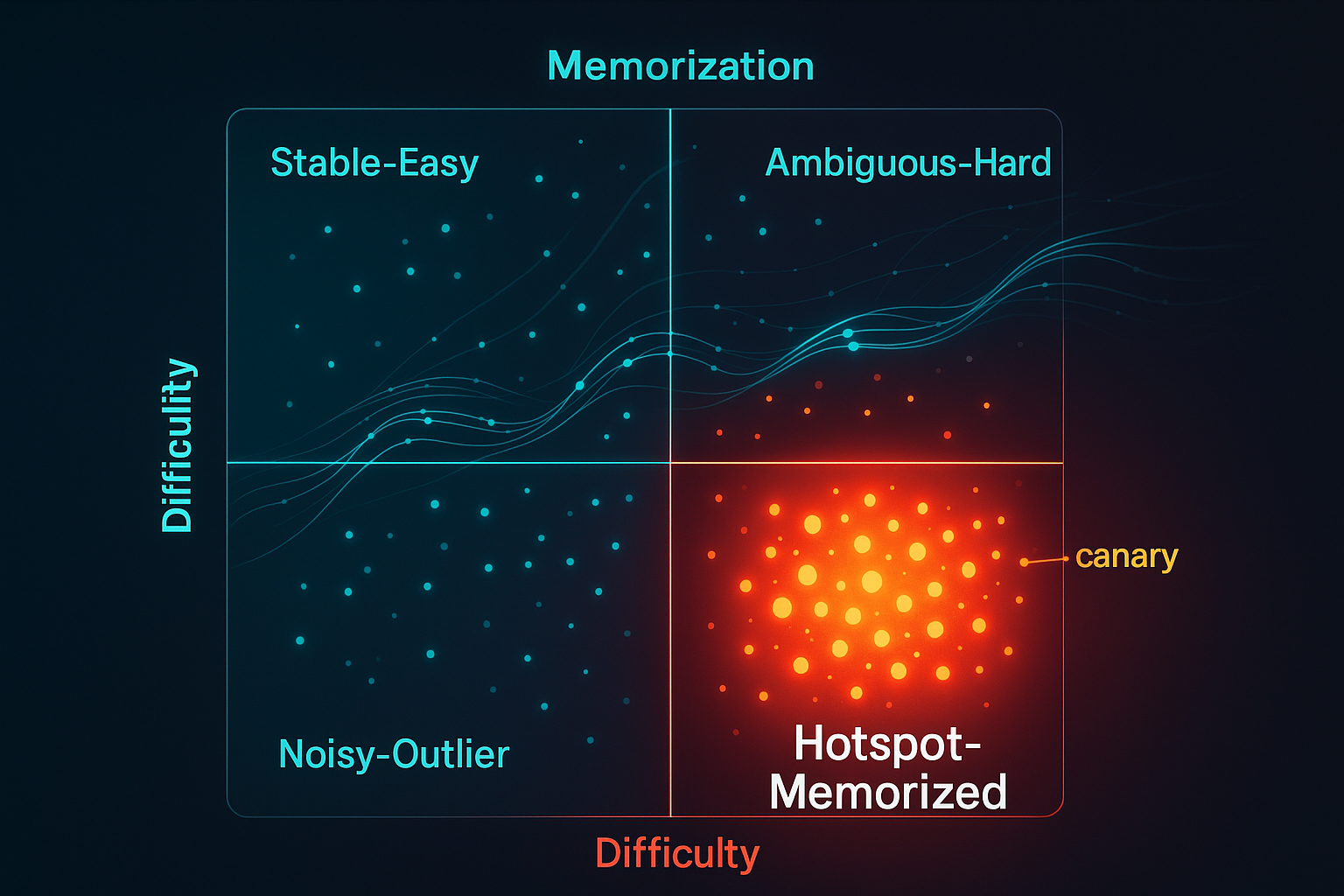
Competency Gaps: When Benchmarks Lie by Omission
Scores are comforting. That is their main commercial advantage. A vendor can say its model reaches a certain accuracy on a benchmark, a leaderboard can rank systems neatly, and an internal AI team can report that the new model is “better” than the old one. Everyone gets a number. The procurement slide looks tidy. The risk committee, if mercifully sleepy, moves on. ...