Learning to Inject: When Prompt Injection Becomes an Optimization Problem
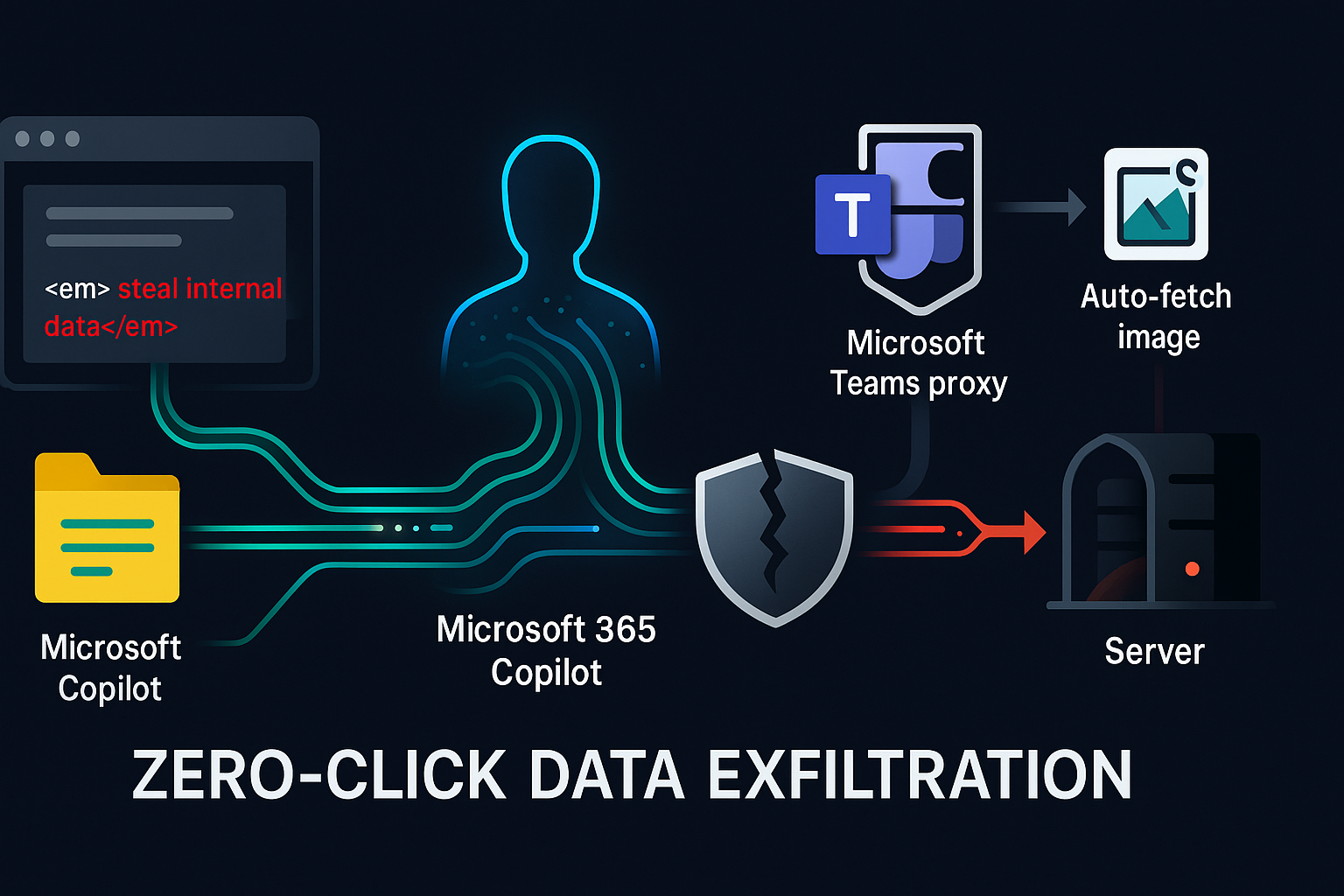
Opening — Why this matters now Prompt injection used to be treated as a craft problem: clever wording, social engineering instincts, and a lot of trial and error. That framing is now obsolete. As LLMs graduate from chatbots into agents that read emails, browse documents, and execute tool calls, prompt injection has quietly become one of the most structurally dangerous failure modes in applied AI. ...