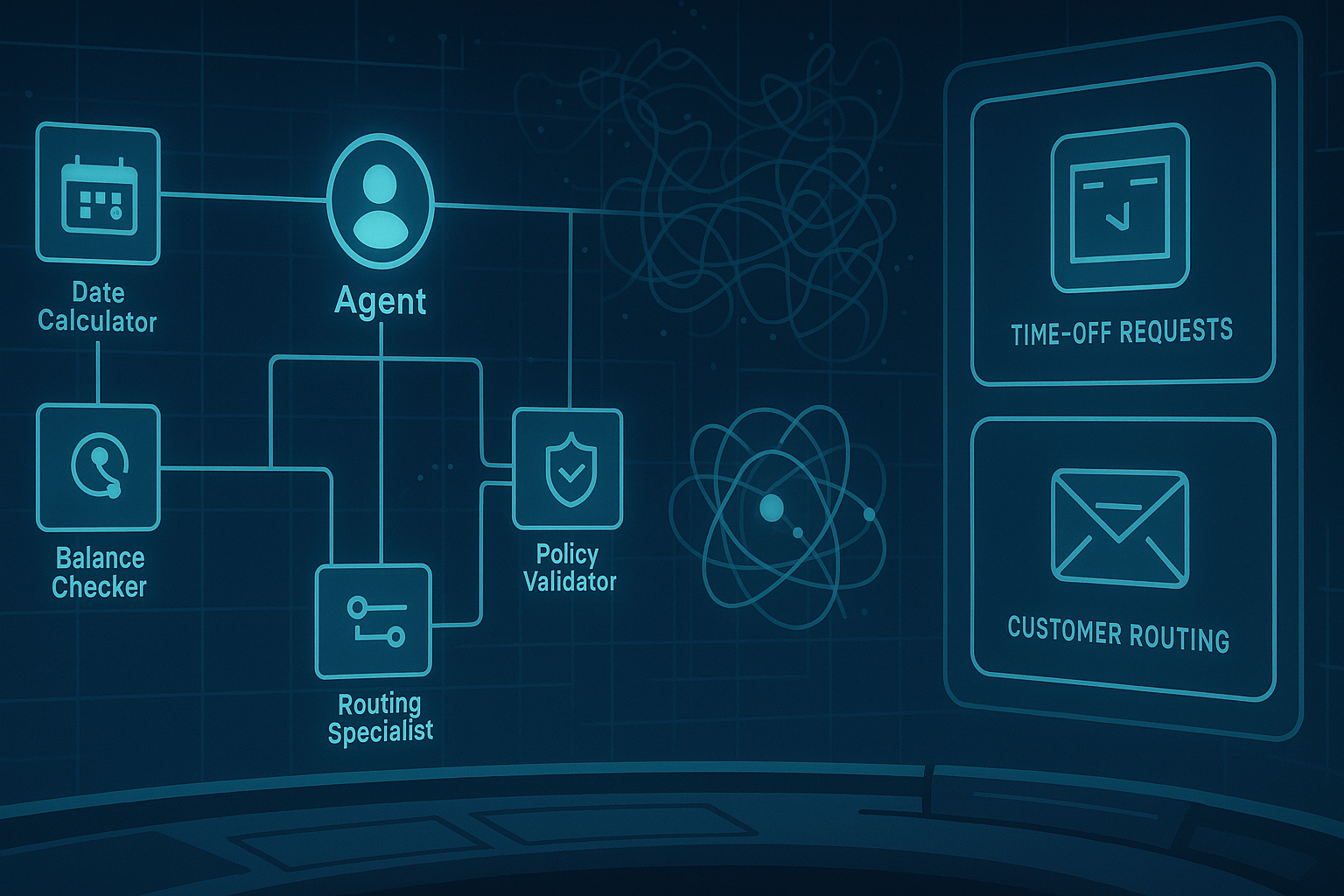
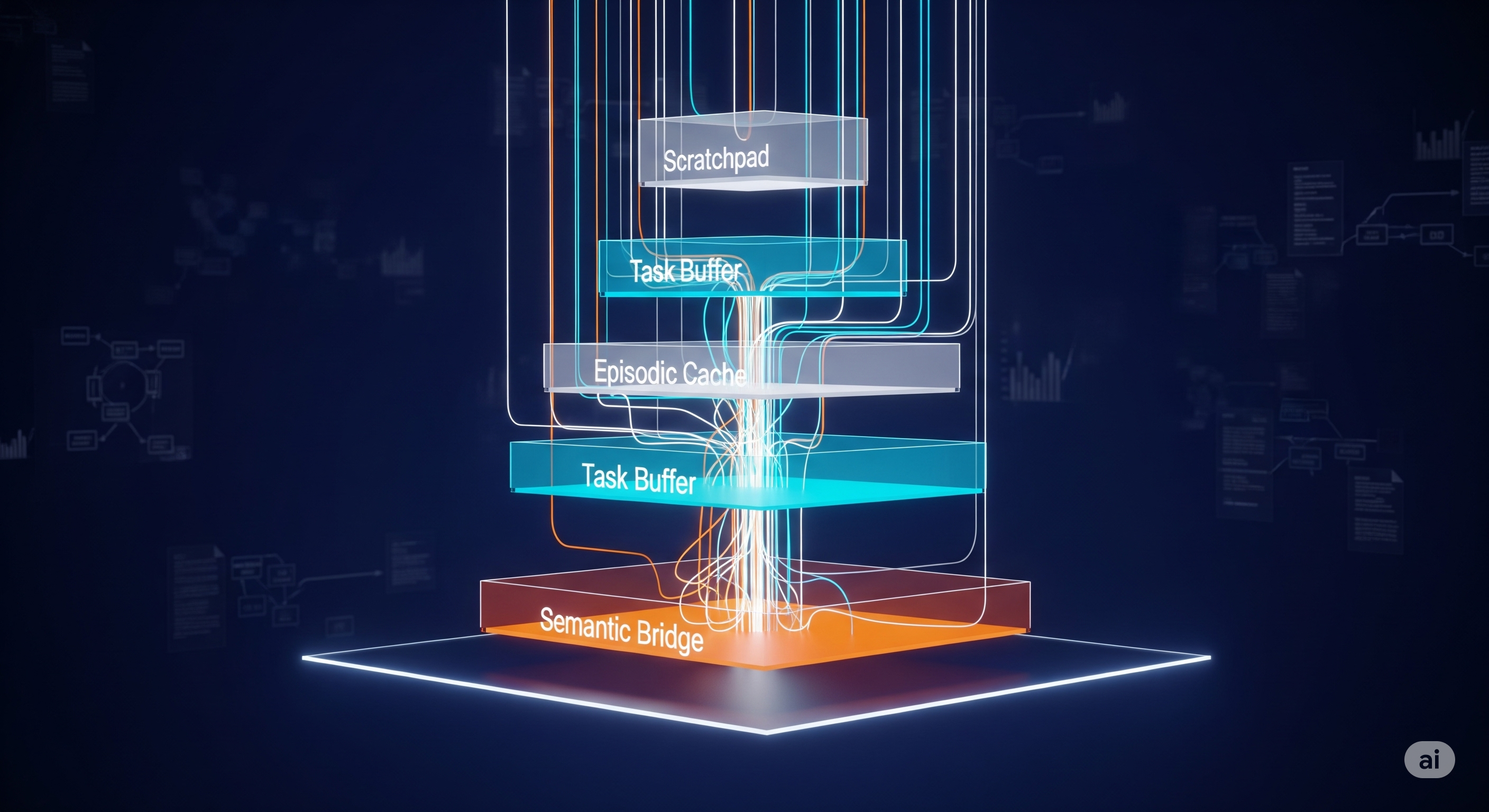
Your Agent Remembers—But Can It Forget?
Opening — Why this matters now As reinforcement learning (RL) systems inch closer to real-world deployment—robotics, autonomous navigation, decision automation—a quiet assumption keeps slipping through the cracks: that remembering is enough. Store the past, replay it when needed, act accordingly. Clean. Efficient. Wrong. The paper Memory Retention Is Not Enough to Master Memory Tasks in Reinforcement Learning dismantles this assumption with surgical precision. Its core claim is blunt: agents that merely retain information fail catastrophically once the world changes. Intelligence, it turns out, depends less on what you remember than on what you are able to forget. ...