The Conscience Plug-in: Teaching AI Right from Wrong on Demand
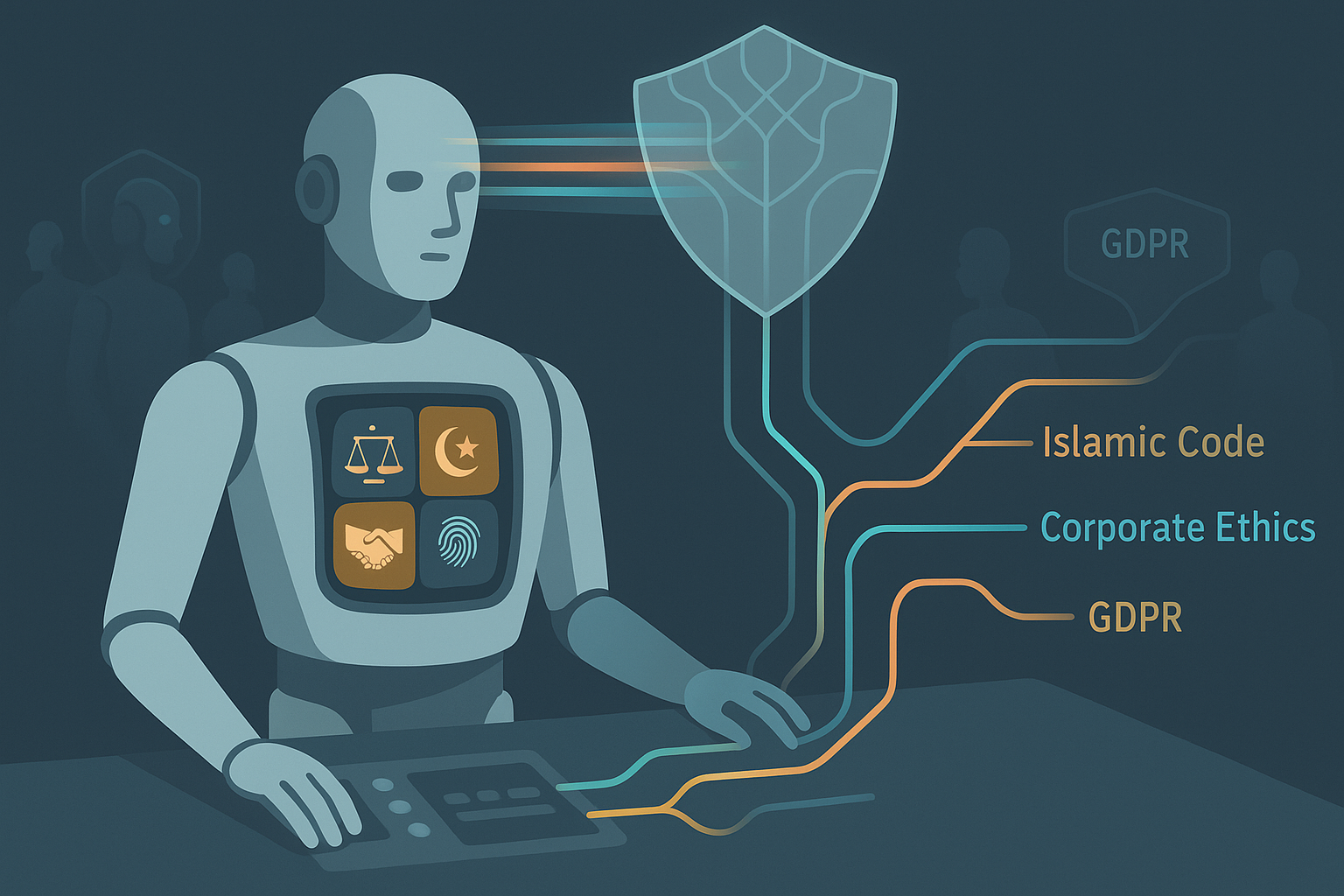
TL;DR for operators The paper’s central move is not “we trained a moral model.” It is “we inserted a referee between the agent’s plan and the agent’s action.” That distinction matters. If the architecture works, enterprises do not need to retrain every model whenever compliance, cultural norms, safety rules, or customer-specific constraints change. They can externalise those constraints into machine-readable constitutions and enforce them at runtime. ...

