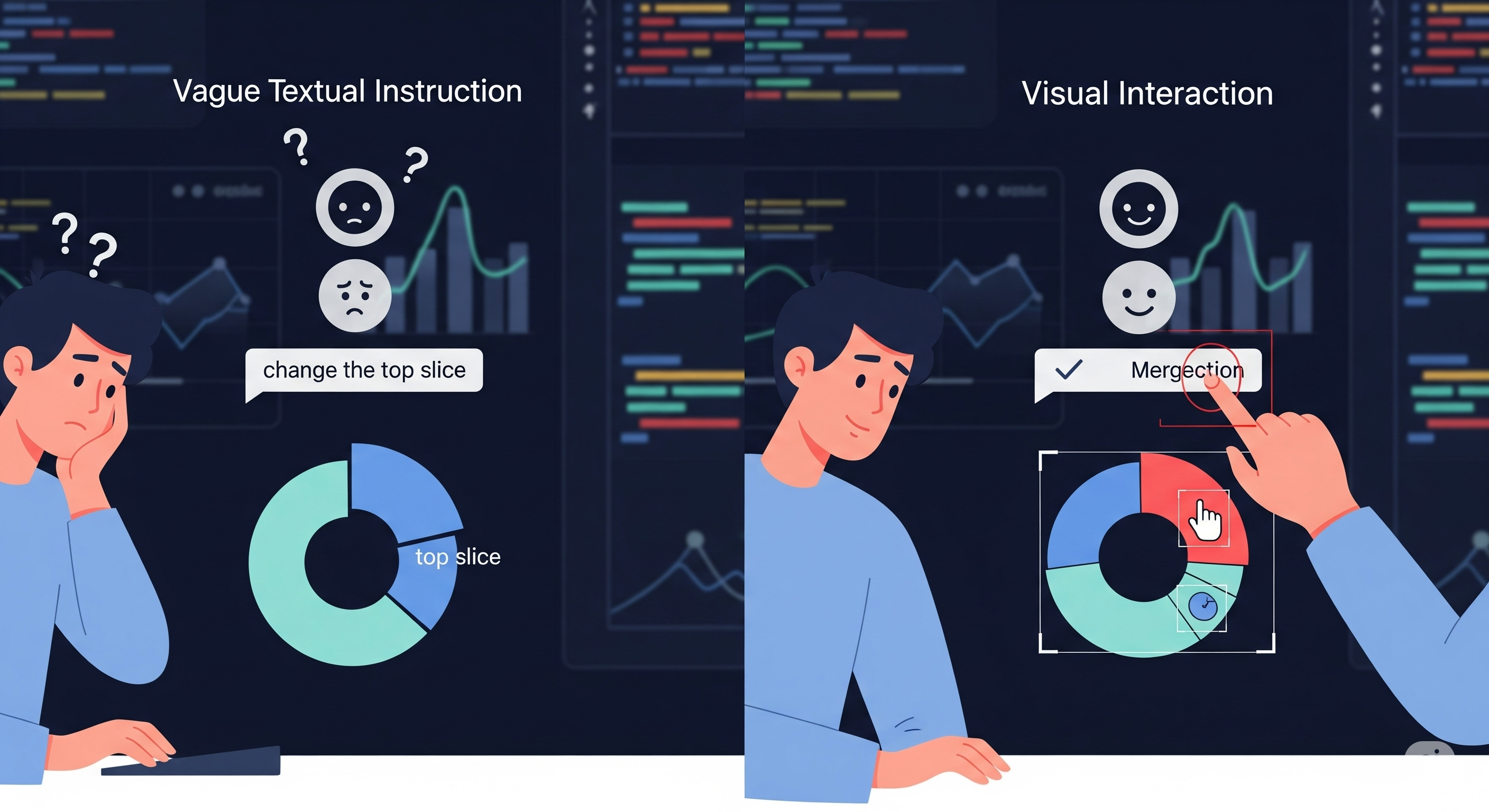
Touch Intelligence: How DigiData Trains Agents to Think with Their Fingers
Opening — Why this matters now In 2025, AI agents are no longer confined to text boxes. They’re moving across screens—scrolling, tapping, and swiping their way through the digital world. Yet the dream of a truly general-purpose mobile control agent—an AI that can use your phone like you do—has remained out of reach. The problem isn’t just teaching machines to see buttons; it’s teaching them to understand intent. ...