The Art of Forgetting: Why Smarter AI Agents Need Selective Amnesia
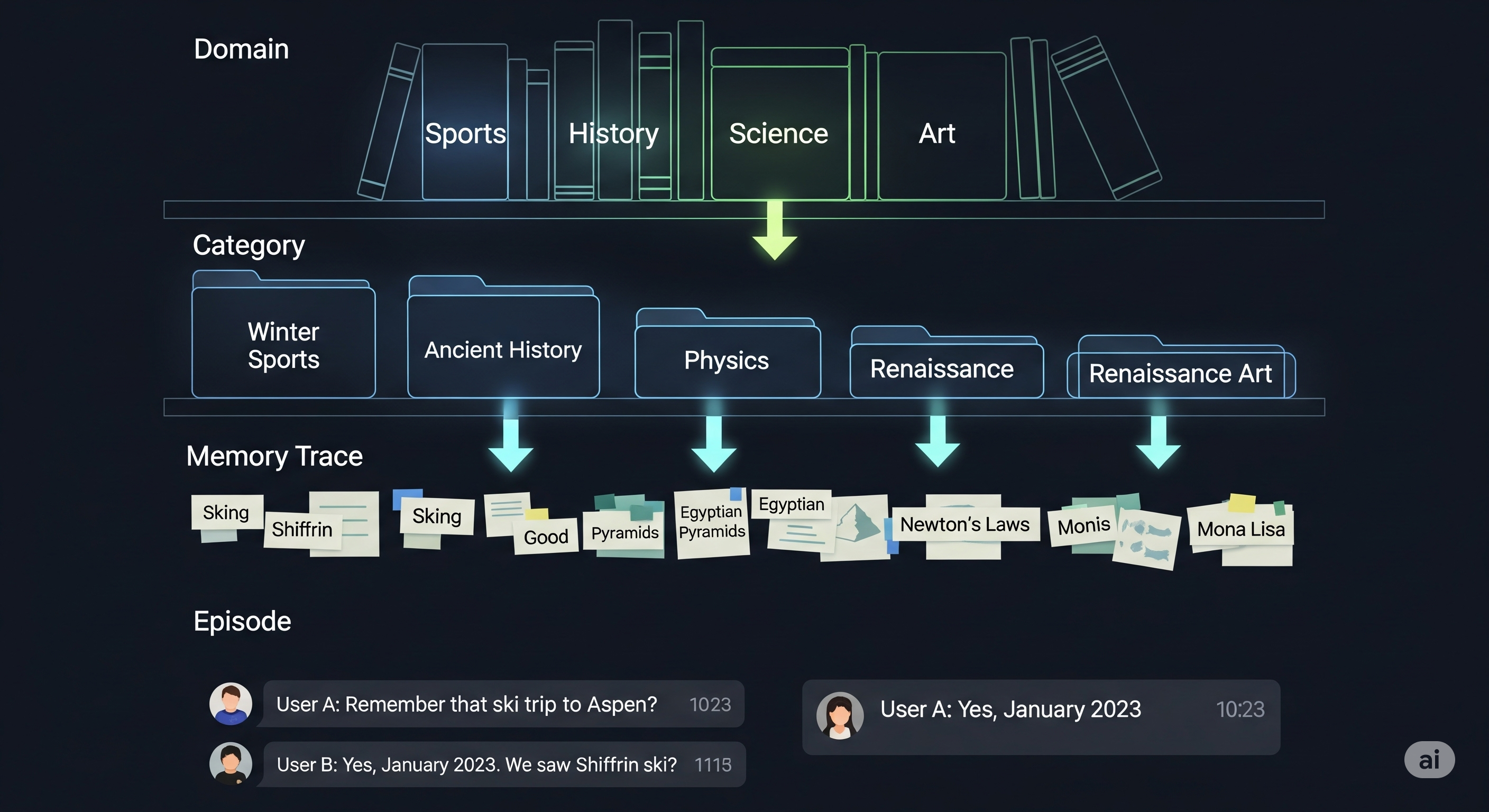
Opening — Why this matters now Everyone is obsessed with making AI remember more. Longer context windows. Persistent memory. Multi-session agents that “never forget.” It sounds impressive—until your system starts hallucinating outdated facts, dragging irrelevant context into decisions, and slowing down under its own cognitive weight. The uncomfortable truth is this: memory is not an asset unless it is curated. ...