Anonymize Customer Data with AI
How to use AI to detect and redact sensitive customer information while understanding the limits of automated anonymization.
How to use AI to detect and redact sensitive customer information while understanding the limits of automated anonymization.

Opening — Why this matters now The industry loves to talk about generalization. We celebrate models that extrapolate, reason, and improvise. But lurking underneath this narrative is a less glamorous behavior: memorization. Not the benign kind that helps recall arithmetic, but the silent absorption of training data—verbatim, brittle, and sometimes legally radioactive. The paper behind this article asks a pointed question the AI industry has mostly tiptoed around: where, exactly, does memorization happen inside large language models—and how can we isolate it from genuine learning? ...

Opening — Why this matters now Large language models are getting uncomfortably good at remembering things they were never supposed to remember. Training data leaks, verbatim recall, copyright disputes, and privacy risks are no longer edge cases—they are board-level concerns. The paper you just made me read tackles this problem head-on, not by adding more guardrails at inference time, but by questioning a more heretical idea: what if models should be trained to forget? ...

Opening — Why this matters now Large language models are getting better at everything that looks like intelligence — fluency, reasoning, instruction following. But beneath that progress, a quieter phenomenon is taking shape: models are remembering too much. The paper examined in this article does not frame memorization as a moral panic or a privacy scandal. Instead, it treats memorization as a structural side-effect of modern LLM training pipelines — something that emerges naturally once scale, optimization pressure, and data reuse collide. ...
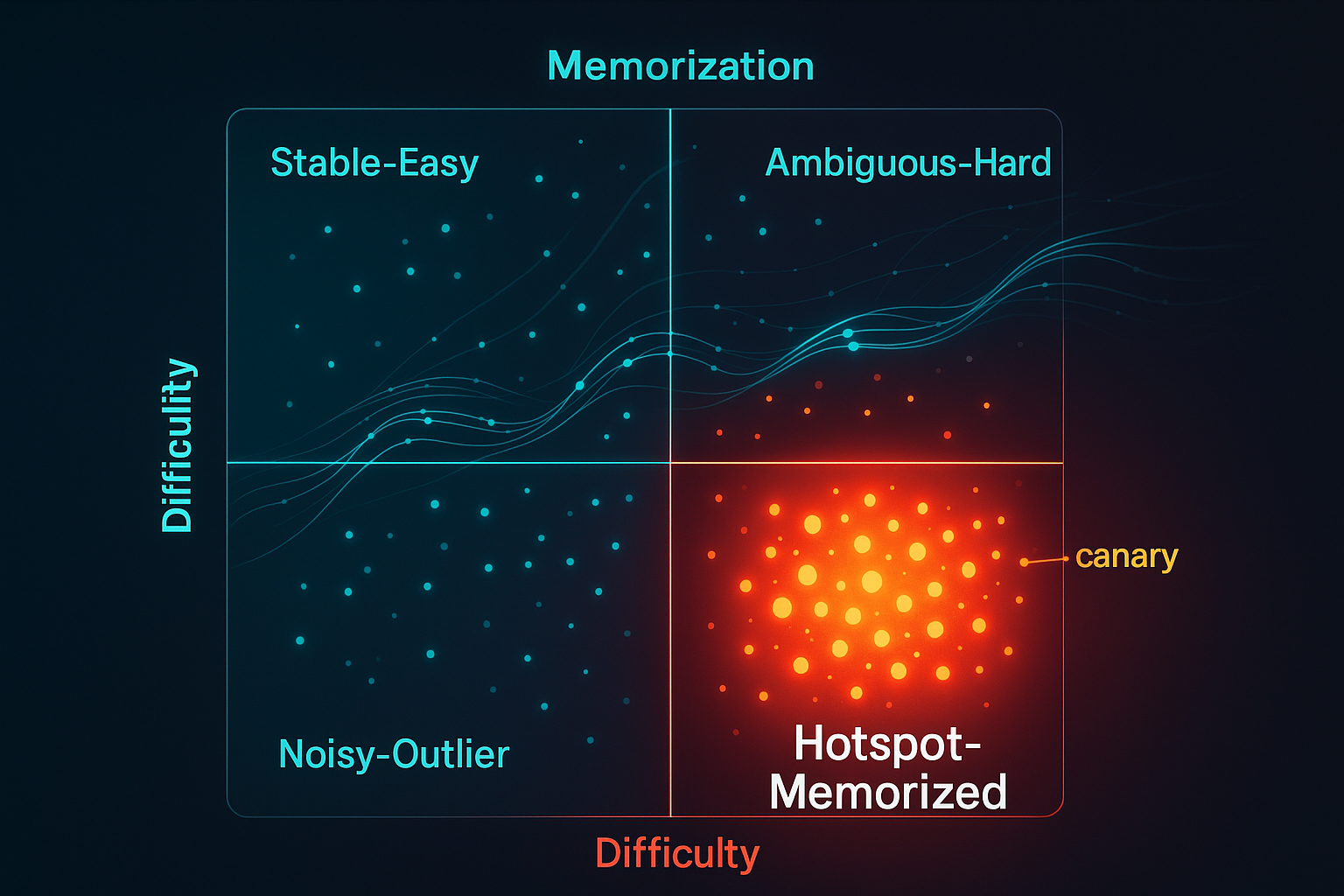
Generative models leak. Not because engineers are careless, but because web-scale corpora hide rare, high-influence shards—snippets so unique that gradient descent can’t help but memorize them. A new data-first method, Generative Data Cartography (GenDataCarto), gives teams a way to see those shards in training dynamics and intervene—surgically, not bluntly—before they become liabilities. The one-slide idea Track two numbers for every pretraining sample: Difficulty (dᵢ): early-epoch average loss—how hard it was to learn initially. Memorization (mᵢ): fraction of epochs with forget events (loss falls below a threshold, then pops back above)—how often the model “refits” the same sample. Plot (dᵢ, mᵢ), set percentile thresholds, and you get a four-quadrant map that tells you what to up-sample, down-weight, or drop to reduce leakage with minimal perplexity cost. ...