TL;DR for operators
Fedspeak classification is not the same thing as sentiment analysis with better stationery. A sentence about “strong employment” can be dovish in one macro regime and hawkish in another. The paper behind this article tackles that problem by giving an LLM a structured reasoning scaffold: extract economic entities, map their relations, reason through monetary-policy transmission paths, then classify the stance as hawkish, dovish, or neutral.1
The headline result is respectable: the full method reports 0.7327 Macro-F1 and 0.7426 Weighted-F1 on the combined FOMC benchmark, beating strong zero-shot and fine-tuned baselines. But the more useful operator takeaway is narrower and more practical. The framework does not prove that an LLM can trade the Fed. It shows that domain-guided reasoning can improve stance classification, and that uncertainty estimates can separate relatively reliable predictions from predictions that should be escalated, reviewed, or ignored.
The mechanism matters because the ablation results are blunt. Removing the monetary-policy transmission path drops combined Macro-F1 from 0.7327 to 0.6538. Removing entity relationships drops it further to 0.6397. Removing perceptual uncertainty barely dents the score, from 0.7327 to 0.7291, but changes the operating model: low-uncertainty predictions score 0.7791 Macro-F1, while high-uncertainty predictions collapse to 0.2473. That is not a decorative confidence score. That is a workflow switch.
For banks, funds, risk teams, and macro research groups, the immediate use case is not autonomous decision-making. It is communication triage: classify the easy parts, surface the reasoning path, and route high-uncertainty or context-heavy statements to humans. Beautifully dull, which is often where useful enterprise AI lives.
Fedspeak is a policy signal, not a mood ring
Markets do not merely listen to the Federal Reserve. They parse it, re-parse it, annotate it, overreact to it, and then pretend this was all disciplined macro reasoning. The object being parsed is not a clean instruction. It is Fedspeak: carefully shaped language designed to communicate policy direction without always converting that direction into a blunt command.
That makes the classification problem unusually treacherous. In ordinary sentiment analysis, a “strong” labour market might sound positive. In monetary policy, it may imply inflation pressure, tighter policy, or a hawkish shift. In a weak economy, the same phrase might support a dovish reading: employment is improving, but not enough to require tightening. The word is not the signal. The macro situation is.
The paper frames the task as policy stance classification across three labels: dovish, hawkish, and neutral. Dovish language leans toward accommodation: lower rates, quantitative easing, or support for growth and employment. Hawkish language leans toward contraction: inflation control, tightening, and tolerance for slower growth. Neutral language carries no clear loosening or tightening tendency.
That definition matters because it stops the article from drifting into a common misconception. This is not a generic “Fed sentiment” model, and it is not a live trading system hiding under academic formatting. It is a classifier for monetary-policy stance in FOMC communications. Its value depends on whether that classification is accurate, interpretable, and appropriately cautious when the text is ambiguous.
The model first turns language into economic machinery
The paper’s central move is to force the model to reason less like a keyword counter and more like a junior macro analyst with a checklist. Yes, that is still faintly terrifying. But it is better than letting the model stare at “price stability” and shout “hawkish” every time.
The framework begins by extracting financial entity relations from the original Fedspeak text. The authors define six core relation types:
| Relation | What it captures | Why it matters in Fedspeak |
|---|---|---|
| CAUSE | One entity leads to a change in another | “Credit tightening reduces investment” is not just two concepts sitting near each other |
| COND | One entity is a necessary condition for another | “If inflation remains elevated…” changes the stance logic |
| EVID | One entity supports a conclusion about another | Data can be evidence, not policy intent |
| PURP | One entity is aimed at achieving another | Policy tools have targets |
| ACT | An agent performs an action | Source and agency matter |
| COMP | One entity is compared with another | Relative weakness or strength can flip the signal |
This decomposition is not cosmetic. The model is asked to identify entities, sources, and logical relations before generating policy interpretation. The appendix makes clear that this is a template-driven process, not a mystical emergence of economic reasoning. The authors use prompts for entity extraction, transmission-path reasoning, and final stance analysis. They also use a hybrid human-AI procedure for data augmentation: generated explanations and reasoning paths are checked and corrected, with two annotators involved when aligning outputs to ground-truth labels.
That human correction step is important. It strengthens the dataset, but it also means the result should not be read as “press button, receive expert economist.” The paper is closer to “structured templates plus model reasoning plus supervised fine-tuning can make Fedspeak classification more reliable.” Less glamorous. More believable.
Transmission paths do the heavy lifting
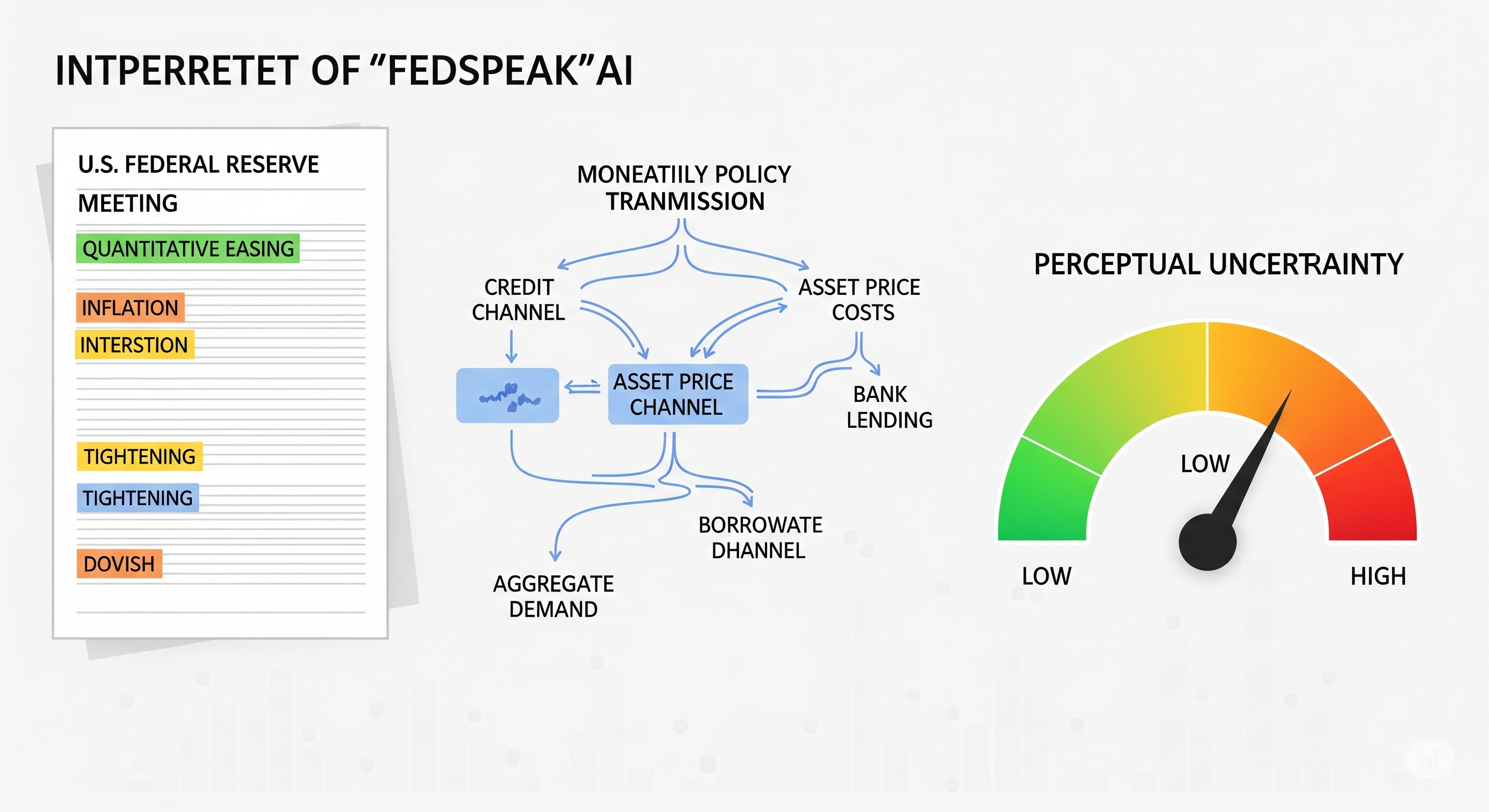
After extracting entity relations, the framework reasons through monetary-policy transmission paths. This is the mechanism-first core of the paper.
The authors represent policy reasoning as a movement from economic phenomena or shocks, through channels such as credit, asset prices, and aggregate demand, toward policy advice. In simpler operational terms:
Fedspeak sentence
→ economic entities and relations
→ transmission channel reasoning
→ implied pressure on policy stance
→ hawkish / dovish / neutral label
This is a useful shift because policy stance often hides in the causal chain, not in the vocabulary. A sentence about commercial real estate valuations, tighter lending standards, and slowing debt growth can carry a different stance from a sentence about inflation expectations becoming unanchored. The model needs to know not only what is mentioned, but how those mentions move through the policy machine.
The ablation results make this point sharply:
| Model variant | Macro-F1 | Weighted-F1 | Likely purpose of test | Interpretation |
|---|---|---|---|---|
| Full method | 0.7327 | 0.7426 | Main evidence | Best combined result |
| Without perceptual uncertainty | 0.7291 | 0.7378 | Ablation | Uncertainty decoding adds modest score gain |
| Without transmission path | 0.6538 | 0.6699 | Ablation | Removing economic mechanism causes the largest drop |
| Without entity relationships | 0.6397 | 0.6551 | Ablation | Entity structure is foundational, not decorative |
| Original Qwen3 baseline | 0.6360 | 0.6534 | Comparison baseline | Fine-tuned base without proposed modules trails full framework |
The score impact is not evenly distributed. The uncertainty component gives a small direct boost to F1. The domain reasoning scaffold gives the major classification lift. That distinction matters for product design. If a team wants a better stance classifier, it should not start by obsessing over decoding tricks. It should first build the economic reasoning layer: entity extraction, source attribution, causal relations, and transmission-path logic.
Uncertainty becomes more valuable later, when the classifier needs to behave like a production component rather than a leaderboard entry.
The leaderboard win is real, but uneven
The paper evaluates on the Trillion Dollar Words FOMC dataset, which includes meeting minutes, press conference transcripts, and speeches from January 1996 to October 2022. The authors compare against zero-shot and fine-tuned models, including GPT-4.1, Gemini-2.5-pro, Phi-4, Qwen models, GLM variants, DeepSeek-R1, FinBERT, HD-Dissent, and AICBC.
On the combined dataset, the full method reaches:
| Category | Macro-F1 | Weighted-F1 |
|---|---|---|
| Meeting minutes | 0.7449 | 0.7394 |
| Press conferences | 0.6672 | 0.6699 |
| Speeches | 0.7291 | 0.7718 |
| All categories | 0.7327 | 0.7426 |
The combined result beats the strongest reported baselines: 0.6662 Macro-F1 and 0.6802 Weighted-F1. The paper reports the biggest gains on meeting minutes and speeches, where structured reasoning has more room to work. These documents are comparatively more textual, less conversational, and more likely to contain self-contained policy reasoning.
Press conferences are the awkward guest at the dinner. The full method underperforms GPT-4.1 on press conference transcripts: GPT-4.1 reports 0.6803 Macro-F1 and 0.6900 Weighted-F1 for that category, compared with the method’s 0.6672 and 0.6699. The authors suggest a plausible reason: press conferences involve real-time question-answer context, where meaning depends heavily on earlier exchanges. A template-based transmission path may miss conversational dependencies that a larger general model handles better.
That boundary should be taken seriously. If a macro desk wants to process prepared speeches, meeting minutes, and policy statements, this mechanism-first approach looks attractive. If it wants to process live press conference exchanges, interruptions, follow-up questions, and rhetorical hedging, the model needs stronger dialogue context handling. The Fed chair’s second answer is often haunted by the first question. Models, like analysts, can miss ghosts.
Perceptual uncertainty is a routing signal, not just a metric
The paper’s second major contribution is dynamic uncertainty decoding. The authors define model uncertainty as perceptual uncertainty, decomposed into cognitive risk and environmental ambiguity.
Cognitive risk refers to the model’s lack of sufficient evidence or domain knowledge. Environmental ambiguity refers to uncertainty in the input: vague language, conflicting cues, contextual dependence, or distributional fuzziness. The model estimates these from next-token logits using a Dirichlet-style construction, then uses perceptual uncertainty to adjust decoding behaviour.
In low-uncertainty cases, the method uses an aggressive strategy: take the top-ranked candidate. In high-uncertainty cases, it switches to a more conservative sampling strategy among top candidates. For fair comparison with baselines, the main experiments still force every model to output a label. In production, however, the authors explicitly argue that high-uncertainty predictions are good candidates for abstention or human intervention.
That is where the result becomes operational.
The low- versus high-uncertainty split is dramatic:
| Prediction group | Macro-F1 | Weighted-F1 | Operational interpretation |
|---|---|---|---|
| Low perceptual uncertainty | 0.7791 | 0.7822 | Safe enough for routine dashboarding or analyst pre-fill |
| High perceptual uncertainty | 0.2473 | 0.4372 | Escalate, abstain, or require human review |
The paper also tests whether perceptual uncertainty correlates with error using t-tests, Mann-Whitney U tests, and logistic regression across different $k$ values. The reported significance is consistent across those tests, supporting the claim that high uncertainty is associated with higher error risk.
The business implication is straightforward: do not use the model as a single-label oracle. Use it as a router.
A practical deployment would look less like this:
FOMC text → model → stance label → trading action
and more like this:
FOMC text
→ stance label
→ reasoning path
→ uncertainty bucket
→ automated summary if low uncertainty
→ human review if high uncertainty
→ audit trail either way
That is less exciting than “AI reads the Fed and makes money while you sleep.” It also has the advantage of not being nonsense.
The appendix is not a second thesis; it tells you what is brittle
The appendix tests are useful because they reveal which parts of the system are structural and which are engineering choices.
The data augmentation ablation, conducted with Gemini-2.5-Pro in an end-to-end setup, shows that the prompt template depends heavily on both rules and examples:
| Augmentation setting | Weighted-F1 |
|---|---|
| Full augmentation prompt | 0.6695 |
| Without rules | 0.5073 |
| Without examples | 0.5024 |
| Without both | 0.4950 |
This supports the template design, but it also exposes a dependency. The model does not simply “understand monetary policy” in the abstract. It performs better when the prompt enforces structure. Remove the scaffolding, and the behaviour degrades sharply.
The label-format test is similarly practical. Text-based labels outperform numeric labels: 0.7378 Weighted-F1 versus 0.7114. That is a small but useful product lesson. If the model is classifying policy stance, “hawkish,” “dovish,” and “neutral” are not just prettier labels than 1, -1, and 0. They carry semantic alignment. The model benefits when the output vocabulary resembles the concept being learned. Sometimes the obvious label is obvious for a reason.
The token vocabulary analysis goes deeper into implementation. The authors observe that evidence for a label can be fragmented across token IDs: “H,” “HA,” “hawk,” “Hawk,” “Neutral,” “NE,” and so on. This matters because uncertainty estimates based on raw token scores can misread the model’s preference when semantically equivalent fragments are spread across the vocabulary. Their vocabulary-clustered strategy slightly improves performance over a non-clustered version: 0.7426 versus 0.7404 Weighted-F1.
That is not a strategic breakthrough. It is an engineering reminder. In LLM systems, labels are not abstract classes floating above the tokenizer. They are generated through messy token mechanics. Ignore that and your uncertainty score can become very precise about the wrong object. A familiar enterprise software experience, really.
The transferability test is modest. Applying the approach to Phi-4 and Qwen-3 shows consistent but small gains over baselines. For Phi-4, the method moves Weighted-F1 from 0.7225 to 0.7241. For Qwen-3, it moves from 0.7378 to 0.7426. This supports some transferability, but not a broad claim that the method will generalise effortlessly across models, central banks, or languages.
The hyperparameter sensitivity analysis is also telling. Performance is fairly stable across temperature and $k$, while the threshold percentile has the largest swing. In production terms, the threshold that decides “confident enough” versus “review this” deserves governance. It is not a footnote parameter. It is the policy lever.
The case study shows where the model still behaves like a model
The case study is small, but it is one of the most useful sections because it shows failure modes with names attached.
The model handles explicit contrastive statements well. In one example about commercial real estate valuations, tighter lending standards, and less debt growth, it correctly predicts a hawkish stance. The sentence contains a logical contrast, and the model uses the causal emphasis correctly.
It fails under contextual confusion. In the sentence “This is perhaps because the emphasis on price stability is taken by some as carrying a hint of restrictive policy…,” the ground-truth label is neutral, but the model predicts hawkish. The problem is source and stance attribution. The sentence describes how “some” interpret price stability; it is not necessarily the Fed asserting a restrictive stance. The model latches onto “price stability,” “restrictive policy,” and “leaning against cyclical increases in demand.” Keywords win. Context loses. The usual little tragedy.
It also fails on implicit statements. A sentence comparing productivity growth in other advanced countries with the United States is labelled dovish, but the model predicts neutral. The underlying argument is indirect: weaker external productivity growth may argue against rushing into tightening. There is no clean policy keyword. The stance lives in the implication.
These cases should shape deployment. The system is better at structured, explicit, economically grounded text than at indirect reasoning, source ambiguity, and dialogue context. That is not a reason to dismiss it. It is a reason to route such cases differently.
What the paper directly shows
The paper directly supports four claims.
First, adding structured economic reasoning improves FOMC stance classification. The evidence comes from the main benchmark and ablation results. Transmission-path reasoning is the largest contributor to performance improvement.
Second, uncertainty estimates are correlated with prediction reliability. Low-perceptual-uncertainty samples perform far better than high-perceptual-uncertainty samples, and statistical tests support the relationship between uncertainty and error.
Third, uncertainty decoding itself provides only a modest direct performance gain in the main F1 table. Its practical value is larger than its leaderboard effect because it enables routing, abstention, and human review.
Fourth, the approach is not uniformly superior across all communication types. It wins overall, but GPT-4.1 remains stronger on press conference transcripts.
That last point is not an embarrassing caveat. It is useful product information. Different communication formats need different model architectures and context windows. Meeting minutes are not press conferences. A model that forgets this is not “domain-adapted.” It is wearing a domain costume.
What Cognaptus infers for business use
The most credible business application is a central-bank communication intelligence layer.
For a macro desk, the system could classify new FOMC text into stance labels, generate a reasoning path, and flag the model’s confidence. Analysts would use this as a first-pass interpretation layer, not a final investment decision. Low-uncertainty items could flow into dashboards, morning notes, or event-reaction summaries. High-uncertainty items would be escalated to senior review.
For a bank risk team, the value is auditability. A naked “hawkish” label is hard to govern. A label accompanied by extracted entities, causal relations, transmission channels, and uncertainty is easier to inspect. It still may be wrong, but at least it is wrong in a way a human can interrogate.
For compliance and model risk teams, the uncertainty split is the interesting control. Instead of pretending all predictions are equal, the system gives a measurable reason to slow down. The threshold can be tuned according to use case: aggressive for research triage, conservative for client-facing commentary, stricter still for workflows that influence risk exposure.
For product builders, the lesson generalises beyond Fedspeak: when the domain has a causal grammar, give the model that grammar. In finance, regulation, medicine, engineering, and supply chains, many tasks are not solved by better vibes around a text embedding. They require structured intermediate reasoning.
The ROI case is therefore not “replace economists.” It is:
| Capability | Operational consequence | ROI relevance |
|---|---|---|
| Stance classification | Faster first-pass reading of FOMC documents | Reduces analyst screening time |
| Entity and relation extraction | Makes reasoning inspectable | Supports audit and review |
| Transmission-path reasoning | Anchors labels in economic mechanisms | Reduces keyword-driven misclassification |
| Perceptual uncertainty | Separates routine cases from risky cases | Enables triage and human escalation |
| Case-level explanations | Helps analysts challenge or accept outputs | Improves trust without pretending certainty |
This is not automation replacing judgement. It is automation forcing judgement to focus where it is actually needed. Radical stuff, apparently.
What remains uncertain
The paper’s boundaries are specific and material.
The first boundary is data. The benchmark covers FOMC communications from January 1996 to October 2022. That is rich, but it is still one institutional setting. The authors themselves note limited availability of fine-grained data from other central banks such as the Bank of England and the European Central Bank. A model tuned to the rhetorical and institutional habits of the Fed may not transfer cleanly to the ECB’s communication style, the BoE’s regime framing, or emerging-market central banks with different credibility constraints.
The second boundary is template dependence. The method relies on hand-crafted templates for entity extraction, transmission-path reasoning, and stance analysis. The appendix shows that removing rules or examples causes a sharp decline. That is evidence for the template’s usefulness, but also evidence that the system has a maintained knowledge-engineering layer. Somebody has to own it, update it, test it, and prevent it from becoming a museum of last cycle’s macro assumptions.
The third boundary is conversational context. Press conferences remain harder. Real-time dialogue creates dependencies across questions, answers, clarifications, and evasions. A sentence may be neutral by itself but hawkish as a reply to a particular question. Production systems would need transcript-level memory, speaker tracking, and question-answer linkage.
The fourth boundary is implicit meaning. The case study shows that the model can miss policy stance when the signal is indirect. This is exactly the kind of subtlety human Fed watchers get paid to notice, at least in theory.
The fifth boundary is market relevance. The paper measures stance classification, not asset-price prediction, trade profitability, portfolio performance, or event-study abnormal returns. A correct hawkish label does not automatically imply a profitable trade. Markets price expectations, surprises, positioning, liquidity, and the difference between what was said and what traders expected to hear. The model reads the text. It does not read everyone else’s positioning book.
The better product is not a braver model; it is a more cautious workflow
The obvious but wrong product pitch is: “LLMs can now decode the Fed.”
The better interpretation is: “LLMs can classify parts of Fed communication more accurately when given economic structure, and they can help identify when their own classifications are likely unreliable.”
That is a smaller claim. It is also the one worth building around.
A serious implementation would have at least four layers:
- Document segmentation: split speeches, minutes, and transcripts into units that preserve context rather than shredding meaning into isolated sentences.
- Mechanism extraction: identify economic entities, source attribution, causal links, conditional statements, comparisons, and transmission channels.
- Stance and uncertainty scoring: classify hawkish, dovish, or neutral, while assigning perceptual uncertainty.
- Governed routing: automate low-risk outputs, review high-risk outputs, and log reasoning paths for audit.
The final layer matters most. Without routing, uncertainty is just another number on a dashboard. With routing, it becomes a control surface.
For operators, this paper’s useful message is not that Fedspeak has finally been conquered. It has not. The useful message is that “confidence” can be operationalised. Not as swagger, not as a probability-shaped decoration, but as a decision rule: proceed, review, or abstain.
In central-bank communication, that is the difference between a model that merely speaks Fed and a system that knows when it should stop talking.
Cognaptus: Automate the Present, Incubate the Future.
-
Rui Yao, Qi Chai, Jinhai Yao, Siyuan Li, Junhao Chen, Qi Zhang, and Hao Wang, “Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths,” arXiv:2508.08001, 2025. ↩︎