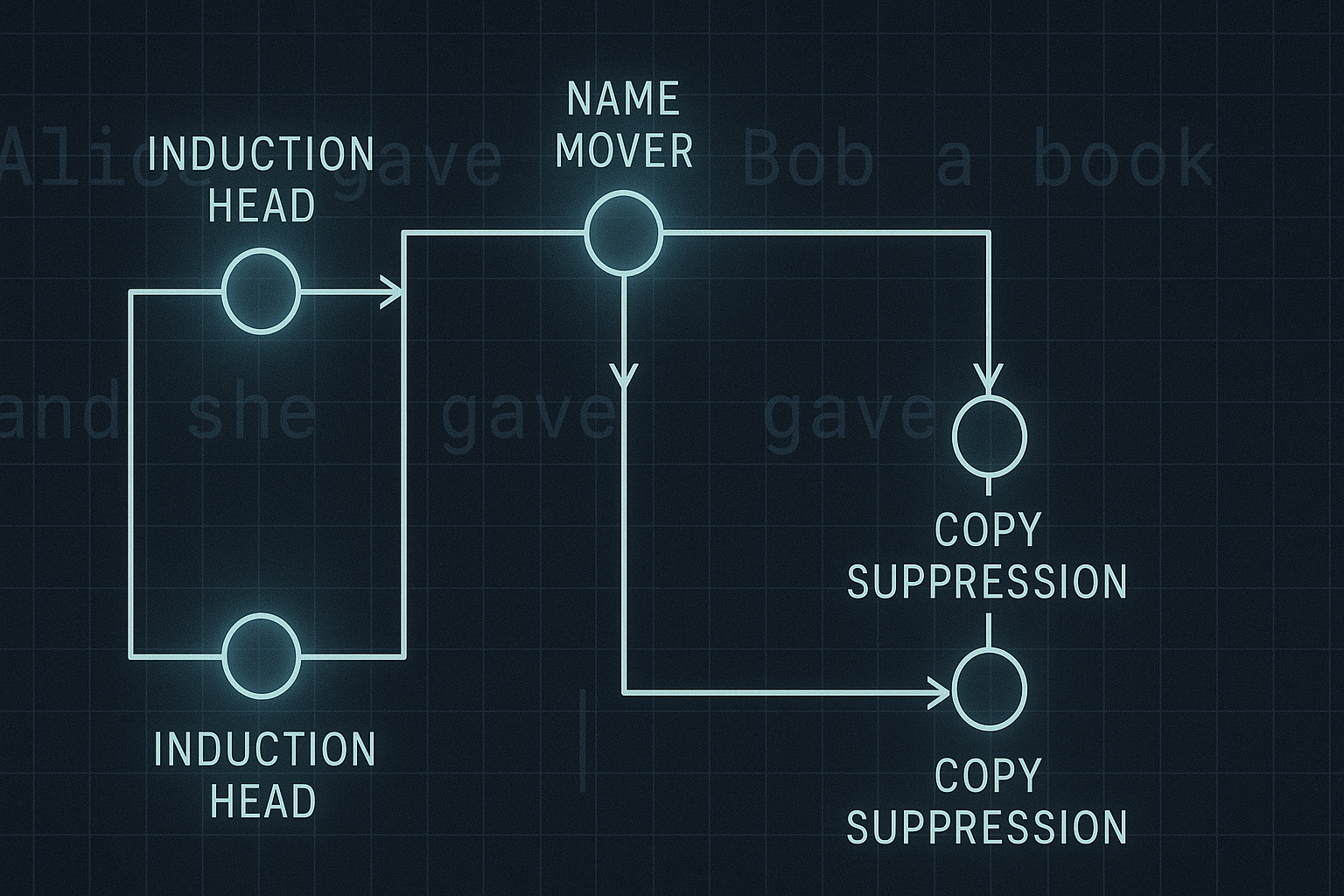
Unpacking the Explicit Mind: How ExplicitLM Redefines AI Memory
Why this matters now Every few months, another AI model promises to be more “aware” — but awareness is hard when memory is mush. Traditional large language models (LLMs) bury their knowledge across billions of parameters like a neural hoarder: everything is stored, but nothing is labeled. Updating a single fact means retraining the entire organism. The result? Models that can write essays about Biden while insisting he’s still president. ...