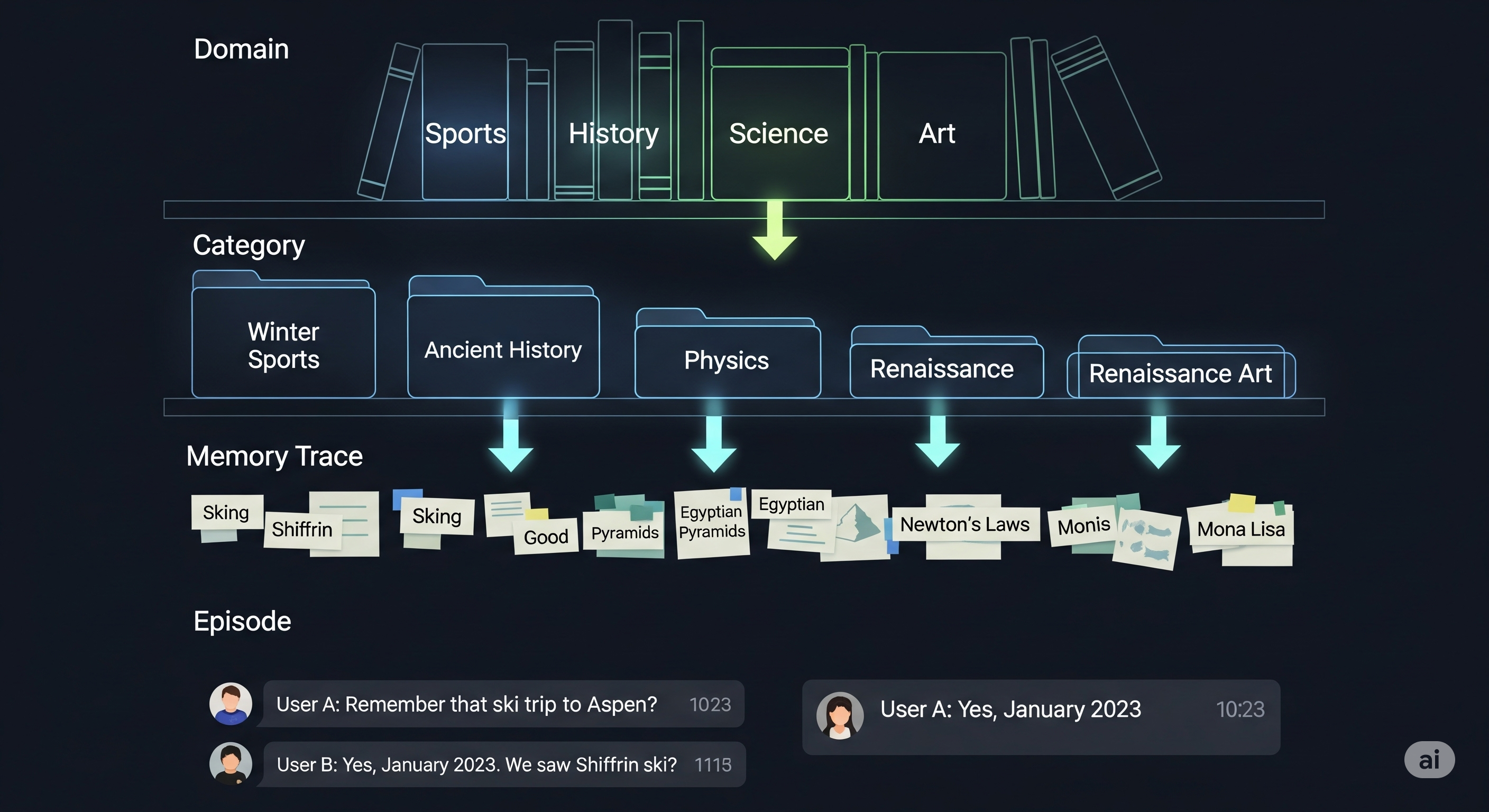
Memory Is the New Attention: Why Hopfield Networks Are Sneaking Back Into Vision AI
Opening — Why this matters now Transformer fatigue is real. After years of scaling attention mechanisms into increasingly expensive foundation models, the industry is starting to notice an uncomfortable pattern: more parameters, more data, more opacity. Performance improves—but explainability, efficiency, and biological plausibility quietly degrade. Into this environment arrives a familiar but re-engineered idea: Hopfield networks. Not as a nostalgic curiosity, but as a serious contender for the next generation of vision backbones. ...