The Takeaway
A new paper proposes TradingGroup, a five‑agent, self‑reflective trading team with a dynamic risk module and an automated data‑synthesis pipeline. In backtests on five US stocks, the framework beats rule‑based, ML, RL, and prior LLM agents. The differentiator isn’t a fancier model; it’s the workflow design: agents learn from their own trajectories, and the system continuously distills those trajectories into fine‑tuning data.
What’s actually new here?
Most “LLM trader” projects look similar: sentiment, fundamentals, a forecaster, and a decider. TradingGroup’s edge comes from three design choices:
-
Self‑Reflection that’s grounded in outcomes Instead of generic memory or RAG, agents pull labeled wins and losses from recent trades/predictions and prepend an “experience summary” before reasoning. That forces situational lessons (“why did we misread that pullback?”) into the next decision.
-
Style‑aware risk as a first‑class citizen A Style‑Preference Agent picks aggressive / balanced / conservative and pipes coefficients to a risk manager that sets dynamic take‑profit / stop‑loss from short‑horizon volatility. It also controls allocation (e.g., conservative buys at 50% size).
-
A data factory for post‑training Every agent’s prompt, CoT, action, PnL deltas, and evaluation labels flow into a distillation dataset. A small LoRA pass on Qwen3‑8B (≈0.53% trainable params, int8) then lifts the whole team’s performance—evidence that workflow → better data → better model is the right loop.
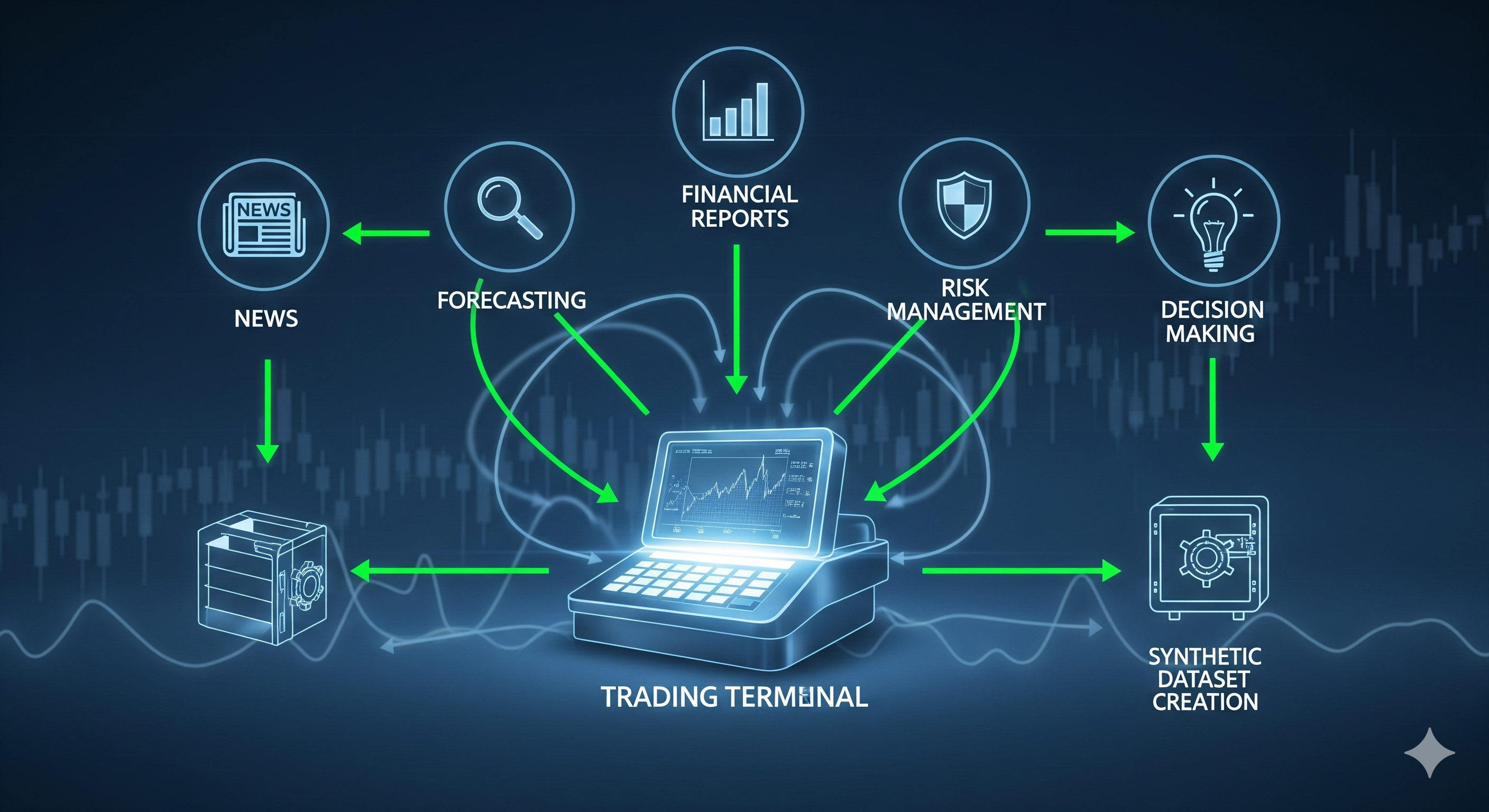
The agents & the gates (in plain English)
News‑Sentiment. Fetch, re‑rank (small reranker), deduplicate, then summarize into a market sentiment score. Financial‑Report. Hybrid retrieval on filings (dense+sparse), re‑rank to isolate price‑linked passages, then summarize “what matters” (guidance, margins, risks). Stock‑Forecasting. Classic features (RSI‑14, deviation from 20‑SMA, distance to 20‑day high/low, HV‑10, a simplified ATR‑20 proxy) combine with a hybrid gate:
- If RSI is hot and price hasn’t exceeded an ATR‑scaled breakout threshold, force “sideways” to avoid chasing tops.
- Else let the LLM’s up/down probs decide—but only if at least one bullish/bearish technical condition also fires.
Style‑Preference. Looks at recent performance and current account state to choose a style; this directly sets position sizing and risk thresholds.
Trading‑Decision. Aggregates everything, prepends an experience memo (good/bad cases), and issues Buy/Hold/Sell with rationale.
Evidence that the plumbing matters
The paper’s headline is not a magic indicator. It’s that self‑reflection + dynamic risk + curated distillation improves both returns and risk. In ablations, enabling the risk manager generally reduces drawdowns; adding reflection and retrieval quality improves returns without exploding volatility. A LoRA‑tuned Qwen3‑Trader‑8B (on the system’s own dataset) then outperforms the base model across all five tickers.
Strategic read: Your model family matters less than whether your agents write clean, label‑rich logs and use them to improve tomorrow’s prompts.
What Cognaptus should adopt (and how)
Below is a direct mapping from TradingGroup’s ideas to our stack (strategyr + tradesimr + agentr + okxr/binxr).
| TradingGroup idea | Why it works | Cognaptus implementation sketch | ||
|---|---|---|---|---|
| Outcome‑grounded self‑reflection for forecaster & decider | Prevents repeating recent failure modes; makes reasoning situational | In agentr, add ReflectionStore that writes: (inputs, CoT, action, PnL_delta, label). Before each decision, inject summarize_last_k_cases() with 2 good/2 bad analogs. |
||
| Hybrid gates around the LLM | Keeps “reasoning” inside risk‑aware bounds | In strategyr, expose gate_breakout_threshold = max(1%, 0.5 * ATR20%); clamp trend=sideways when RSI>70 yet < threshold; require at least one confirmatory pattern before accepting LLM up/down. |
||
| Style‑aware risk tied to account state | Turns “risk appetite” into math (size, SL/TP) | In tradesimr, add style_profile → sets cash allocation (1.0/1.0/0.5) and TP/SL = m_style * σ10d (unannualized). Trigger hard exits when |
PnL | crosses threshold. |
| Data‑synthesis → PEFT | Small, frequent fine‑tunes on your own trajectories | Nightly job writes JSONL of agent runs; keep only high‑quality (e.g., reward_a>0 or w_hit>0). Fine‑tune a compact model (e.g., 7–8B) with LoRA int8. |
||
| News/file reranking | Cuts noise; focuses on price‑relevant snippets | Use a tiny cross‑encoder (or even heuristic priors) to select “market‑moving” items; fall back to filings when news sparse. |
Pragmatic recipe (crypto‑perps, 4H/15m)
-
Indicators (vectorized):
RSI14,ATR20%(true ATR or the paper’s close‑to‑close proxy),dev20SMA%,distance_to_20d_high/low%,HV10%(unannualized for intraday). -
Gating rules:
- No‑chase clamp: if
RSI14>70and price <breakout_threshold = max(1%, 0.5*ATR20%)above 20d high → force sideways. - Soft pass: Allow LLM uptrend only if
p_up>τand either (a) new 20‑bar high or (b) dev20SMA within a healthy pullback band (e.g., 0 to −3%) withRSI<40. Mirror for downtrends.
- No‑chase clamp: if
-
Style & risk: map
aggressive/balanced/conservativeto size =1.0/1.0/0.5andm_tp, m_slmultipliers on σ(returns) over last N bars. -
Reflection windows: keep rolling
k=20decisions; label hits for forecaster (w_hitusing volatility‑scaled bands) and rewards for decider (reward_a = r_eq - β·r_bm - γ·cost). Surface two “what changed my mind?” bullets before each new action. -
Data discipline: store prompts, CoT, features, decisions, fills, PnL, labels every bar; nightly filter to high‑quality SFT samples.
Where I’m skeptical (and how we hedge it)
- Dataset & horizon: Results are on daily equities in a defined window; crypto perps with 15m/4H regimes are noisier and regime‑shift faster. Mitigation: shorten reflection windows; weight by recency and volatility regimes.
- News coverage gaps: Two symbols had little or no news; the framework still performs—suggesting gates carry the weight. That’s fine, but don’t over‑index on sentiment plumbing.
- “Simplified ATR”: using close‑to‑close stdev is fast but misses gap/true‑range dynamics; perps need true ATR on high/low for TP/SL realism.
- PEFT on synthetic labels: Great for alignment, risky for leakage/overfitting to your simulator. Keep a frozen test period and evaluate live‑paper every week.
- Baseline fairness: Some baselines are under‑tuned (common in papers). Judge the delta from your current bot, not absolute numbers.
Two‑week build plan (Cognaptus)
Week 1
- Implement
gate_*helpers and style‑aware risk instrategyr&tradesimr. - Add
ReflectionStorewith JSONL writes; wiresummarize_last_k_cases()into prompts. - Ship a minimal Forecaster → Decider loop for one perp (e.g., ETH‑USDT‑SWAP, 15m).
Week 2
- Start nightly data‑synthesis → PEFT (LoRA) on a small local model; keep only positive‑reward/hit samples.
- Add a micro news/file reranker (fallback to purely technical when sparse).
- Run paper‑trading with the new style+risk discipline and compare against your current agent.
Bottom line
TradingGroup’s contribution is less about inventing a new indicator and more about closing the loop: agents make decisions, label their own outcomes, reflect, and train on their best trajectories. Do that well, and even a modest base model becomes a sharper trader.
Cognaptus: Automate the Present, Incubate the Future.