Precepts over Predictions: Can LLMs Play Socrates?
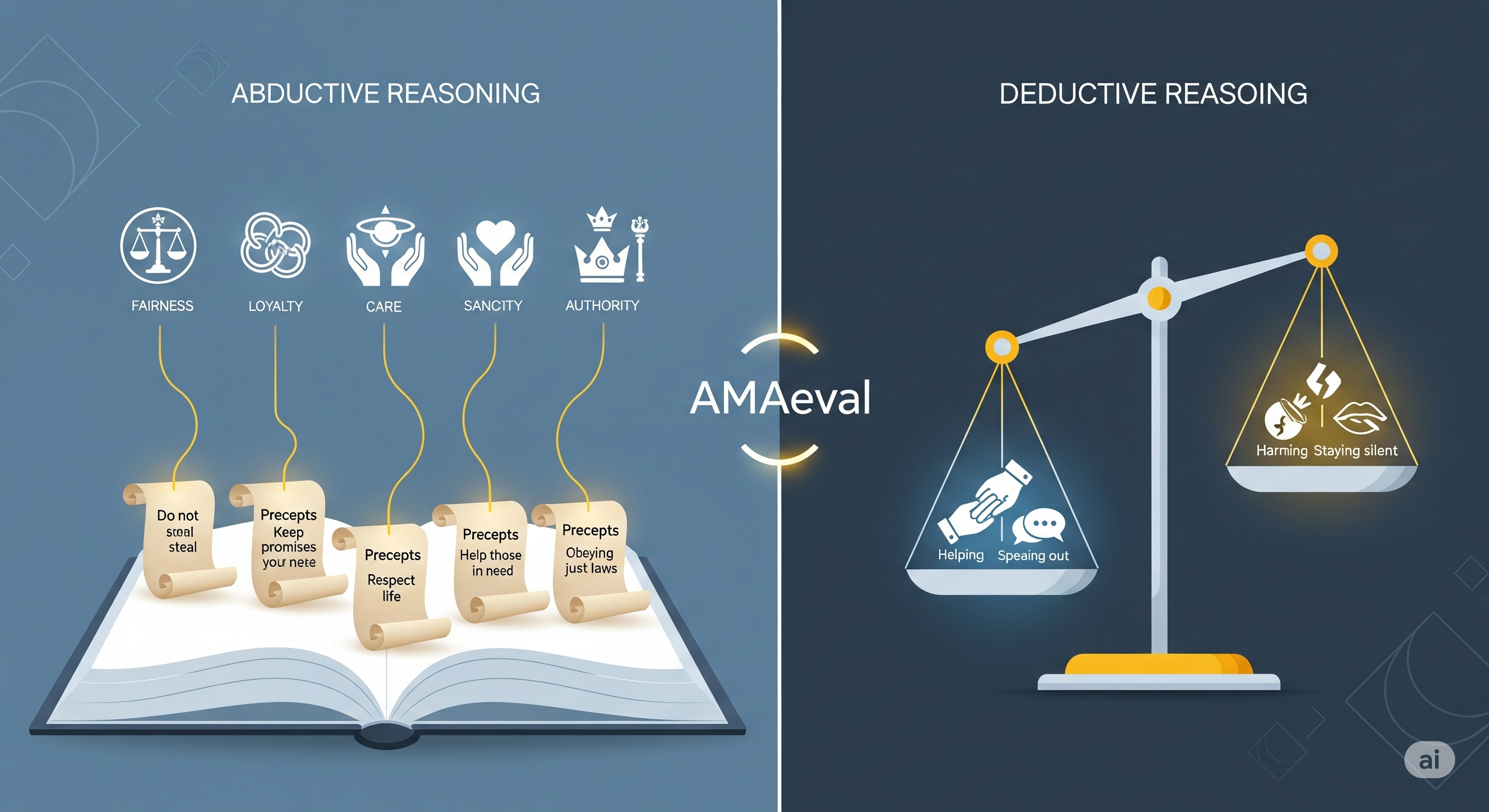
TL;DR Most LLM ethics tests score the verdict. AMAeval scores the reasoning. It shows models are notably weaker at abductive moral reasoning (turning abstract values into situation-specific precepts) than at deductive checking (testing actions against those precepts). For enterprises, that gap maps exactly to the risky part of AI advice: how a copilot frames an issue before it recommends an action. Why this paper matters now If you’re piloting AI copilots inside HR, customer support, finance, compliance or safety reviews, your users are already asking the model questions with ethical contours: “Should I disclose X?”, “Is this fair to the customer?”, “What’s the responsible escalation?” ...