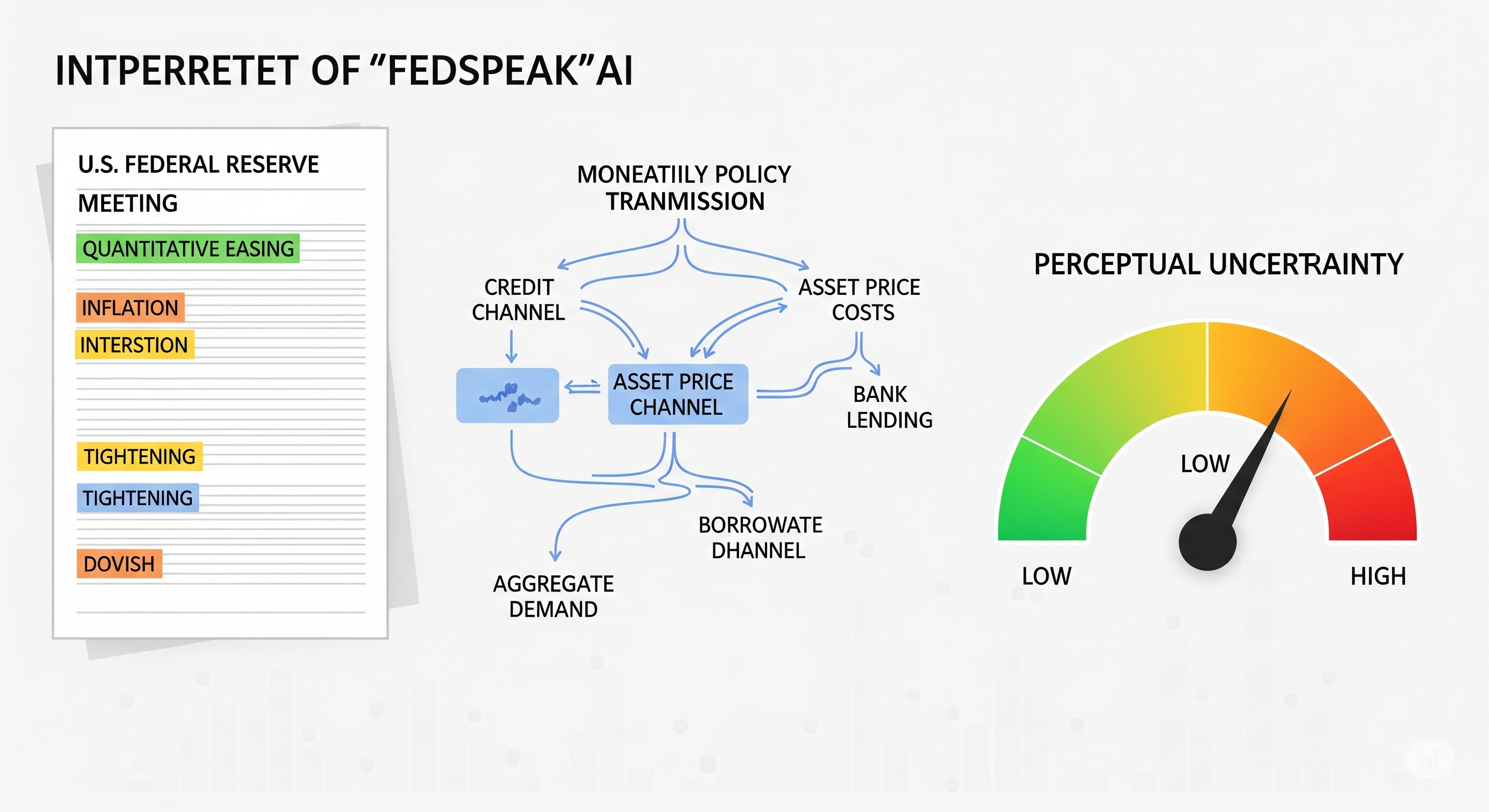
From Genes to Memes: The Evolutionary Biology of Hugging Face's 2 Million Models
When biologists talk about ecosystems, they speak of inheritance, mutation, adaptation, and drift. In the open-source AI world, the same vocabulary fits surprisingly well. A new empirical study of 1.86 million Hugging Face models maps the family trees of machine learning (ML) development and finds that AI evolution follows its own rules — with implications for openness, specialization, and sustainability. The Ecosystem as a Living Organism Hugging Face isn’t just a repository — it’s a breeding ground for derivative models. Pretrained models are fine-tuned, quantized, adapted, and sometimes merged, producing sprawling “phylogenies” that resemble biological family trees. The authors’ dataset connects models to their parents, letting them trace “genetic” similarity via metadata and model cards. The result: sibling models often share more traits than parent–child pairs, a sign that fine-tuning mutations are fast, non-random, and directionally biased. ...