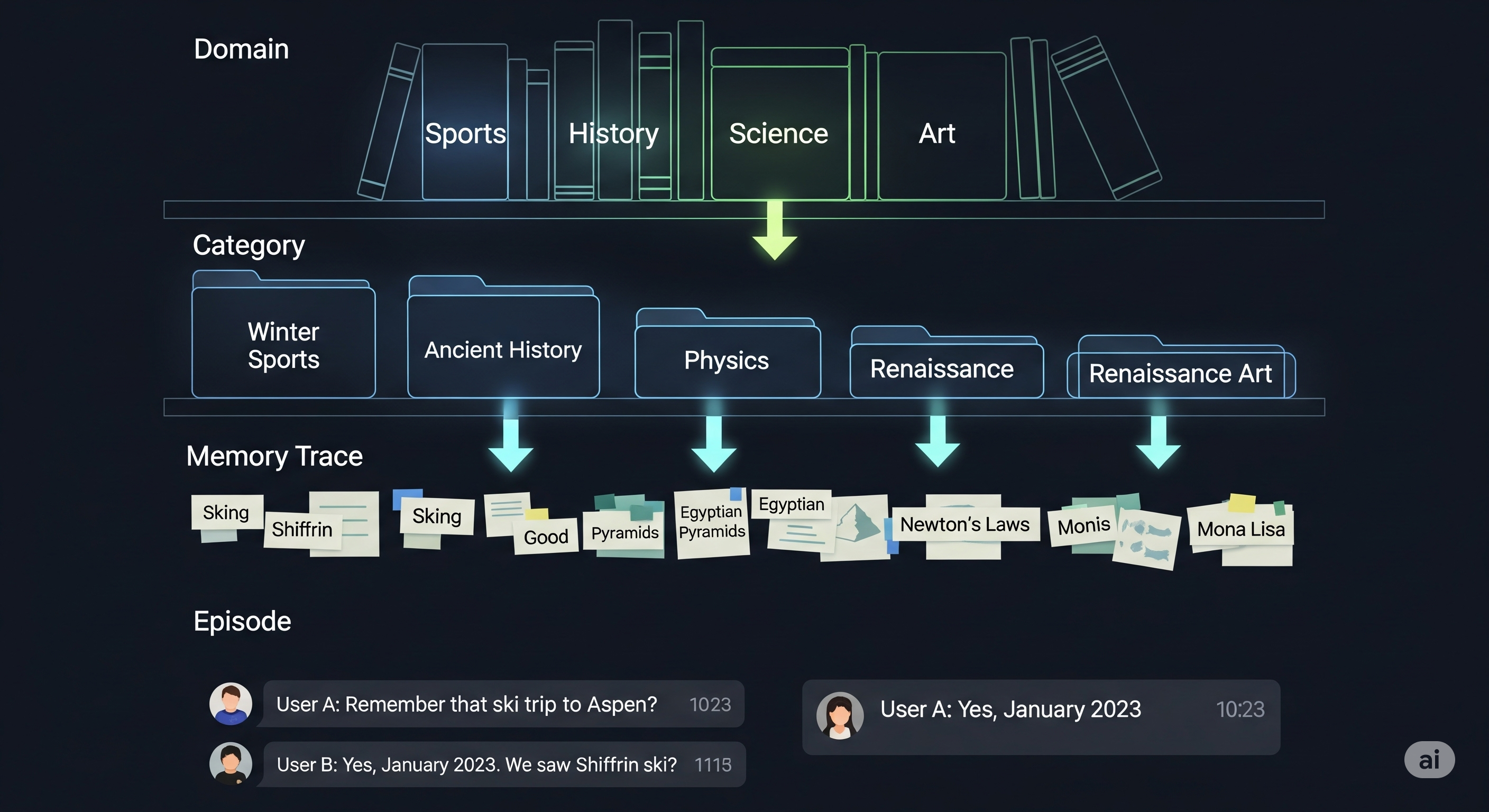
EverMemOS: When Memory Stops Being a Junk Drawer
Memory sounds simple until the assistant has to remember two incompatible things at once. A customer loves craft beer. The same customer is temporarily taking antibiotics. A flat memory system retrieves “likes IPA” and recommends a variety pack, because apparently “memory” means grabbing the loudest sticky note from a drawer and pretending it is wisdom. A more useful assistant retrieves the preference, the medical constraint, the timing, and the relation among them. It recommends a mocktail and quietly avoids turning personalization into negligence. ...