape the model’s thinking loop (roles, task prompts, reflection, iterative refinement). Tool‑based = widen the model’s action space (APIs, plugins/RAG, middleware; plus selection and orchestration patterns: sequential, parallel, iterative). Multi‑agent = scale division of labor (centralized, decentralized, or hierarchical; with cooperation, competition, negotiation). Treat these as orthogonal dials you tune per use‑case; don’t jump to multi‑agent if a reflective single agent with a code‑interpreter suffices. 1) What’s genuinely new (and useful) here Most prior surveys were model‑centric (how to finetune or RLHF your way to better agents). This survey is framework‑centric: it formalizes the reasoning process—context $C$, action space $A = {a_{reason}, a_{tool}, a_{reflect}}$, termination $Q$—and shows where each method plugs into the loop. That formalism matters for operators: it’s the difference between “let’s try AutoGen” and “we know which knob to turn when the agent stalls, loops, or hallucinates.” ...