Agents Under Siege: How LLM Workflows Invite a New Breed of Cyber Threats
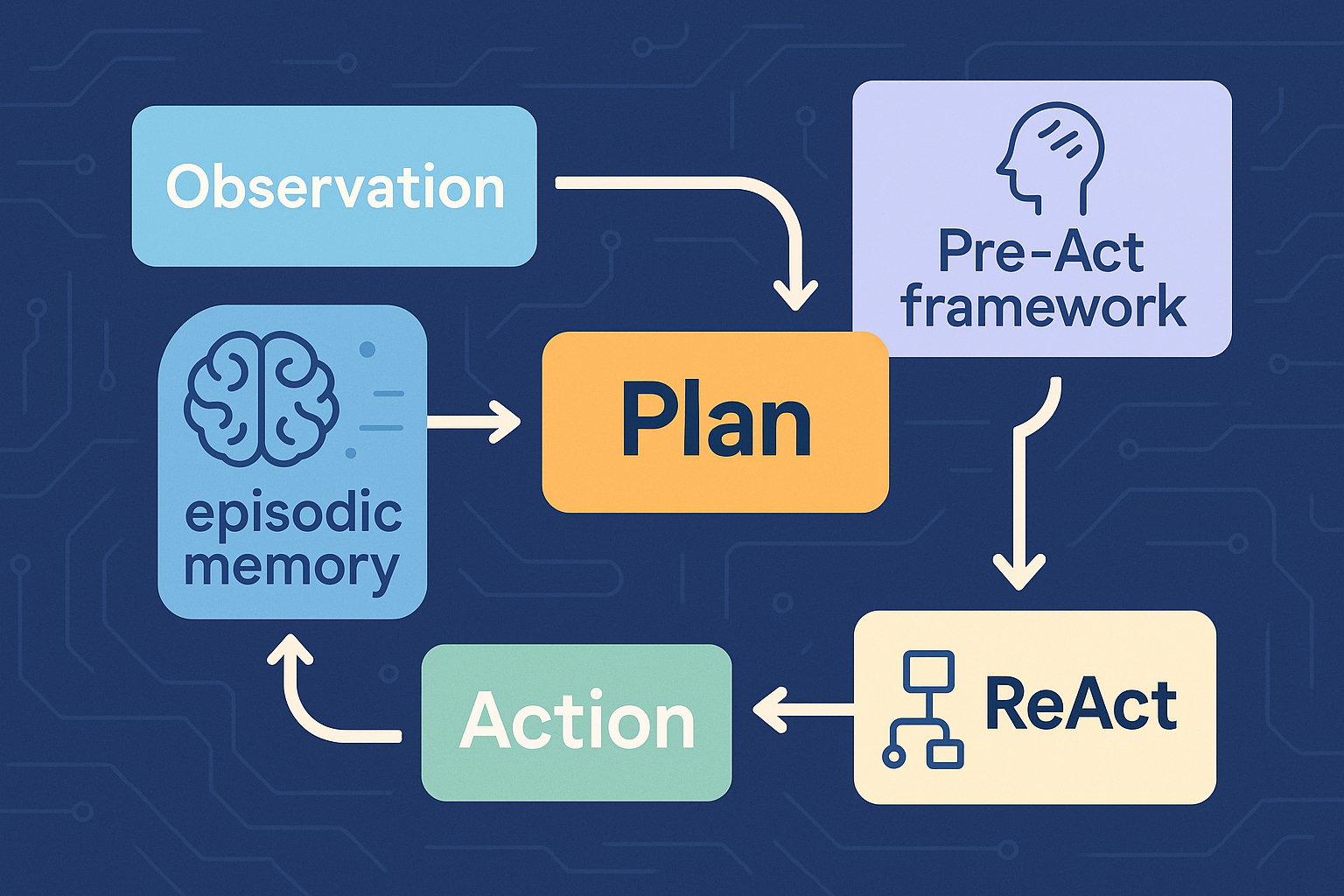
TL;DR for operators A support agent reads a customer email. It checks a CRM record. It calls a refund API. It writes a note into long-term memory. It asks another agent to verify policy. Somewhere in that chain, a malicious instruction hides inside a message, document, issue tracker entry, retrieved snippet, schema, or tool response. The model does not need to become “evil”. It only needs to be helpful in the wrong direction. ...