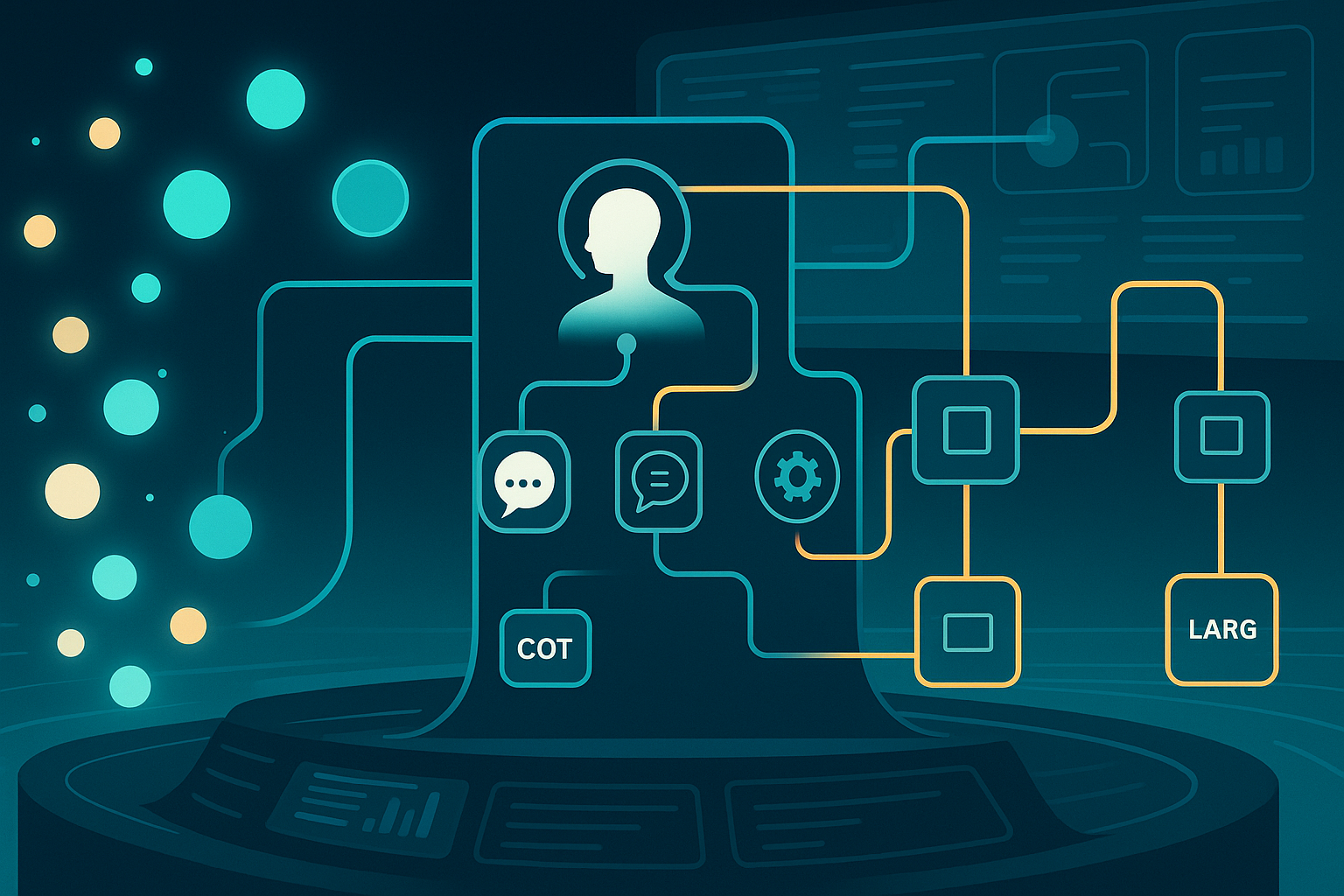
The punchline
Static multi‑agent pipelines are expensive on easy questions and underpowered on hard ones. DAAO (Difficulty‑Aware Agentic Orchestration) proposes a controller that first estimates the difficulty of each query, then composes a workflow (operators like CoT, ReAct, Multi‑Agent Debate, Review/Ensemble) and finally routes each operator to the most suitable model in a heterogeneous LLM pool. The result: higher accuracy and lower cost on suite benchmarks.
Why this matters (business lens)
- Spend less on routine queries. Easy tickets don’t need five agents and GPT‑Ultra—DAAO keeps them shallow and cheap.
- Don’t whiff on the edge cases. When the question is gnarly, DAAO deepens the DAG and upgrades the models only where it pays.
- Procurement leverage. Mixing open‑weights (Llama/Qwen) with commercial APIs lets you arbitrage price–performance per step.
What DAAO actually does
DAAO is three tightly coupled decisions per query:
- Difficulty Estimator (VAE): encodes the input and outputs a scalar difficulty $d\in[0,1]$.
- Operator Allocator (MoE‑style): chooses which operators to include and how many layers ($L=\lceil d\cdot\ell\rceil$).
- LLM Router: assigns each chosen operator to a specific model (temperature‑scaled softmax over query/operator/difficulty embeddings).
A pocket mental model
| Query signal | Workflow depth | Operators likely | Model mix (examples) | Cost intent |
|---|---|---|---|---|
| Clear, templated, short context | 1–2 | CoT or straight answer + light Review | Qwen‑2 7B/14B, Llama‑3.1‑8B | Minimize |
| Ambiguous with tool use | 2–3 | ReAct → Review/Ensemble | Llama‑3.1‑70B for planning, Qwen‑2‑32B for tool calls | Balance |
| Open‑ended reasoning or math/code | 3–5 | CoT → Debate → Self‑Consistency → Testing | gpt‑4o‑mini for final check; cheaper models for earlier hops | Maximize utility per $ |
The nuance is not just how deep, but which operator gets which model. CoT on Qwen‑72B might be plenty for algebra, while final verification prefers a model with stronger generalization.
How it compares to recent automation
| System | Granularity | Heterogeneous LLMs | Cost control | Typical failure mode |
|---|---|---|---|---|
| Task‑level pipelines (e.g., fixed AFlow‑like) | Per task | Rare | Weak | Over‑processing easy items |
| Query‑level supernets (e.g., MaAS‑like) | Per query | Limited | Moderate | Oversimplifies hard inputs |
| LLM routers (RouteLLM/MasRouter‑like) | Per query (model pick) | Yes | Good | Ignores operator/workflow selection |
| DAAO | Per query & per operator | Yes (per‑operator) | Explicit in objective | Requires good difficulty signal |
Core insight: Operator selection and model routing are joint decisions—decoupling them leaves money or accuracy on the table.
Evidence snapshot (interpreted)
- Across benchmarks (GSM8K, MATH, HumanEval, MBPP, MMLU, GAIA), DAAO reports +2.8% to +11.2% accuracy vs leading baselines while cutting inference spend to ~64% of prior multi‑agent systems.
- On GAIA’s tool‑heavy tasks, dynamic depth + per‑operator routing outperforms fixed DAGs and single‑model workflows—precisely where real ops live (browsing, file I/O, multimodal checks).
Implementation notes for Cognaptus stacks
1) Signals that predict difficulty
- Lexical/structural: length, entropy, numeric density, operator keywords (prove, derive, simulate, scrape).
- Contextual: retrieval hit dispersion, tool requirement hints, prior solve rate on similar tickets.
- Runtime: early‑exit probes (cheap model tries a sketch; confidence/consistency gates decide whether to escalate).
2) Operator inventory (start small)
- CoT, ReAct, Debate, Review, Ensemble, Self‑Consistency, Testing.
- Treat each as $O={\text{model},\text{protocol}}$. Version them like code:
[email protected],[email protected].
3) Routing policy
- Define cost weights per model (USD/1K tokens + latency SLO). Train a light router with temperature‑scaled softmax over (query‑emb, op‑emb, difficulty‑emb).
- Guardrails: max depth $\ell$, operator budget $P$ per layer, and a monotone escalator (can only go to pricier models if quality gates fail).
4) Feedback loop
- Log per‑operator win/loss, token/latency, and “would a shallower/cheaper path have sufficed?”
- Periodically refit the difficulty VAE using outcome‑adjusted targets (their clamp trick keeps the latent well‑behaved).
Minimal rollout plan (2 sprints)
- Sprint 1: Offline router using historic tickets; enact 2‑tier depth (shallow/deep) and 3 operators (CoT, ReAct, Review) across 3 models (cheap/open, mid, gpt‑4o‑mini). Target: >20% cost drop on easy class with flat accuracy.
- Sprint 2: Add Debate + Self‑Consistency, per‑operator model routing, and a QA Testing tail. Target: win rate +3–5% on hard class with sub‑20% cost delta.
Where it can break (and how to hedge)
- Mis‑scored difficulty → shallow pipeline on a hard case. Hedge: early‑exit probe with a calibrated confidence; if low, escalate depth.
- Router bias → over‑uses one model due to skewed training set. Hedge: regularize with usage caps & diverse replay.
- Operator bloat → fancy DAGs everywhere. Hedge: budgeted layer thresholding (accumulate scores until $P$), plus post‑hoc cost audits.
The strategic takeaway
DAAO turns “which agent?” into two decisions: what tactic (operator) and which model (router). Making both decisions conditional on difficulty is the lever that simultaneously improves correctness and trims spend. For teams building production assistants, this is the missing middle between naive routers and monolithic multi‑agent graphs.
—
P.S. If you want code pointers, we can sketch a minimal controller with SBERT embeddings, a two‑head MLP for difficulty + operator logits, and a compact routing head trained on past tickets. Start with two depths, three operators, three models, and instrumentation from day one.
Cognaptus: Automate the Present, Incubate the Future