Free AI Inference Providers
A daily dashboard for monitoring free AI inference providers, with curated vendor boards and a machine-refreshable OpenRouter free-model roster.
A daily dashboard for monitoring free AI inference providers, with curated vendor boards and a machine-refreshable OpenRouter free-model roster.

Opening — Why this matters now Transformer fatigue is real. After years of scaling attention mechanisms into increasingly expensive foundation models, the industry is starting to notice an uncomfortable pattern: more parameters, more data, more opacity. Performance improves—but explainability, efficiency, and biological plausibility quietly degrade. Into this environment arrives a familiar but re-engineered idea: Hopfield networks. Not as a nostalgic curiosity, but as a serious contender for the next generation of vision backbones. ...

Opening — Why this matters now As AI systems inch closer to everyday human interaction, emotion is no longer a “nice-to-have” signal. It is a prerequisite. Voice assistants, mental‑health tools, call‑center analytics, and social robots all face the same bottleneck: understanding not just what was said, but how it was said. Speech Emotion Recognition (SER) has promised this capability for years, yet progress has been throttled by small datasets, brittle features, and heavyweight models that struggle to scale. ...

Opening — Why this matters now Large language models are getting uncomfortably good at remembering things they were never supposed to remember. Training data leaks, verbatim recall, copyright disputes, and privacy risks are no longer edge cases—they are board-level concerns. The paper you just made me read tackles this problem head-on, not by adding more guardrails at inference time, but by questioning a more heretical idea: what if models should be trained to forget? ...
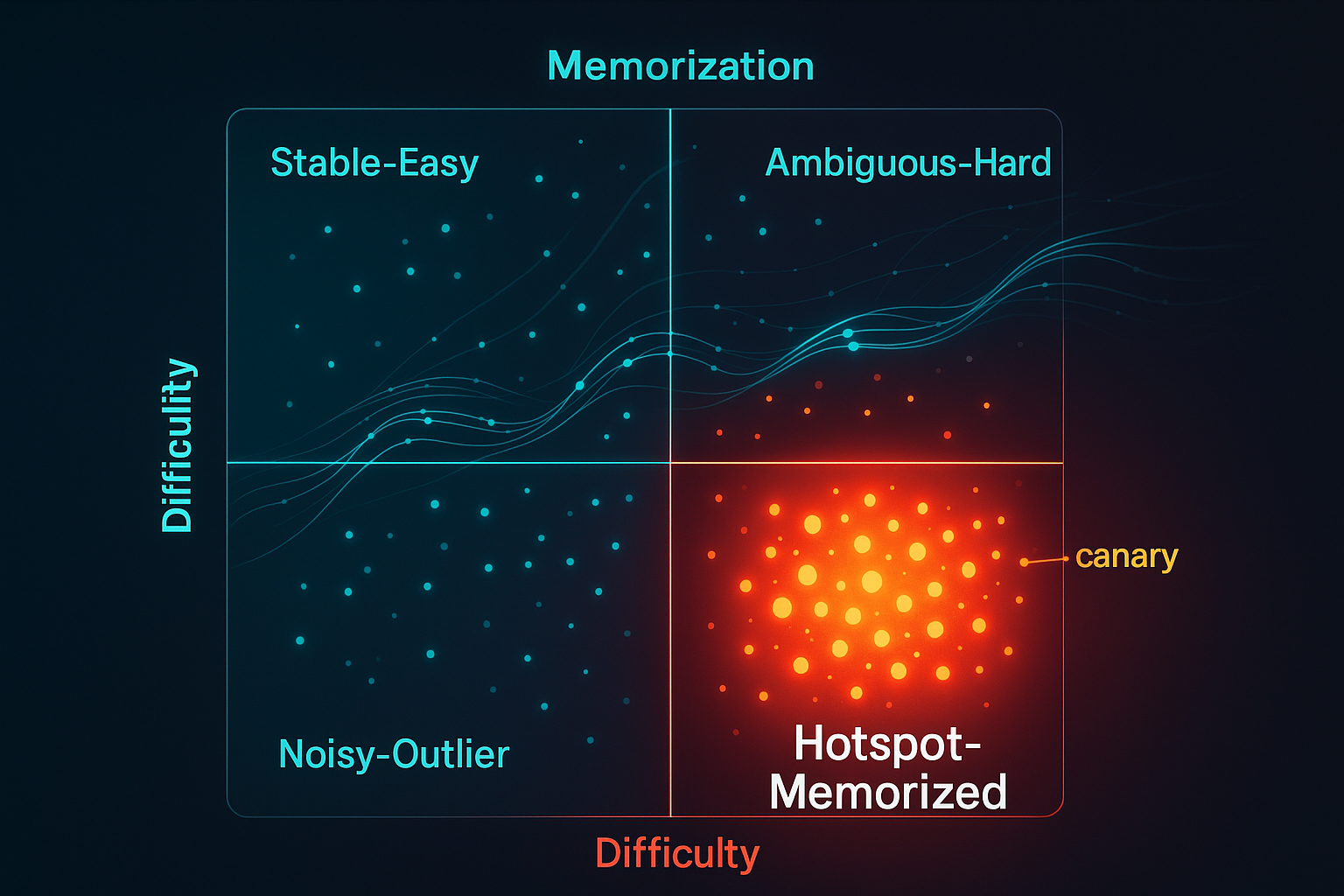
Generative models leak. Not because engineers are careless, but because web-scale corpora hide rare, high-influence shards—snippets so unique that gradient descent can’t help but memorize them. A new data-first method, Generative Data Cartography (GenDataCarto), gives teams a way to see those shards in training dynamics and intervene—surgically, not bluntly—before they become liabilities. The one-slide idea Track two numbers for every pretraining sample: Difficulty (dᵢ): early-epoch average loss—how hard it was to learn initially. Memorization (mᵢ): fraction of epochs with forget events (loss falls below a threshold, then pops back above)—how often the model “refits” the same sample. Plot (dᵢ, mᵢ), set percentile thresholds, and you get a four-quadrant map that tells you what to up-sample, down-weight, or drop to reduce leakage with minimal perplexity cost. ...

The Grammar and the Glow: Making Sense of Time-Series AI What if time-series data had a grammar, and AI could read it? That idea is no longer poetic conjecture—it now has theoretical teeth and practical implications. Two recent papers offer a compelling convergence: one elevates interpretability in time-series AI through heatmap fusion and NLP narratives, while the other proposes that time itself forms a latent language with motifs, tokens, and even grammar. Read together, they suggest a future where interpretable AI is not just about saliency maps or attention—it becomes a linguistically grounded system of reasoning. ...

Traditionally, solving optimization problems involves meticulous human effort: crafting mathematical models, selecting appropriate algorithms, and painstakingly tuning hyperparameters. Despite the rigor, these human-centric processes are prone to bottlenecks, limiting the industrial adoption of cutting-edge optimization techniques. Wenhao Li and colleagues 1 challenge this paradigm in their recent paper, proposing an innovative shift toward evolutionary agentic workflows, powered by foundation models (FMs) and evolutionary algorithms. Understanding the Optimization Space Optimization problems typically traverse four interconnected spaces: ...
Traces of War: Surviving the LLM Arms Race The AI frontier is heating up—not just in innovation, but in protectionism. As open-source large language models (LLMs) flood the field, a parallel move is underway: foundation model providers are fortifying their most powerful models behind proprietary walls. A new tactic in this defensive strategy is antidistillation sampling—a method to make reasoning traces unlearnable for student models without compromising their usefulness to humans. It works by subtly modifying the model’s next-token sampling process so that each generated token is still probable under the original model but would lead to higher loss if used to fine-tune a student model. This is done by incorporating gradients from a proxy student model and penalizing tokens that improve the student’s learning. In practice, this significantly reduces the effectiveness of distillation. For example, in benchmarks like GSM8K and MATH, models distilled from antidistilled traces performed 40–60% worse than those trained on regular traces—without harming the original teacher’s performance. ...