From Tokens to Teaspoons: What a Prompt Really Costs
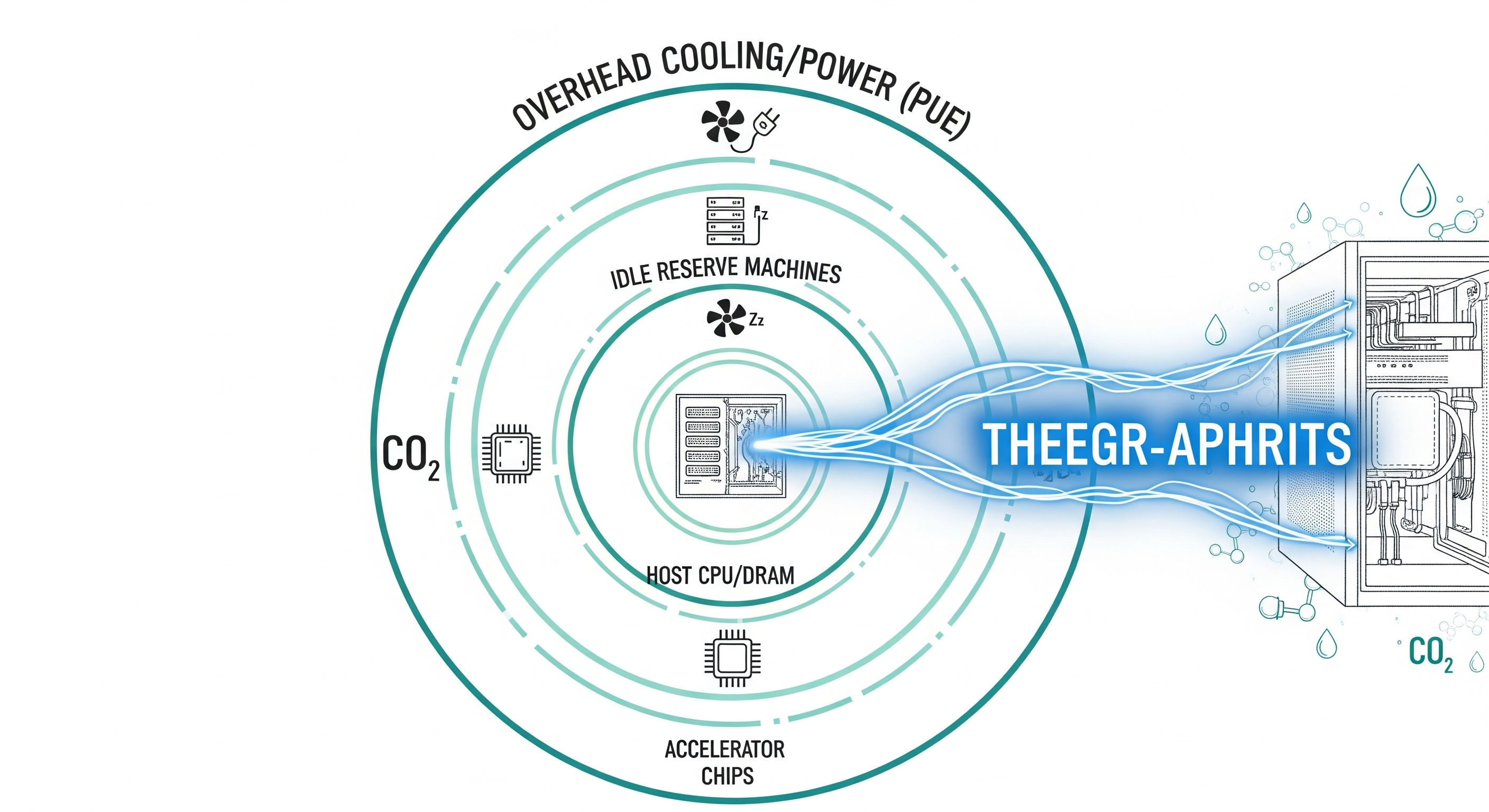
Google’s new in‑production measurement rewrites how we think about the environmental footprint of AI serving—and how to buy it responsibly. Executive takeaways A typical prompt is cheaper than you think—if measured correctly. The median Gemini Apps text prompt (May 2025) used ~0.24 Wh of energy, ~0.03 gCO2e, and ~0.26 mL of water. That’s about the energy of watching ~9 seconds of TV and roughly five drops of water. Boundaries matter more than math. When you count only accelerator draw, you get ~0.10 Wh. Add host CPU/DRAM, idle reserve capacity, and data‑center overhead (PUE), and it rises to ~0.24 Wh. Same workload, different boundaries. Efficiency compounds across the stack. In one year, Google reports ~33× lower energy/prompt and ~44× lower emissions/prompt, driven by model/inference software, fleet utilization, cleaner power, and hardware generations. Action for buyers: Ask vendors to disclose measurement boundary, batching policy, TTM PUE/WUE, and market‑based emissions factors. Without these, numbers aren’t comparable. Why the world argued about “energy per prompt” Most public figures were estimates based on assumed GPUs, token lengths, and workloads. Real fleets don’t behave like lab benches. The biggest source of disagreement wasn’t arithmetic; it was the measurement boundary: ...